前言
作为全球第二大的代码托管平台,Gitee 拥有350W 用户和 600W 存储库,海量的存储库对 Gitee 的硬件设施提出了更高的要求,以 600W 存储库为例,如果按照平均 1GB 的大小磁盘体积,这些存储库将需要总共 5860 TB 的空间,按照 Gitee 每台存储磁盘 14TB,则需要 419 台存储设备。实际上在 Gitee 中,绝大多数存储库的体积都小于 100 M,超过 100 M 的存储库通常都是未合理使用 git。尽管如此,Gitee 仍然需要投入大量的存储设备来支撑用户的接入。为了能够让更多的人能够免费使用 Gitee,我们迫不得已只能限制大存储库的访问。近期,Gitee 存储库路由架构改造第一阶段已经到了收尾截断,在此期间,我们将陆续将服务端的钩子切换到 GNK (Gitee Native Hook),GNK 基于 C++ 编写,使用了 Git 环境隔离等高级特定,意味着大文件检测和存储库体积检测不会再有漏网之鱼。一些用户的存储库体积已经超过了 Gitee 配额限制,而之前的钩子检测存在缺陷,无法实时拦截大存储库和大文件,当切换到 GNK 后,这些用户修改他们的存储库却无法推送到 Gitee,这让他们产生了困扰,本文就这一困扰解答若干问题。当然如果用户有其他问题也可以在本文下留言。
Gitee 套餐信息
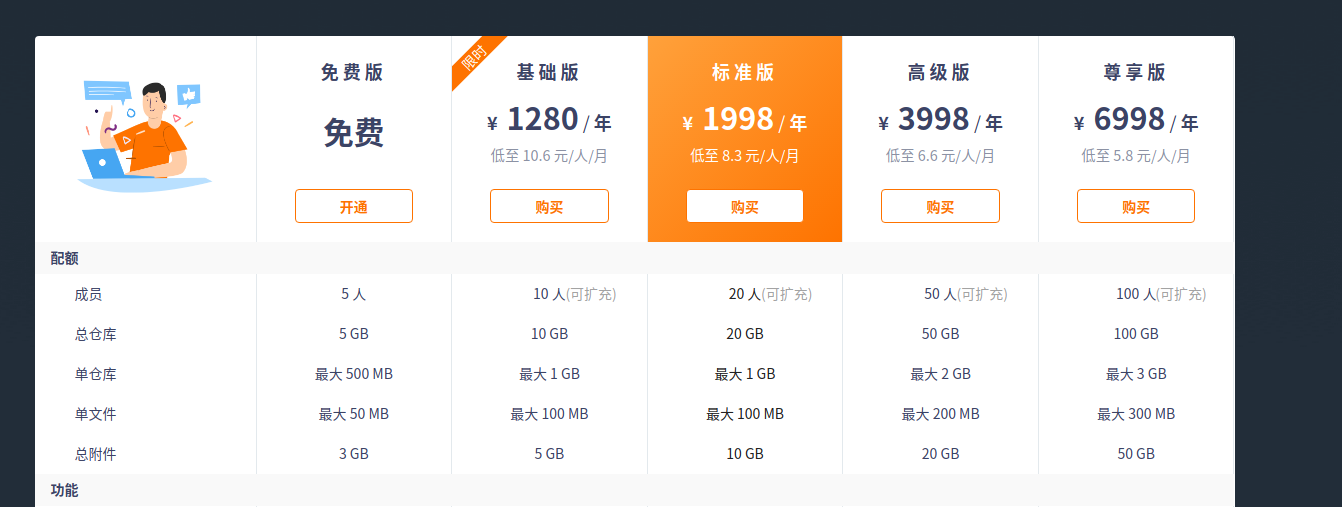
Gitee 分为普通用户,和企业用户,个人的套餐实际和企业免费版一致,最新的套餐信息 如下: ![]()
大存储库的产生
