1 背景介绍
1.1 传统反欺诈技术面临挑战
数字技术与金融业的融合发展,也伴随着金融欺诈风险不断扩大,反欺诈形势严峻。数字金融欺诈逐渐表现出专业化、产业化、隐蔽化、场景化的特征,同传统的诈骗相比,数字金融诈骗往往是有组织,成规模的,他们分工明确、合作紧密、协同作案,形成一条完整的犯罪产业链。传统反欺诈技术面临的三大挑战:维度单一、效率低下、范围受限。(引用自《数字金融反欺诈白皮书》)
1.2 图数据库技术应运而生
面对复杂的大数据,如何高效的从大规模数据中获取有价值的信息,传统技术面临巨大挑战。
图数据库这项新兴技术正是反欺诈的一把利剑,基于图数据库技术构建的关系图谱可用于深度数据挖掘,包括:关系推理、关联度检测、集中度测量、语义分析、团伙发现、可视化展示等。
本质上反欺诈面临的核心问题就是如何处理海量的用户关联关系。传统关系型数据库在处理海量关系上做得并不好,面对复杂关系网络的处理存在如下问题:数据规模大难以存储、计算效率低、关系建模难、维护性/易用性/扩展性差等。与传统关系型数据库不同的是,图数据库在处理关联关系上具有天生的优势,这些问题都能很好的一一化解。根据DB-Engines报告,从最近十年的表现来看图数据库已经成为关注度最高,发展趋势最明显的数据库类型。
HugeGraph图数据库就是在这个需求背景下应运而生的。
HugeGraph是百度安全面对反欺诈、威胁情报、黑产打击等业务自研的一款图数据库。HugeGraph通过多维度的特征检测(属性特征、关系特征)、关联度检测、团伙检测等技术来识别欺诈风险,提供了由点及面的反欺诈解决方案。
![]()
2 欺诈特征检测
根据用户的特征检测分析,我们可以对其进行风险度评分,特征检测主要包括如下几方面:
2.1 属性特征检测
· 信用记录(贷款、还款、逾期记录等)
· 匹配电话黑名单(公检法公开名单、数据联盟不良名单)
· 匹配诈骗地理位置(如诈骗中介、代办机构)
· 匹配代理服务器名单
· 检测信息造假或隐瞒:如学历、年龄、地址、公开简历、IP定位等。
2.2 关系特征检测
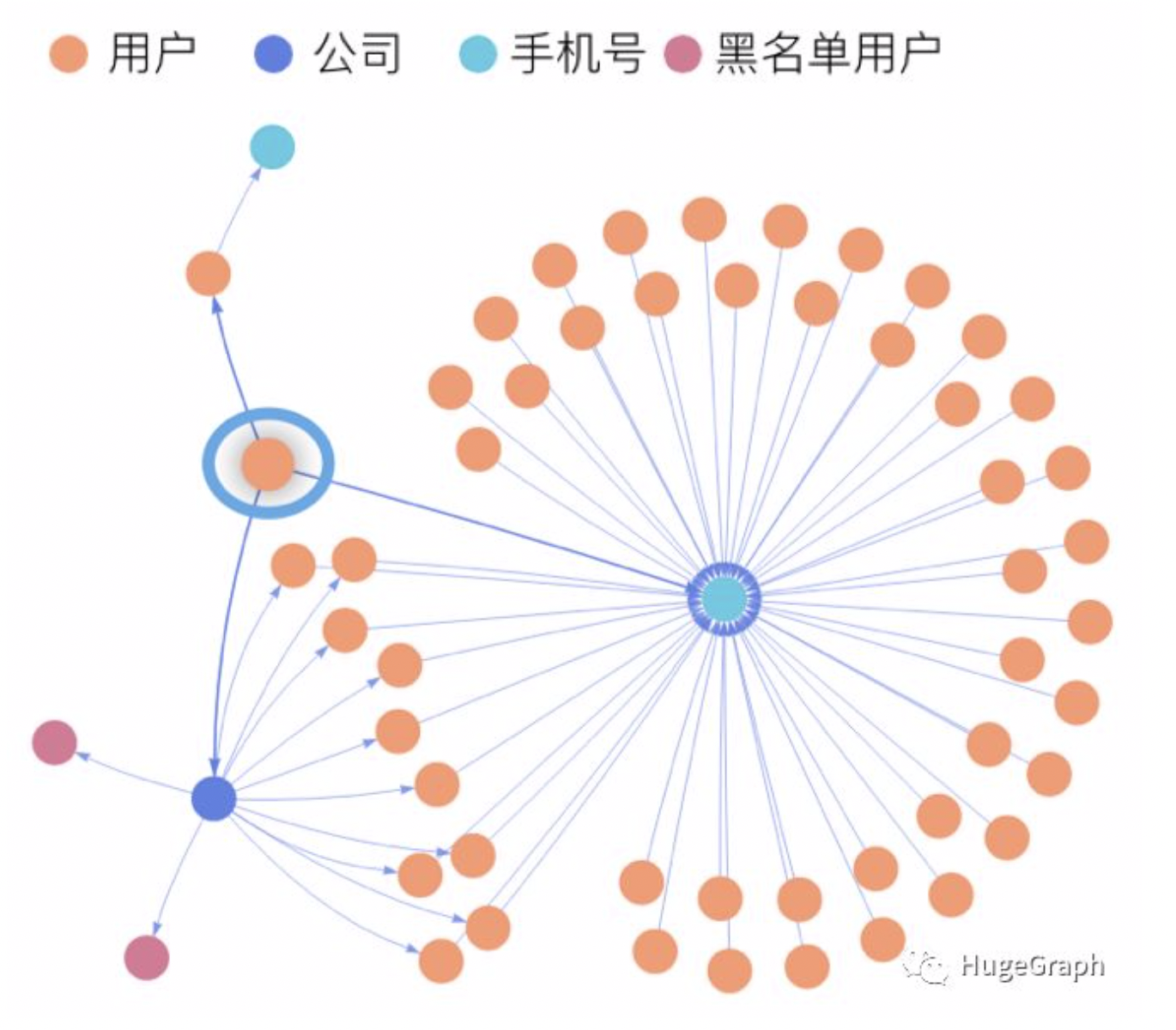
