初识DBFound+Springboot
Springboot+mybatis的组合,相信很多搞Java研发的工程师来说都非常熟悉,在实际项目中也是运用的非常广泛;但它不是今天的主角,今天我们来看看Springboot+dbfound的组合,会给我们带来哪些不一样的感受;dbfound是笔者2011年起草的一个持久层框架,1.0版本发布于2012年,目前最新版本2.4.1;
通常我们写一个业务功能,比如写一个查询用户表(sys_user)的接口功能;在Springboot+mybatis的组合中,我们通常要写 UserController.java、UserService.java、UserDao.java、User.java 和 UserMapper.xml这五个文件,来实现这个功能;代码层次分明、结构清晰,但略显繁琐,代码如下:
![]()
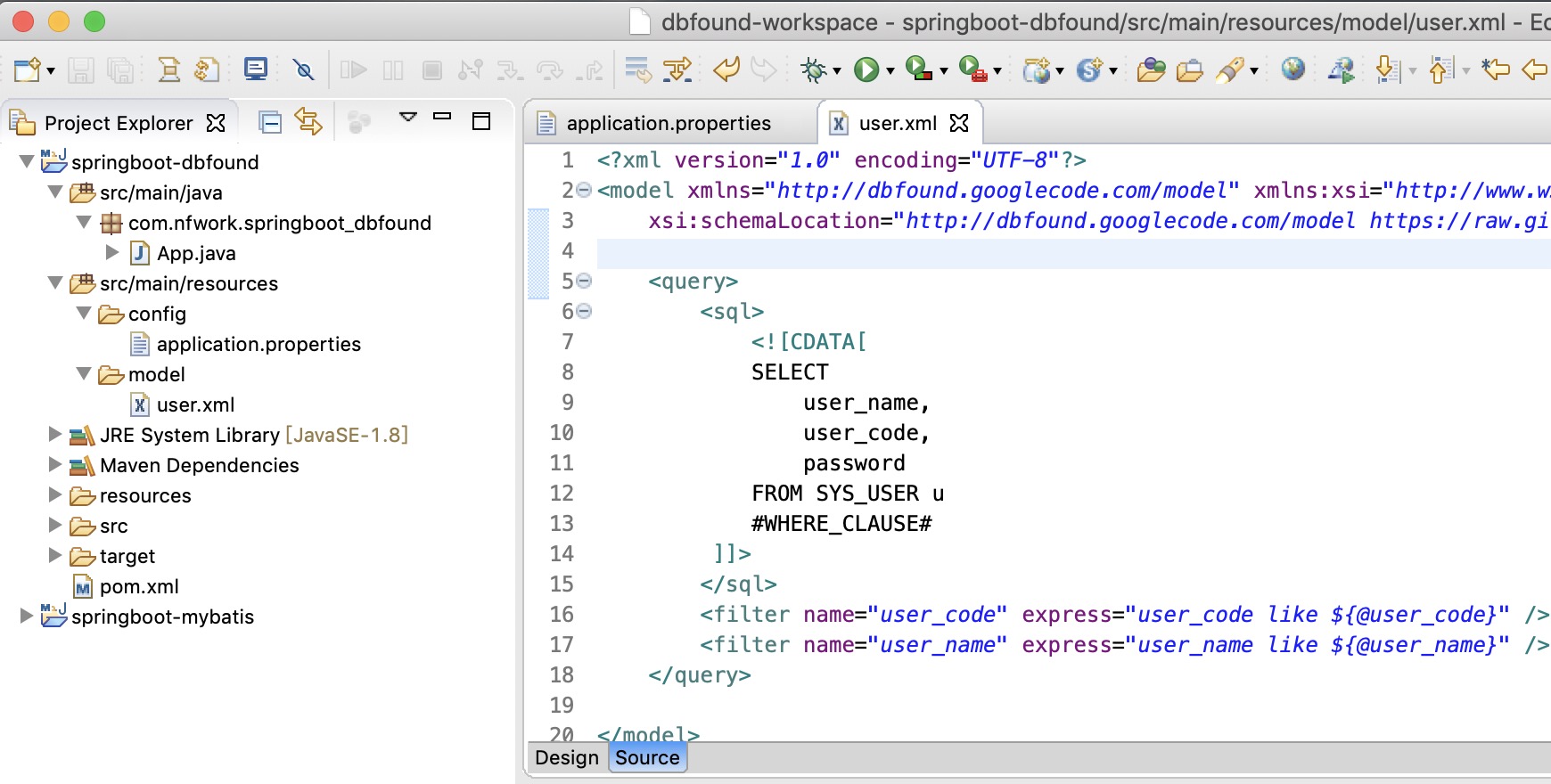
我们仅仅就是想实现一个查询功能而已,就需要些4个java + 1个xml文件才能实现;那有没有更简单快捷一点的方式呢?DBFound为快捷而生。下面我们看看用Springboot+dbfound组合,我们怎么去实现;我们只需要写一个xml文件(user.xml) 功能就已经完成了。如下图,我们只需要已xml为载体,把sql配置下,然后把xml放到springboot的容器中即可;
![]()
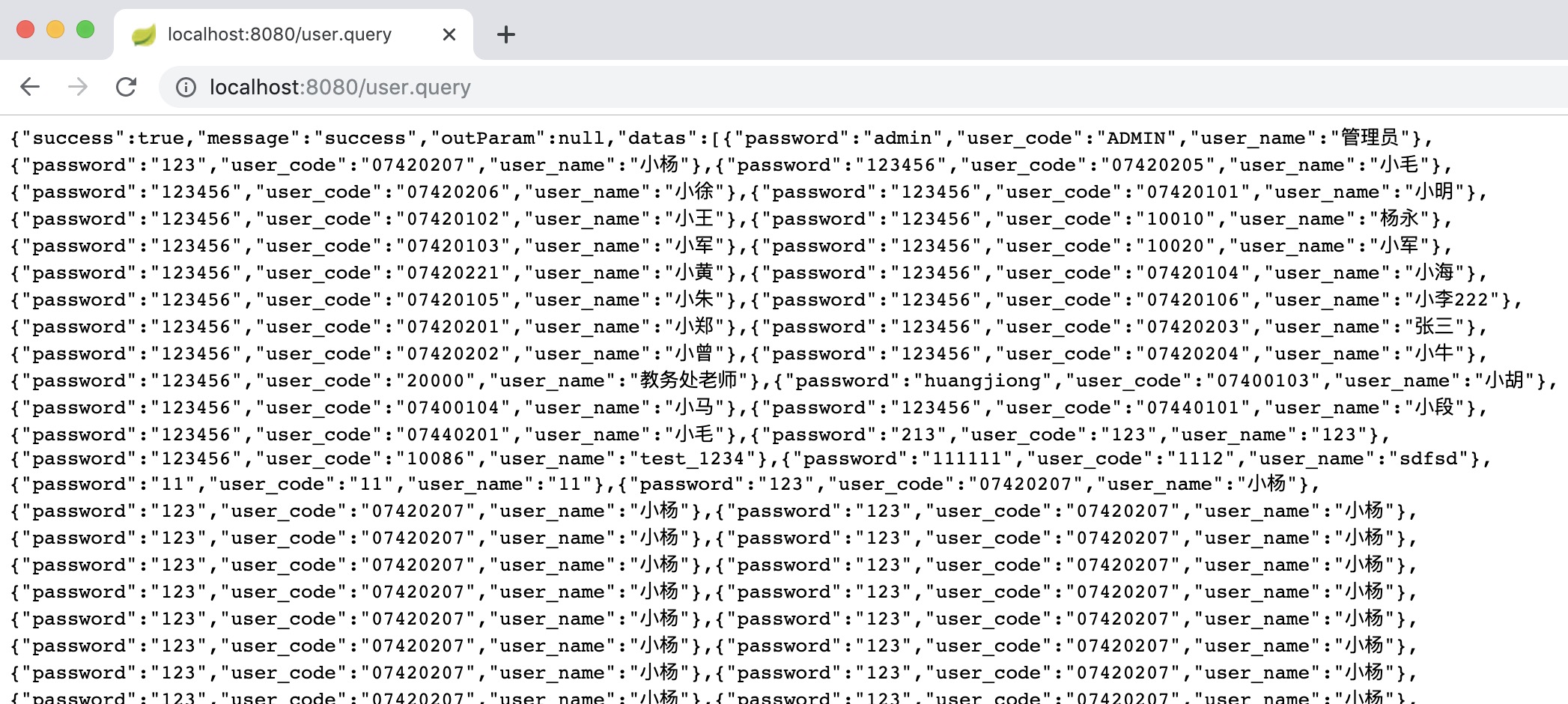
我们通过浏览器打开http://localhost:8080/user.query;就可以请求到model目录下的user.xml文件了;效果如下图,返回结果为一个json字符串;
![]()
我们还可以通过start和limit参数,来进行分页查询,如查询第10条到第20条 http://localhost:8080/user.query?limit=10&start=10 ; 我们的query对象中有两个<filter>标签,我们还可以传入user_name、user_code进行匹配查询 http://localhost:8080/user.query?limit=10&start=10&user_name=john ;
DBFound+Springboot环境搭建
搭建dbfound+springboot环境,也非常简单;
在创建一个springboot2.x的maven项目后,我们在pom.xml中加入dbfound-spring-boot-starter,如下:
<dependencies>
<dependency>
<groupId>com.github.nfwork</groupId>
<artifactId>dbfound-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>
其次在springboot的配置文件application.properties中,加入dbfound的配置,如下:
dbfound.datasource.db0.url=jdbc:mysql://127.0.0.1:3306/dbfound
dbfound.datasource.db0.username=root
dbfound.datasource.db0.password=root
dbfound.datasource.db0.dialect=MySqlDialect
最后就是编写model文件了,user.xml;默认情况下放在classpath下面的model文件夹下,如下:
<?xml version="1.0" encoding="UTF-8"?>
<model xmlns="http://dbfound.googlecode.com/model" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dbfound.googlecode.com/model https://raw.githubusercontent.com/nfwork/dbfound/master/tags/model.xsd">