Git 是基于文件快照的,但并不是所有时候都存储快照,当对象被打包到 .pack 文件中时,则有可能存储对象的差异,即 OBJ_OFS_DELTA/OBJ_REF_DELTA。这种机制使得在文件大小不变的情况下,每次修改文件都会导致存储库体积按大于文件压缩后体积增长,以一个 Zip 压缩文件为例,每次修改后大小为 50 MB,提交 20次便能够超过 1000 MB。当用户将项目中的构建文件诸如 .exe,.pdb,.so,.jar 或者依赖文件/文件夹 node_modules,packages 以及资源文件 .psd,.raw,.avi,.jpg 添加到版本控制中后,很容易使得存储库体积超出限制。
大文件除了容易让存储库超出限制,而且也会降低用户拉取代码的体验,git 在处理二进制文件时需要花费更多的 CPU。
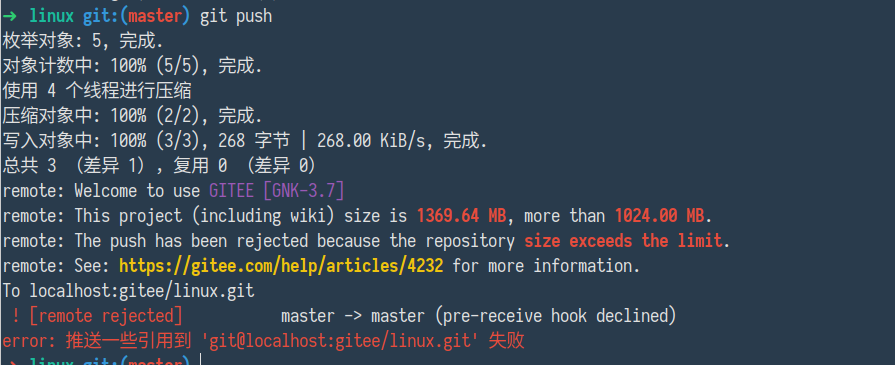
GNK 的拦截
随着存储服务器陆续切换到 GNK,超出配额的报告也可能会更多。GNK 的拦截是实时的,即用户将代码推送到服务器后,git-receive-pack 将调用 GNK 中的 pre-receive 钩子,这个钩子将统计存储库的 objects 目录,将所有文件和目录所占用的磁盘空间大小累加就获得了存储库的体积,这和 du -sh 机制一致,特别的,我们这里说的存储库体积包含其附带的 wiki 存储库的目录,这也是为了避免个别用户使用 wiki 存储大文件。
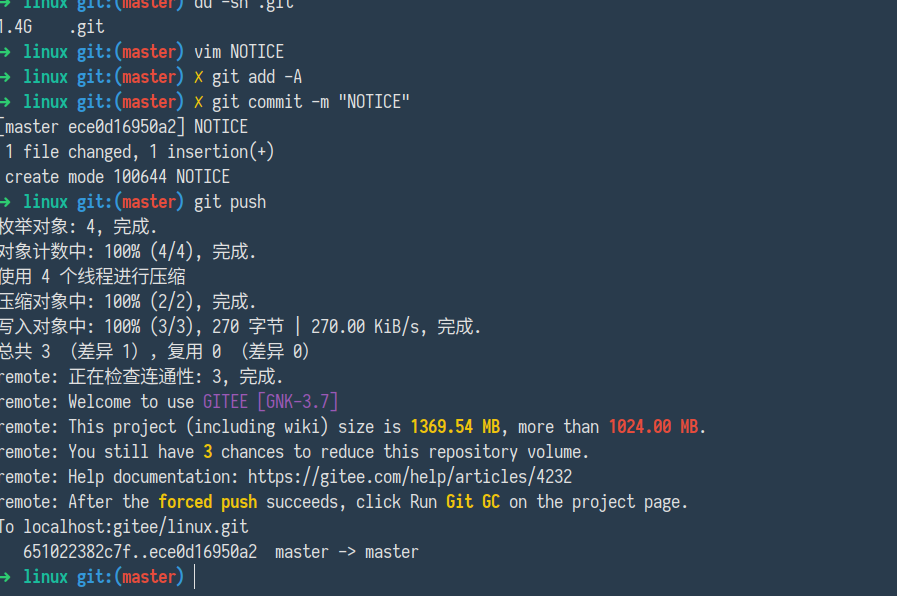
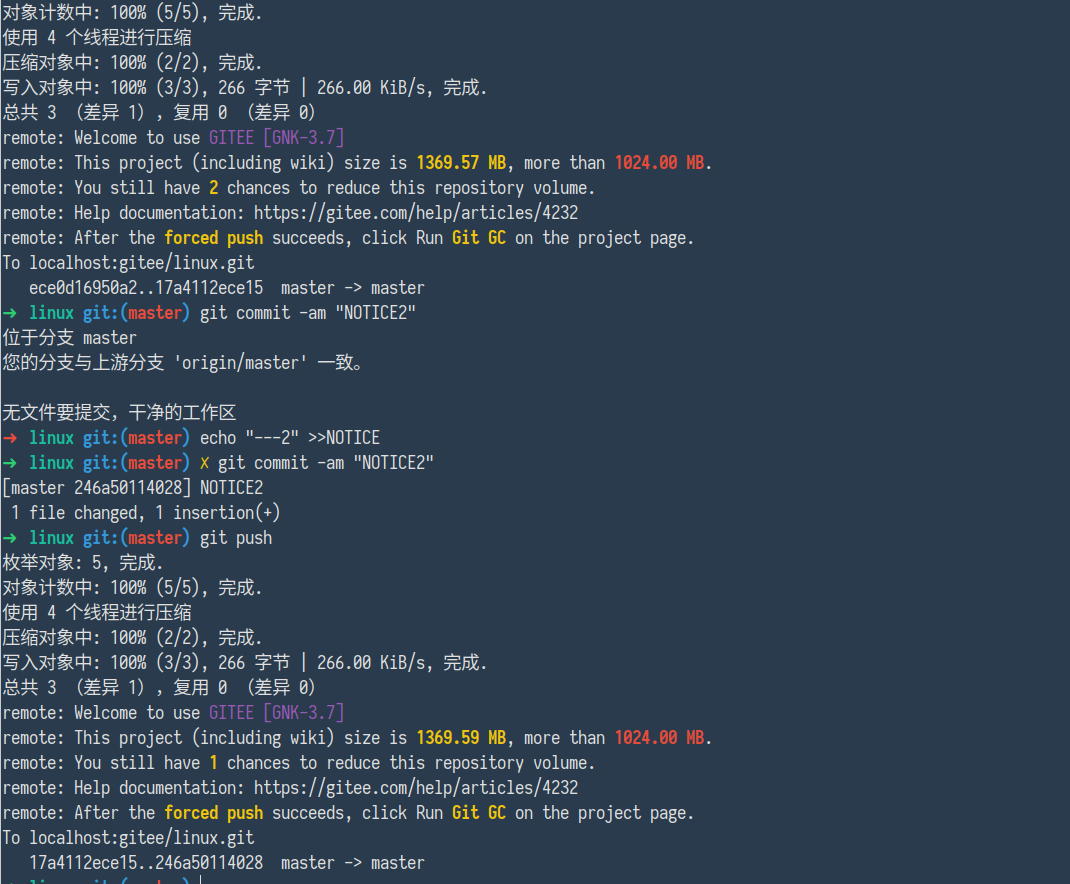
GNK 目前会给大存储库推送提供三次机会,如果三次读没有减小存储库体积,则便无法继续修改远程存储库,以 Linux 内核 1.4 G 为例,如下所示:
![]()
![]()
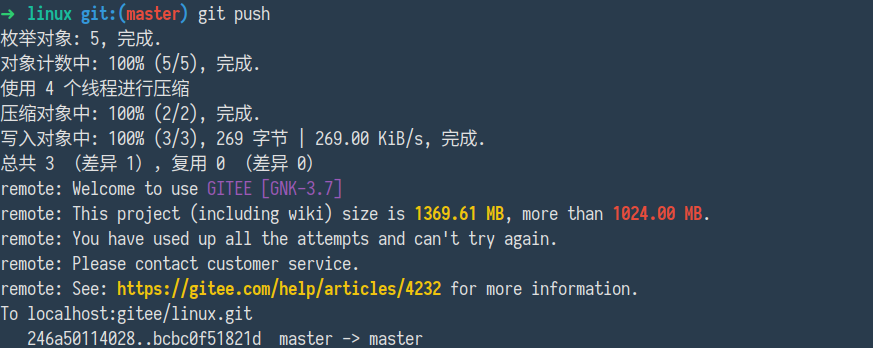
