前言
上一篇写了推荐系统最古老的的一种算法叫协同过滤,古老并不是不好用,其实还是很好用的一种算法,随着时代的进步,出现了神经网络和因子分解等更优秀的算法解决不同的问题。 这里主要说一下逻辑回归,逻辑回归主要用于打分的预估。我这里没有打分的数据所以用性别代替。 这里的例子就是用歌曲列表预判用户性别。
什么是逻辑回归
逻辑回归的资料比较多,我比较推荐大家看刷一下bilibili上李宏毅老师的视频,这里我只说一些需要注意的点。
网络结构
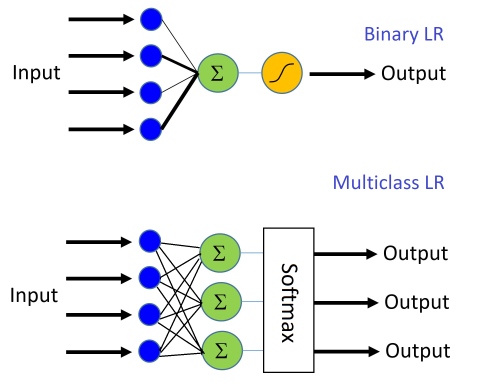
逻辑回归可以理解为一种单层神经网络,网络结构如图: ![]()
激活函数选择
逻辑回归一般选sigmoid或者softmax
- 图的上半部分就是二元逻辑回归激活函数是sigmoid
- 图的下半部分是多元逻辑回归没有激活函数直接接了一个softmax
别问我啥是sigmoid啥是softmax,问就是百度。
损失函数选择
损失函数逻辑回归常用的有三种(其实有很多不止三种,自己查API喽):
- binary_crossentropy
- categorical_crossentropy
- sparse_categorical_crossentrop 这里其实用binary更合适,但是我这里选的categorical_crossentropy,因为我懒得改了,而且我后面会做其他功能
梯度下降选择
梯度下降方式有很多,我这里选择随机梯度下降,sgd其实我觉得adam更合适,看大家心情了。至于为啥
数据准备
这次的数据是1万条KTV唱歌数据,别问我数据哪来的。问就是别人给的。
X是用户唱歌数据的one-hot
Y是用户的性别one-hot
下面是真正的技术
代码实现
- 数据拆分为 80%训练 20%测试
- 这里虽然只有两类但是还是用了softmax,不影响
- 训练工具是keras
数据获取
下面代码都干了些啥呢,主要是两个matrix。
一个是用户唱歌的onehot->song_hot_matrix。
一个是用户性别的onehot->decades_hot_matrix。 代码不重要,主要看字。
import elasticsearch
import elasticsearch.helpers
import re
import numpy as np
import operator
import datetime
es_client = elasticsearch.Elasticsearch(hosts=["localhost:9200"])
def trim_song_name(song_name):
"""
处理歌名,过滤掉无用内容和空白
"""
song_name = song_name.strip()
song_name = re.sub("【.*?】", "", song_name)
song_name = re.sub("(.*?)", "", song_name)
return song_name
def trim_address_name(address_name):
"""
处理地址
"""
return str(address_name).strip()
def get_data(size=0):
"""
获取uid=>作品名list的字典
"""
cur_size=0
song_dic = {}
user_address_dic = {}
user_decades_dic = {}
search_result = elasticsearch.helpers.scan(
es_client,
index="ktv_user_info",
doc_type="ktv_works",
scroll="10m",
query={
"query":{
"range": {
"birthday": {
"gt": 63072662400
}
}
}
}
)
for hit_item in search_result:
cur_size += 1
if size>0 and cur_size>size:
break
user_info = hit_item["_source"]
item = get_work_info(hit_item["_id"])
if item is None:
continue
work_list = item['item_list']
if len(work_list)<2:
continue
if user_info['gender']==0:
continue
if user_info['gender']==1:
user_info['gender']="男"
if user_info['gender']==2:
user_info['gender']="女"
song_dic[item['uid']] = [trim_song_name(item['songname']) for item in work_list]
user_decades_dic[item['uid']] = user_info['gender']
user_address_dic[item['uid']] = trim_address_name(user_info['address'])
return (song_dic, user_address_dic, user_decades_dic)
def get_user_info(uid):
"""
获取用户信息
"""
ret = es_client.get(
index="ktv_user_info",
doc_type="ktv_works",
id=uid
)
return ret['_source']
def get_work_info(uid):
"""
获取用户信息
"""
try:
ret = es_client.get(
index="ktv_works",
doc_type="ktv_works",
id=uid
)
return ret['_source']
except Exception as ex:
return None
def get_uniq_song_sort_list(song_dict):
"""
合并重复歌曲并按歌曲名排序
"""
