传统大卖场营收持续下滑,必须通过业务创新走出困境
曾经风光无限的零售大型超市业态--大卖场,当初代表先进零售模式进入中国市场,激起零售行业蓬勃发展的大浪潮,但是近年来,随着人们消费方式的巨大转变以及来自电子商务的冲击,传统大卖场的发展发生逆转。传统的零售技术和模式已经无法满足顾客的需求,同时传统门店面临租金高,成本高,人流量减少等困境,亟需寻求新的发展。
以数字化改造为手段,提升大卖场精细化运营能力成为行业共识。面对新消费时代,商家可以借助大数据和人工智能等技术手段,快速从业务数据中找到业务特点,同时具备千人千面精准营销的能力,从而提升会购物体验,增强复购和会员粘性。数据中台是大数据时代的概念,大量的业务行为数据集中到数据中台做大数据分析,企业可对各类业务行为进行分析,给企业在营收、库存管理、商品管理等各个方面的决策提供数据依据。
D客户是中国连锁超市领军企业,年销售额过千亿,全国覆盖华东、华南、华中、东北、华北等多个大区,全国门店数四百家左右,单店平均面积在2万平米以上。近年来,在整个商超业绩下行的趋势下,D客户年度净利润保持百分之十几同比增长的同时,单店营收呈现负增长,所以几年前就启动了数字化改造,提升精细化运营能力,寻求新的发展。
为什么上云-数据分析效率低,影响业务分析与决策
D客户基于商品、会员、仓储、供应商、商户等业务行为产生大量的数据,基于这些数据要做大量的数据分析完成营收分析(成本、损耗、收入、价格等),库存管理(滞销、临保、缺货、周转率等),商品管理和商品竞争(淘汰、品类覆盖、价格指数等)。而D客户在IDC自建的大数据平台,数据吞吐量规模存在瓶颈,查询性能也不够理想,导致数据分析能力弱,效率低,影响业务分析与决策,如全年商品汰换率目标无法达成。
阿里云为企业大数据实施提供了一套完整的一站式大数据解决方案,覆盖企业数仓、商业智能、机器学习、数据可视化等多个领域,助力企业在DT时代更敏捷、更智能、更具洞察力。通过对客户现状的分析,推荐D客户使用的大数据产品MaxCompute有如下好处:
- 数据产生价值周期更快: 阿里云MaxCompute比自建的Hive 2.0+Tez快90%,使得数仓离线计算的数据处理时间不到原来自建方式的1/3。
- 托管服务免运维,让企业专注业务:最重要的是采用阿里云Maxcompute,客户将所有精力都放在业务上,节省了自建机房在学习成本、开发成本、管理成本、投入机房资源和运维成本的总成本,相比自建Hadoop物理集群,使用阿里云数加MaxCompute的总成本有较大降低,应用开发效率有很大提高。
- 开箱即用提升效率:基于阿里云数加MaxCompute提供的开放接口和各类工具,以及一站式的大数据开发套件,项目实施难度低,让开发者将精力全部放在数据处理、分析和应用上,极大的降低大数据应用开发的技术难度。