第三次时如果存储库体积依然超出限制,则会告知用户,已经耗尽所有机会,无法重试。
![]()
无法尝试时,输出如下:
![]()
GNK 还会拦截用户推送的大文件,但已经存在于存储库的大文件,GNK 不会去检测。基于 Git 环境隔离机制实现的 GNK,拦截大文件不会像之前一样反复推送大文件失败导致存储库体积变大,环境隔离目录在 pre-receive 执行失败后会被删除。
存储库的精简方案
在开发的时候,我们可以使用包管理工具管理项目依赖,比如 dotnet core 使用 NuGet,Java 使用 Maven,完全没有必要将依赖二进制纳入版本控制。
如果不慎将大文件纳入了版本控制中,可以去访问 Gitee 帮助:仓库体积过大,如何减小?。在修改本地存储库后,通过 git push -f 的方式推送到 Gitee,然后在项目配置页面运行 Git GC 待 GC 运行后,通常能够发现存储库体积变小。
如果项目使用 PR 机制参与协作开发,强制推送后运行 git gc 可能不会减小存储库的体积(这是因为存储库需要使用内部引用保持 PR 相应的 commit 的可用性,不被 GC),这个时候用户可以升级套餐,获得更大的存储库容量,或者在 Gitee 上新建一个空存储库,将修改历史记录的存储库推送到新的存储库。使用新的存储库即可。
一些大文件无法用版本控制可以将其使用 Git LFS 管理,用户需要使用 Git LFS 可以查看 Gitee LFS。
对于一些用户由于疏忽已经用完重试次数则可以联系官方团队重置重试次数
最后
无论如何,给用户带来困扰,我们很抱歉,但 Gitee 也是需要不断改进,不断的完善。随着 GNK 迁移完成和前端切换,Gitee 的路由架构改造第一阶段也将完成,这使得用户改名,存储库改名,存储库忽略大小写,fork 能够更容易实现或者更加快速。