<query>
<sql>
<![CDATA[
SELECT
user_name,
user_code,
password
FROM SYS_USER u
#WHERE_CLAUSE#
]]>
</sql>
<filter name="user_code" express="user_code like ${@user_code}" />
<filter name="user_name" express="user_name like ${@user_name}" />
</query>
</model>
model文件由<query>和<execute>两大组建构成,query对于select语句,execute对于insert、update、delete语句;这里就不多讲了,详情请参考之前写的《dbfound快速开发平台》文章中的介绍;
多数据源配置与事物管理
在实际的业务系统中,我们常常用到的不止一个数据源;在Springboot+mybatis组合中,原生配置是没办法做到多数据源的,必须要写代码实现;事物管理也是需要开发者去写大量的代码实现;但Springboot+dbfound中,这些麻烦事框架都给我们解决了。
首先我们在springboot配置文件application.properties中,加入多数据源配置; 注意这次我们多加了一个 provideName的属性,来区分不同的数据源;
dbfound.datasource.db0.provideName=database01
dbfound.datasource.db0.url=jdbc:mysql://192.168.1.111:3306/dbfound
dbfound.datasource.db0.username=jbjava
dbfound.datasource.db0.password=jb98
dbfound.datasource.db0.dialect=MySqlDialect
dbfound.datasource.db1.provideName=database02
dbfound.datasource.db1.url=jdbc:mysql://192.168.1.112:3306/dbfound02
dbfound.datasource.db1.username=jbjava
dbfound.datasource.db1.password=jb98
dbfound.datasource.db1.dialect=MySqlDialect
然后我们的model文件也需要做一点小的调整,需要在model标签中,多加了一个connetionProvide属性,与provideName一致即可:
<?xml version="1.0" encoding="UTF-8"?>
<model connectionProvide="database01" xmlns="http://dbfound.googlecode.com/model" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dbfound.googlecode.com/model https://raw.githubusercontent.com/nfwork/dbfound/master/tags/model.xsd">
<query>
<sql>
<![CDATA[
SELECT
user_name,
user_code,
password
FROM SYS_USER u
#WHERE_CLAUSE#
]]>
</sql>
<filter name="user_code" express="user_code like ${@user_code}" />
<filter name="user_name" express="user_name like ${@user_name}" />
</query>
</model>
在数据源的配置中,我们允许一个没有provideName的数据源,作为缺省数据源 与 model中没有指定connectionProvide的model文件 相互对应;我们通常建议db0不配置provideName,作为缺省。