· 大量账户同时拥有同一个手机号
· 大量用户同时使用同一个手机或WiFi网络
· 同一个账号或设备在多平台申请借贷
· 自相矛盾关系检测,包括:用户填写的关系自相矛盾、用户公司地址自相矛盾、通话记录与职业自相矛盾等等
· 关系环路检测(比如检测是否有循环担保)
· 多层关系高度聚集性检测,比如大量账号通过大量虚假设备接入同一个网络
2.3 关联度检测
近朱者赤近墨者黑,通过用户的关系网络来检测其与风险节点的关联度,可识别出其风险程度并作为一个参考指标,比如某用户3度关系之内是否触黑。这个过程我们称之为关联度检测。
关联度检测的典型技术包括:
· 检测用户的多层社会关系是否符合正常的图谱特征,比如若是孤立的子图则可能是假造的关系网络,该用户存在高风险
· 检测多层关系网络中是否包含高风险节点,比如二度触黑
· 通过PersonalRank、PageRank等算法计算关系网络中节点的风险评分
其中高风险节点包括黑/灰名单、高风险评分节点等;关系网络是指实体(用户ID、账户、手机号、设备、地点)与各种关系(如通讯录、通话记录、转账交易、登录地点)之间的相互关联组成的网络。
3 欺诈团伙检测
3.1 使用社区发现算法检测欺诈团伙
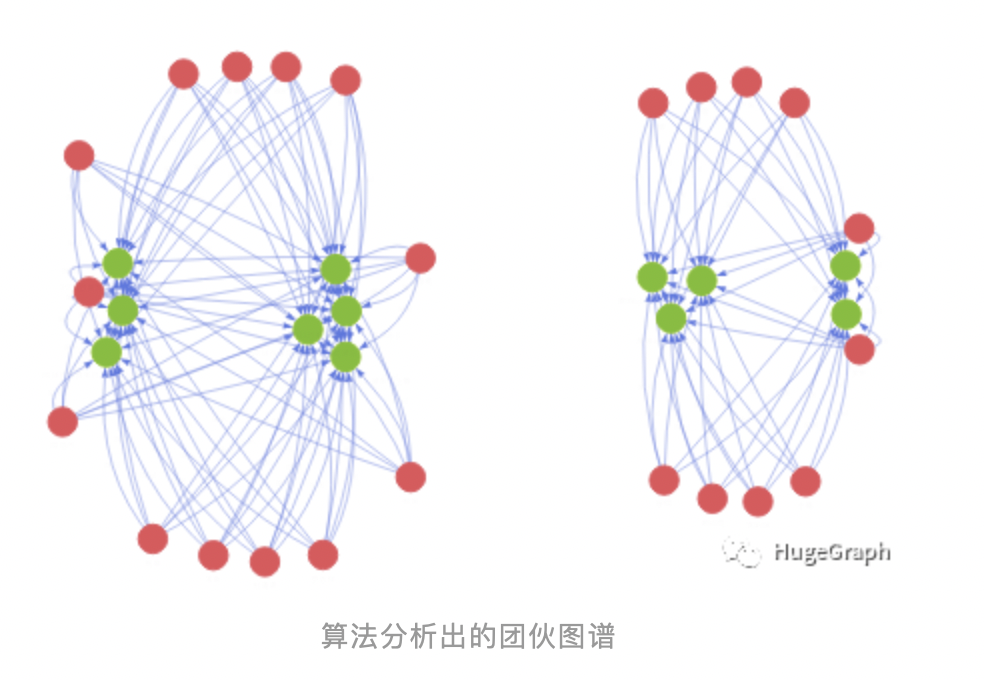
用户的关联关系是一个复杂的网络,对复杂网络的研究一直是许多领域的研究热点,其中社区结构是复杂网络中的一个普遍特征,同一个社区内的节点之间的连接紧密,而社区与社区之间的连接则比较稀疏。正如《数字金融反欺诈白皮书》所述,数字金融诈骗往往是有组织成规模的,如何找出这些组织本质上就是从复杂网络中找到一个一个的团伙并加以分析。
![]()
检测欺诈团伙的算法我们称之为社区发现算法(或者说社区聚类算法),社区发现是一个复杂而有意义的过程,近几年来,分析复杂网络中的社区结构得到了许多学者的关注,同时也出现了很多社区发现算法(如LPA、SCAN、Louvain等)。
