常用的表格数据存储文件格式——CSV,Microsoft Excel,Google Excel 。
![]()
Python通常称为粘合语言。这个名称归因于人们逐渐开发出的大量接口库和特征,也得益于广泛的使用和良好的开源社区。这些接口库和特征能直接访问不同的文件格式,还可以访问数据源如数据库、网页和各种API。
本文的学习内容:
从谷歌表格中提取数据
- 从CSV文件中提取数据
- 从Excel文件中提取数据
本文适用于以下读者:
由于本文附有代码,建议处在开发环境之下(建议使用JupyterNotebook / Lab),并建立一个新的笔记本。
源代码和文件:https://github.com/FBosler/Medium-Data-Extraction
解决方法
本文将带你进入一个虚构但却可能异常熟悉的场景。你可以结合不同的数据来源去创建报告或进行分析。
注意!!!下面的示例和数据纯属虚构。
假设,你的任务是搞清楚如何提高销售团队的业绩。假设潜在的客户有相当自发的需求。这种情况发生时,销售团队将订单导入系统。然后,销售代表们会在订单交付时安排一个会议。具体日期有时在交付期之前,有时在交付期之后。你的销售代表有一笔费用预算,会在开会期间支付餐费。他们负责报销这笔费用,并将发票交给会计团队处理。在潜在客户决定是否要接受报价后,销售代表会跟踪订单是否达成。
可使用以下三个资料来源进行分析:
- 100,000 份订单 (Google表格)
- 约50,000张餐费发票(Excel文件)
- 负责公司及销售代表名单(CVS文件)
获取谷歌表格数据
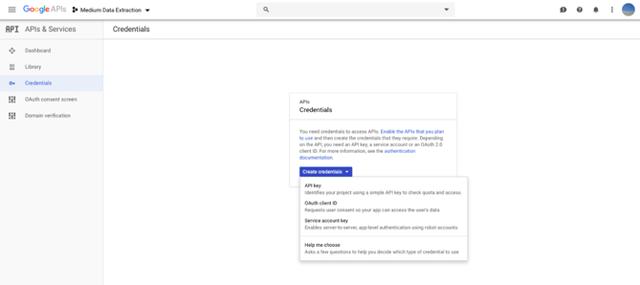
访问谷歌表格是这三种方法中最复杂的,因为你需要在使用谷歌表格API前设置一些证书。理论上,你可以获取一个公开可用的谷歌表(即提取源HTML代码)但必须使用Beautiful Soup之类的工具进行大量数据操作,才能将HTML转储转换为有用的内容。我确实尝试过,但是结果很糟糕,不值得一试。所以,API就是如此。此外,还将使用gspread无缝转换数据分析DataFrame。
获取OAuth2证书
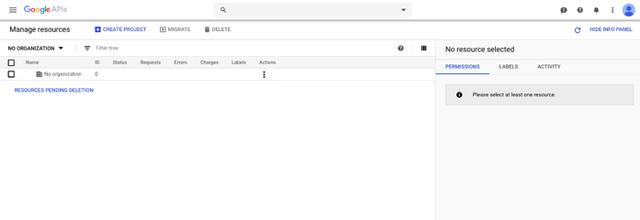
前往谷歌开发人员控制台,创建一个新项目(或选择现有的项目)。点击“创建项目”。如果公司使用谷歌邮件,可将其更改为私人帐户,以避免潜在的权限冲突。
![代码详解:使用Python从不同表格中提取数据]()
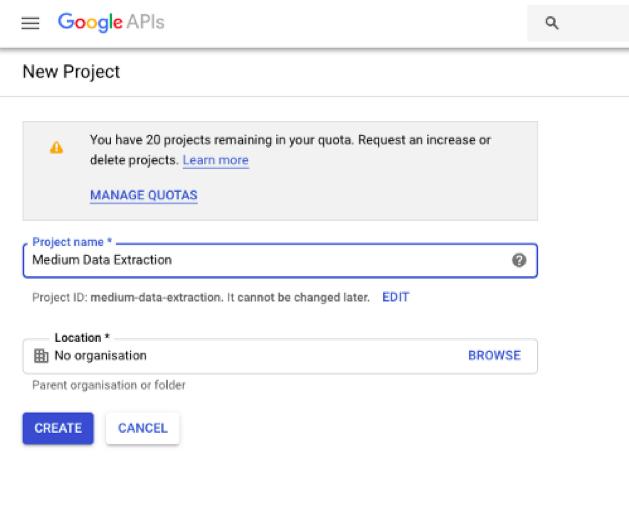
为项目命名(名称无关紧要,此处将其命名为媒体数据提取)。
![代码详解:使用Python从不同表格中提取数据]()
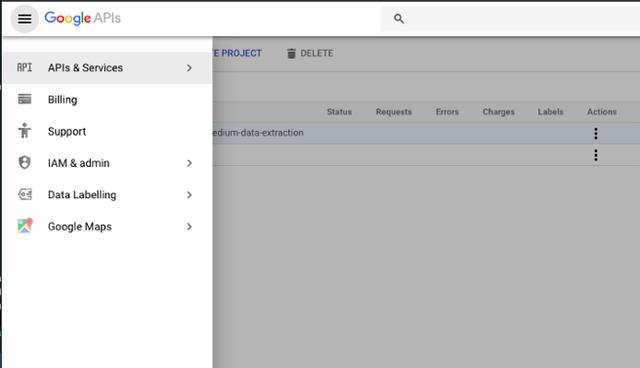
点击APIs & Services ,前往library。