事物管理方面,通过http直接访问model的情况,访问的execute对象默认加上了事物,当一个execute对象中执行了多条sql,会开启事物保证一致性;
<execute name="update">
<sqls>
<executeSql>
<![CDATA[
update table1
]]>
</executeSql>
<executeSql>
<![CDATA[
update table2
]]>
</executeSql>
</sqls>
</execute>
对于Java代码调用的情况下,使用@Transaction注解进行声明即可;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import com.github.nfwork.dbfound.starter.ModelExecutor;
import com.nfwork.dbfound.core.Context;
@Service
public class TestService {
@Autowired
ModelExecutor modelExecutor;
@Transactional
public void save(Context context) {
modelExecutor.execute(context, "user", "add");
modelExecutor.execute(context, "user", "update");
}
}
与SpringMVC的数据交互
熟悉dbfound的朋友都会知道,dbfound所有的参数都保存在Context;Context作为数据载体,model在执行的时候根据数据路径执行匹配,下一次单独写一个文章来说明Context数据交互;今天的重点,如何在springmvc如何获取Context呢?我们推荐了两种方式,方法如下:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.github.nfwork.dbfound.starter.ModelExecutor;
import com.github.nfwork.dbfound.starter.annotation.ContextAware;
import com.nfwork.dbfound.core.Context;
@RestController
public class TestController {
@Autowired
ModelExecutor modelExecutor;
@RequestMapping("query1")
public Object query(@ContextAware Context context) {
return modelExecutor.query(context, "user", null);
}
@RequestMapping("query2")
public Object query(String userName) {
Context context = new Context();
context.setParamData("user_name", userName);
return modelExecutor.query(context, "user", null);
}
}
model的调用API
框架提供了两种调用model文件的方式,一种是http,另外一种的javaapi;在讲api之前,我们先说明下三个重要的参数:modelName、queryName和executeName;我们通过modelName+queryName定位一个query服务,通过modelName+executeName定位一个execute服务;
当一个user.xml放在classpath/model目录下时,它的modelName就是user; 当一个function.xml放在classpath/model/sys目录下面时,它的modelName就是sys/function;