在金融关系网络里面往往社交属性比较弱,大部分用户的社交关系很稀疏,找到关系紧密的社区就是发现欺诈团伙的关键,当然并不是所有的团伙都是欺诈团伙,因此有必要根据一个阈值来进行评判,比如根据前述欺诈特征检测出来各成员的风险评分,如果大于0.7分的用户在某团伙占比达到60%则判为欺诈团伙。
HugeGraph图数据库目前提供了两种社区发现算法:简单高效的标签传播算法LPA,以及基于模块度优化迭代算法Louvain。通过图的社区发现算法将用户划分为一个一个的群体(我们称之为团伙),然后根据团伙中各成员的风险评分综合计算整个团伙的风险程度,从而识别出高风险的欺诈团伙。
![]()
3.2 社区发现算法简介
LPA 算法简介
第一步:为所有节点指定一个唯一的标签;
第二步:逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
Louvain 算法简介
第一个阶段:首先将每个节点指定到唯一的一个社区,然后按顺序将节点在这些社区间进行移动。分别尝试将节点移动到相邻节点所在的社区,并计算相应的模块度变化值,哪个移动变化最大就将节点移动到相应的社区中去。按照这个方法反复迭代,直到网络中任何节点的移动都不能再改善总体模块度值为止。
第二个阶段:将第一个阶段得到的社区视为新的“节点”(一个社区对应一个),重新构造子图,两个新“节点”之间边的权值为相应两个社区之间各边的权值的总和,原社区内部边的权值之和作为新“节点”的权值。简单来说如果社区内部权值越大、社区之间权值越小,那么总体模块度就越大。
Louvain算法包含了一种层次结构,正如对一个学校的所有初中生进行聚合一样,首先我们可以将他们按照班级来聚合,进一步还可以在此基础上按照年级来聚合,两次聚合都可以看做是一个社区发现结果,就看想要聚合到什么层次与程度。
社区发现算法总结
LPA算法优势是算法简单,效率高;Louvain的优势是支持多层聚类,可以先把所有用户划分为小组,然后以小组为单位进一步聚类,划分为大组,以此类推,这样可以发现更大或者更为隐蔽的诈骗团伙。
未来,我们也将持续利用各种新技术、新手段、新模型,结合互联网业务风控场景的典型特征,探索更多行之有效的方法,应用到金融反欺诈中,相信很快,图数据库技术会发挥出更大的价值。