![代码详解:使用Python从不同表格中提取数据]()
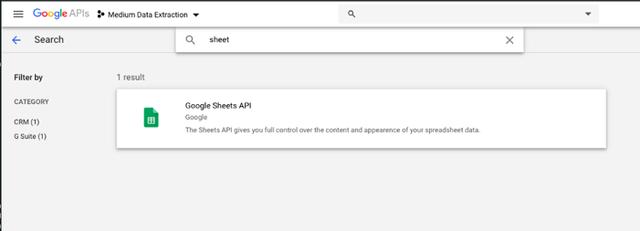
启用谷歌Sheets API。单击结果,并在如下页面上单击启用 API。
![代码详解:使用Python从不同表格中提取数据]()
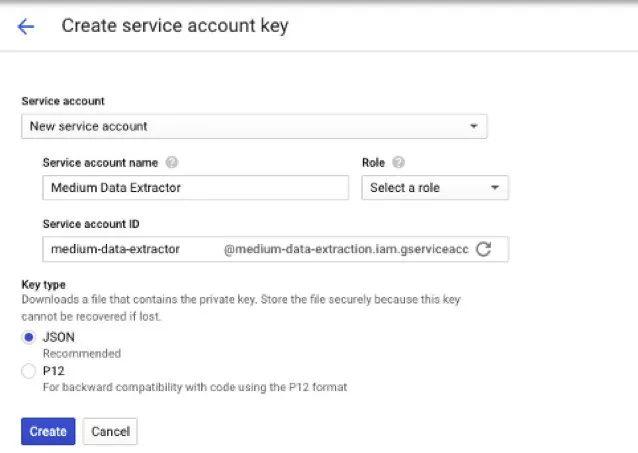
创建一个服务帐户和密钥文件。服务帐户是用于程序访问的专用帐户,访问权限有限。服务帐户可以而且应该通过有尽可能多的特定权限项目进行设置,当前的任务也需要如此。
![代码详解:使用Python从不同表格中提取数据]()
创建JSON(另一种文件格式)密钥文件。在角色上,选择“Project -> Viewer”。
![代码详解:使用Python从不同表格中提取数据]()
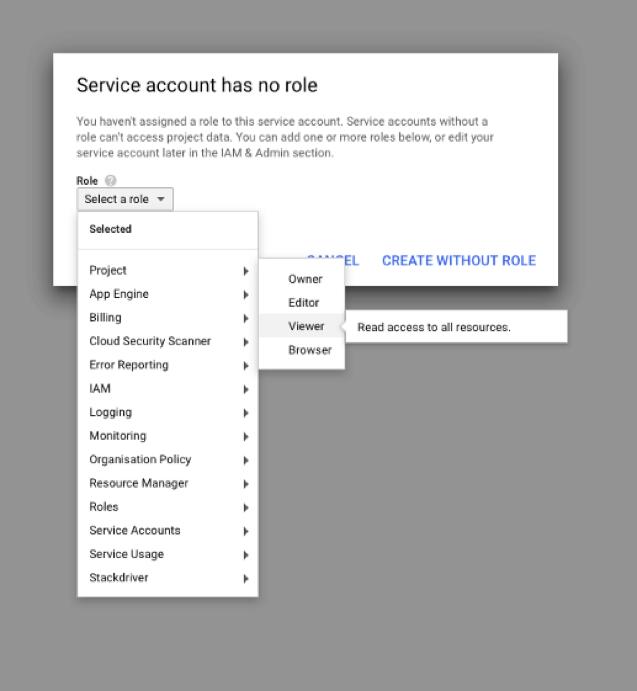
如果还没有在前面的步骤中设置角色请立即设置。
![代码详解:使用Python从不同表格中提取数据]()
注意:设置为“Viewer”会存在一些限制。如果希望以编程方式创建谷歌表格,则必须选择不同的设置。
然后,私有JSON密钥文件就可以下载或自动下载了。建议将该文件重命名为'Medium_Data_Extraction_Key,并将文件移动到JupyterNotebook文件夹中,以便与下面的示例无缝衔接。JSON文件包含最近创建的服务帐户证书。
非常好,就要成功了。
下载数据
首先,必须下载并安装其他软件包,在笔记本中运行以下命令。
!pip install gspread
!pip install oauth2client
其次,如果还没有移动密钥文件的话,必须确保将之前创建的JSON密钥文件移动到目前运行的木星笔记本(Jupyternotebook)文件夹中。或者,可以指定一个不同的GOOGLE_KEY_FILE路径。
- from oauth2client.service_account import ServiceAccountCredentials
- import gspread
- import pandas as pd
- scope = [
- 'https://www.googleapis.com/auth/spreadsheets',
- ]
- GOOGLE_KEY_FILE='Medium_Data_Extraction_Key.json'
- credentials = ServiceAccountCredentials.from_json_keyfile_name(GOOGLE_KEY_FILE, scope)
- gc = gspread.authorize(credentials)
- wokbook_key ='10HX66PbcGDvx6QKM8DC9_zCGp1TD_CZhovGUbtu_M6Y'