queryName和executeName在xml文件中指定;比如<query name="listAll"> 那他的queryName就是 listAll;modelName原理一样;一个model文件中,我们允许一个无名的query和execute;
http请求方式:
http://localhost:8080/user.query modelName是user,queryName为缺省;
http://localhost:8080/user.query!listAll 时queryName为!后面的内容,即listAll;
http://localhost:8080/user.execute modelName是user,executeName为缺省;
http://localhost:8080/user.execute!add executeName为add;
javaapi方式:
@Service
public class TestService {
@Autowired
ModelExecutor modelExecutor;
public Object query(Context context) {
Object object = null;
object = modelExecutor.queryList(context, "user", null); //modelName=user queryName为缺省 返回数据list<map>
object = modelExecutor.queryList(context, "user", "listAll"); //modelName=user queryName为listAll
object = modelExecutor.queryList(context, "user", "listAll", User.class); //modelName=user queryName为listAll 返回List<User>
object = modelExecutor.queryOne(context, "user", "listAll"); //modelName=user queryName为listAll 返回 Map
object = modelExecutor.queryOne(context, "user", "listAll", User.class); //modelName=user queryName为listAll 返回 User
object = modelExecutor.query(context, "user", "listAll"); //modelName=user queryName为listAll 返回QueryResponseObejct带总行数
object = modelExecutor.query(context, "user", "listAll", User.class); //modelName=user queryName为listAll 返回QueryResponseObejct<User>带总行数
return object;
}
@Transactional
public void save(Context context) {
modelExecutor.execute(context, "user", null); //modelName=user executeName为缺省
modelExecutor.execute(context, "user", "update"); //modelName=user executeName为update
//context保存userlist到param.userList; context.setParamData("userList", list);
modelExecutor.batchExecute(context, "user", "update","param.userList"); //modelName=user executeName为update 数据执行路径为param.userList
}
}