return sorted(list(set(np.concatenate(list(song_dict.values())).tolist())))
from sklearn import preprocessing
%run label_encoder.ipynb
user_count = 4000
song_count = 0
# 获得用户唱歌数据
song_dict, user_address_dict, user_decades_dict = get_data(user_count)
# 歌曲字典
song_label_encoder = LabelEncoder()
song_label_encoder.fit_dict(song_dict, "", True)
song_hot_matrix = song_label_encoder.encode_hot_dict(song_dict, True)
user_decades_encoder = LabelEncoder()
user_decades_encoder.fit_dict(user_decades_dict)
decades_hot_matrix = user_decades_encoder.encode_hot_dict(user_decades_dict, False)
song_hot_matrix
| uid |
洗刷刷 |
麻雀 |
你的答案 |
| 0 |
0 |
1 |
0 |
| 1 |
1 |
1 |
0 |
| 2 |
1 |
0 |
0 |
| 3 |
0 |
0 |
0 |
decades_hot_matrix
| uid |
男 |
女 |
| 0 |
1 |
0 |
| 1 |
0 |
1 |
| 2 |
1 |
0 |
| 3 |
0 |
1 |
模型训练
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation, Embedding,Flatten
import matplotlib.pyplot as plt
from keras.utils import np_utils
from sklearn import datasets
from sklearn.model_selection import train_test_split
n_class=user_decades_encoder.get_class_count()
song_count=song_label_encoder.get_class_count()
print(n_class)
print(song_count)
# 拆分训练数据和测试数据
train_X,test_X, train_y, test_y = train_test_split(song_hot_matrix,
decades_hot_matrix,
test_size = 0.2,
random_state = 0)
train_count = np.shape(train_X)[0]
# 构建神经网络模型
model = Sequential()
model.add(Dense(input_dim=8, units=n_class))
model.add(Activation('softmax'))
# 选定loss函数和优化器
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 训练过程
print('Training -----------')
for step in range(train_count):
scores = model.train_on_batch(train_X, train_y)
if step % 50 == 0:
print("训练样本 %d 个, 损失: %f, 准确率: %f" % (step, scores[0], scores[1]*100))
print('finish!')
准确率测试集评估
数据训练完了用拆分出来的20%数据测试一下:
# 准确率评估
from sklearn.metrics import classification_report
scores = model.evaluate(test_X, test_y, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
Y_test = np.argmax(test_y, axis=1)
y_pred = model.predict_classes(test_X)
print(classification_report(Y_test, y_pred))
输出:
accuracy: 78.43%
precision recall f1-score support
0 0.72 0.90 0.80 220
1 0.88 0.68 0.77 239
accuracy 0.78 459
macro avg 0.80 0.79 0.78 459
weighted avg 0.80 0.78 0.78 459
人工测试
然后让小伙伴们一起来玩耍,嗯准确率100%,完美!
def pred(song_list=[]):
blong_hot_matrix = song_label_encoder.encode_hot_dict({"bblong":song_list}, True)
y_pred = model.predict_classes(blong_hot_matrix)
return user_decades_encoder.decode_list(y_pred)
# # 男A
# print(pred(["一路向北", "暗香", "菊花台"]))
# # 男B
# print(pred(["不要说话", "平凡之路", "李白"]))
# # 女A
# print(pred(["知足", "被风吹过的夏天", "龙卷风"]))
# # 男C
# print(pred(["情人","再见","无赖","离人","你的样子"]))
# # 男D
# print(pred(["小情歌","我好想你","无与伦比的美丽"]))
# # 男E
# print(pred(["忐忑","最炫民族风","小苹果"]))