- workbook = gc.open_by_key(wokbook_key)
- sheet = workbook.get_worksheet(0)
- values = sheet.get_all_values()
- sales_data = pd.DataFrame(values[1:],columns=values[0])
- WORKBOOK_KEY是为本章内容准备的谷歌表格的工作簿id。
- WORKBOOK_KEY = '10HX66PbcGDvx6QKM8DC9_zCGp1TD_CZhovGUbtu_M6Y'
这份工作簿是公开的,如果想下载不同的数据,需要更改WORKBOOK_KEY。URL有问题的话,id通常可以在谷歌表格的最后两个反斜杠之间找到。
获取CSV数据
可以从repo以传统方式下载CSV数据,也可以使用以下代码片段进行下载。同样地,可能需要在笔记本上安装并运行缺失的请求包:
- !pip install requests
- import requests
- url ='https://raw.githubusercontent.com/FBosler/Medium-Data-Extraction/master/sales_team.csv'
- res = requests.get(url, allow_redirects=True)
- withopen('sales_team.csv','wb') asfile:
- file.write(res.content)
- sales_team = pd.read_csv('sales_team.csv')
CSV数据的美妙之处在于Python /panda可以立即进行处理。Excel则需要额外的库。
获取Excel数据
在开始之前,很可能还要安装openpyxl和xlrd,这能让Pandas也可以打开Excel表。
!pip install openpyxl
!pip install xlrd
完成这些步骤之后,可以相同的方式获得Excel数据,并将其加载到另一个DataFrame中。
- url ='https://github.com/FBosler/Medium-Data-Extraction/blob/master/invoices.xlsx?raw=true'
- res = requests.get(url, allow_redirects=True)
- withopen('invoices.xlsx','wb') asfile:
- file.write(res.content)
- invoices = pd.read_excel('invoices.xlsx')
大功告成!已经创建了三个不同的Pandas数据帧,并且可以在同一个Jupyter notebook中进行访问:
- sales_data
- sales_team
- invoices