- 专业服务保驾护航:阿里云平台所提供的7×24小时技术支持服务则可以让客户随时随地获得专业的技术支持,让IT不再成为业务发展的限制。 依托于阿里云在安全性方面有全面考虑的底层平台和众多的安全监控工具,客户的各类应用数据即使放在云端也可以确保万无一失。
为什么上云-云下IDC资源利用率较低,部署冗余,人力支出高,资源弹性和扩展性不足
D客户通过在自建IDC服务器资源构建大数据平台,资源利用率不高,部署较为冗余,升级和维护困难,运维和基础设备开发人力支出成本比较高,而且随着自建IDC规模的扩大,企业成本大幅上升。
选择阿里云,可以按需使用云服务,无需人力维护物理设备,相对成本线性,实际TCO更低。
为什么上云-享受技术红利,提升效率
选择阿里云,阿里巴巴每年数百亿的研发投入带来的技术红利,云上即享。阿里云将达摩院机器智能技术实验室所有的智能技术,如智能语音、NLP、知识图谱、人脸识别、机器翻译等技术通过阿里云官网开放给用户,目前阿里云官网上大约有适用于300多个场景的130多个AI产品供用户使用。D客户上云后就尝试使用了阿里云智能推荐产品,阿里云智能推荐内置大量推荐算法以及模型训练的样本,训练深度、效率和准确率相比D客户原自建的推荐产品有很大的提升。
上云步骤与方案-丰富的解决方案,搬站工具和最佳实践使得企业上云周期短、切换影响小
阿里云拥有丰富的迁云工具和解决方案,截止2019年4月,阿里云官网已上线200+云产品、200+解决方案,100+上云最佳实践,帮助企业客户快速完成迁云方案评估,迁云实施和生产流量切换,全面提升企业业务的可靠性、安全性。
下面以D客户大数据平台上云切换为例介绍大数据上云步骤。
![TB1Gpd8vkT2gK0jSZFkXXcIQFXa-497-315.png]()
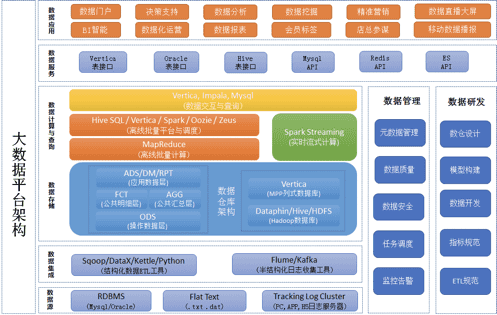
图1上云前架构示意图
图1为D客户在上云之前的大数据平台整体架构,大数据平台为自建IDC集群,规模在40+台,数据量近300TB(压缩策略为1:3),整体以Hadoop+Spark生态为架构,另外采购列式存储的MPP数据库Vertica作为上层应用依赖的核心数据库。
![TB1KNDvuubviK0jSZFNXXaApXXa-1492-806.png]()
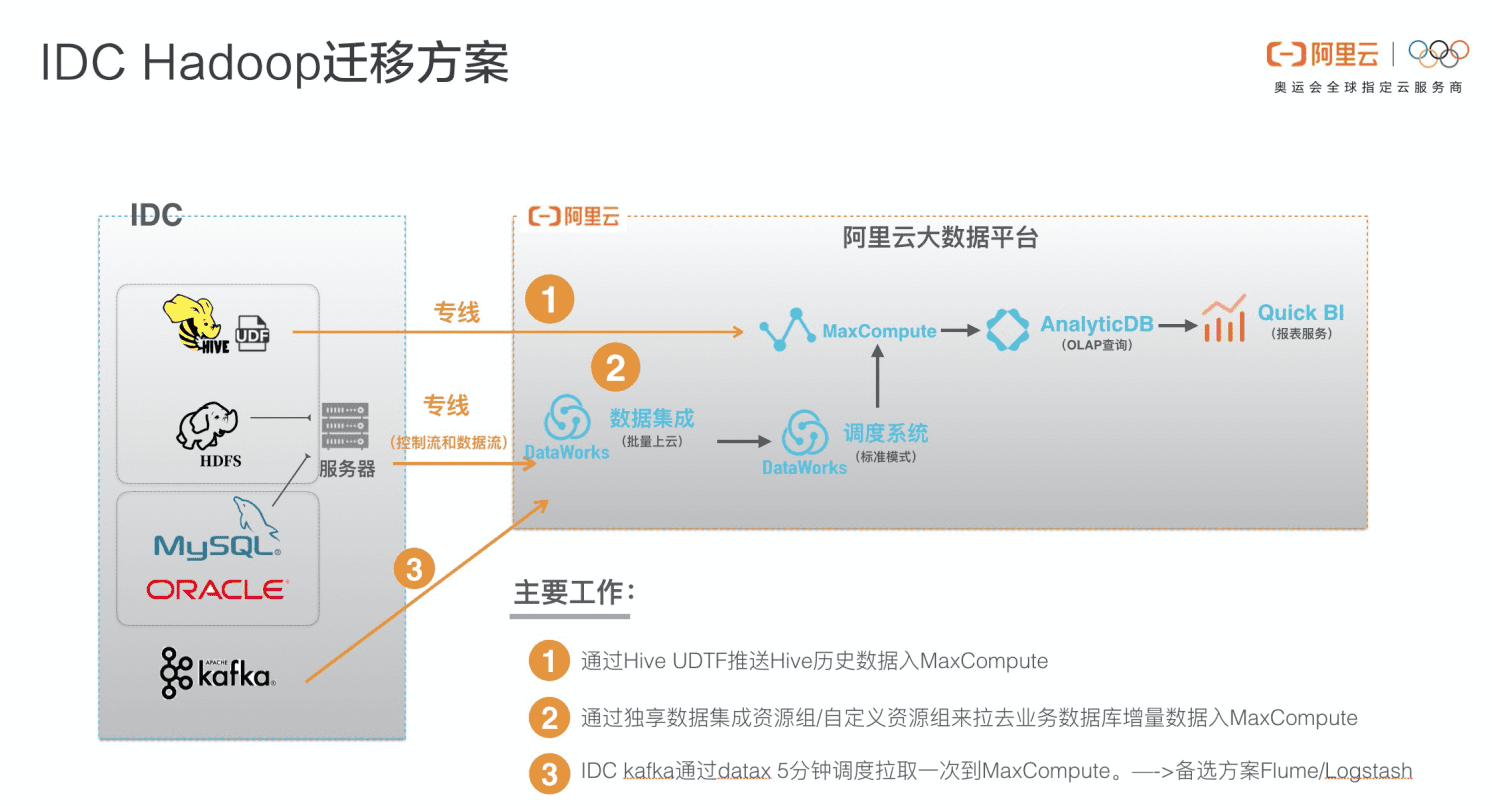
图2云上架构示意图
经历1月的POC测试后,D客户项目管理层最终决定,D客户数据中台基于阿里DataWorks+MaxCompute为主要核心来构建,最终解决方案如上图2所示。迁移方案具体说明如下:
- Hive历史数据(csv、txt、parquet、orc文件)通过MMA进行迁移。
- MySQL/Oracle业务数据通过DataWorks-数据集成/DataX进行增量方式拉入MaxCompute。
- Kakfa数据为日志数据,通过DataWorks -DataX脚本模式增量写入。
成熟的自动化迁移工具在本案例中起到至关重要的作用,大大缩短了迁移进程,并降低了迁移难度。以线下Hadoop的Hive数据迁移到云上MaxCompute为例,通过迁移工具MaxCompute Migration Assist(MMA)来加速迁移工作,如图3所示。
![TB1YBV1veT2gK0jSZFvXXXnFXXa-1492-810.png]()
图3 通过MMA迁移工具迁移Hive数据示意图
MMA的工作流程主要分为四个步骤:
- Metadata抓取
Meta carrier连接用户的Hive Metastore服务,抓取用户的Hive Metadata并在指定目录下生成一个目录,包含搬站所需的Metadata。用户可自行修改该目录下的文件来自定义搬站工具的一些行为。
- MaxCompute DDL与Hive UDTF生成
利用上述步骤抓取到的Metadata,生成另一个目录,包含用于创MaxCompute表和分区的所有的DDL语句,还包含用于数据迁移的Hive UDTF SQL。
- MaxCompute 表创建
运行上述批量生成的MaxCompute DDL,创建Hive迁移所需映射到MaxCompute的表与分区。
- Hive数据迁移
在用户Hadoop集群上运行上述步骤中所生成的Hive UDTF SQL,进行传输数据。需要注意的是,该UDTF是执行在用户Hadoop集群上,故需要关注到资源占用情况以及Hadoop集群到MaxCompute集群的网络连通性情况。
客户收益
- 通过大数据平台上云并建立数据中台,整合线上业务和渠道,线下门店和B2B渠道的数据,D客户形成9大数据主题域,建立战略决策、管理决策、门店运营的数据运营体系,为业务提供及时的数据决策支持,效率提升的同时保证商品汰换的效率和频度。
- 阿里云提供了完善的云上托管的数据处理方案、大规模计算储存、细粒度节点依赖管理等功能,D客户上云后,节省了30%的服务及人力成本。托管服务,无需对复杂作业进行运维,使企业更加专注于业务。
- 使用成本低,同时提供更高的数据吞吐量和查询性能,可视化编辑界面,方便操作,且与阿里云大数据产品生态融为一体。
- 电商平台相关单品推荐点击率提升70%到150%
附录
本案例涉及到的最佳实践列表: