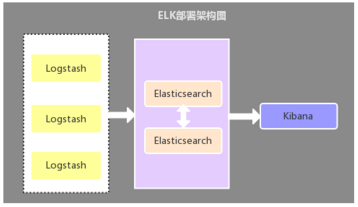
hadoop-2.7.4+hbase-1.3.1+zookeeper-3.4.9搭建分布式集群环境
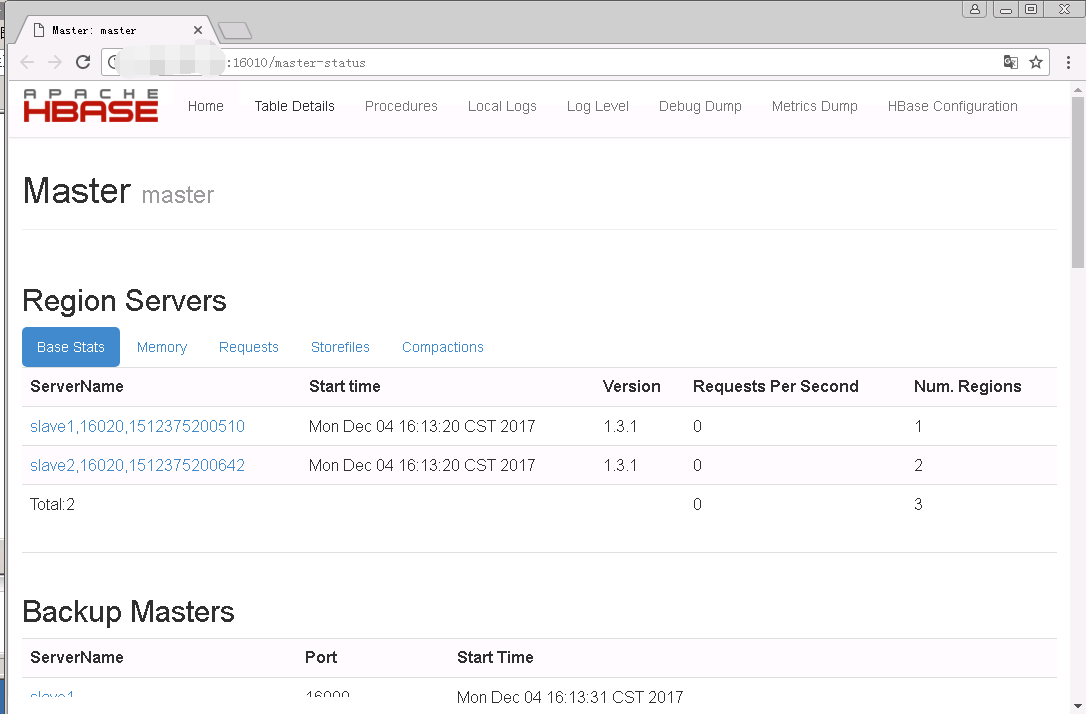
# 系统信息 3台系统: centos6.8内核:4 内存:4G 硬盘:50G #主机名称,ip地址 master: 192.168.1.110 slave1: 192.168.1.111 slave2: 192.168.1.112 ########################软件下载地址######################## 链接:https://pan.baidu.com/s/1dFuBnKt 密码:rhwu ######################## 基础初始配置 ######################## # 版本选择 jdk-8u77-linux-x64.rpm zookeeper-3.4.9.tar.gz hbase-1.3.1-bin.tar.gz hadoop-2.7.4.tar.gz # 配置hosts文件,三台机器都需要 [root@master ~]# cat /etc/hosts 192.168.1.110 master 192.168.1.111 slave1 192.168.1.112 slave2 # 配置用户 1 2 groupadd-g4000hadoop useradd -g4000-u4001hadoop # 所有的主机 hbase,zookeeper 安装目录都在此处 1 2 mkdir /opt/hadoop chown hadoop.hadoop /opt/hadoop/ -R ######################## 时间配置 ######################## # 双机互信 主要有三步: ①生成公钥和私钥 ②导入公钥到认证文件 ③更改权限 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@master~] #ssh-keygen-trsa Generatingpublic /private rsakeypair. Enter file in which tosavethekey( /root/ . ssh /id_rsa ): Enterpassphrase(empty for nopassphrase): Entersamepassphraseagain: Youridentificationhasbeensaved in /root/ . ssh /id_rsa . Yourpublickeyhasbeensaved in /root/ . ssh /id_rsa .pub. Thekeyfingerprintis: ee:15:03:c7:3a:a2:8e:6a:c1:0c:74:d3:97:34:77:04root@master Thekey'srandomartimageis: +--[RSA2048]----+ |..o.Eoo| |.o.oo..| |.....o| |.+| |+.So| |+.o.o| |....| |.o..| |o....| +-----------------+ [root@master~] #cat~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys [root@master~] #chmod700~/.ssh&&chmod600~/.ssh/* # 主机与从机之间必须可以双向无密码登陆,从机与从机之间无限制 1 2 scp ~/. ssh /authorized_keys slave1: /root/ . ssh / scp ~/. ssh /authorized_keys slave2: /root/ . ssh / # 同步时间 1 2 [root@masterzookeeper] #ansiblehbase-mcron-a"name='ntpdate'hour='*/1'job='/usr/sbin/ntpdate192.168.1.110&>/dev/null'" [root@masterzookeeper] #ansiblehbase-mshell-a"crontab-l" # 时间一定要保持一致 ######################## 防火墙配置 ######################## # 防火墙配置 所有的主机上都得配置,或者开放 (2181,2888:3888端口,这部分端口是zookeeper端口) 1 2 3 [root@slave2zookeeper] #iptables-IINPUT-s192.168.1.0/24-jACCEPT [root@slave2zookeeper] #serviceiptablessave [root@slave2zookeeper] #serviceiptablesrestart ######################## JDK配置 ######################## # 安装jdk,并配置环境变量,三台机器都需要安装 # 设置环境变量 1 2 3 [root@slave2~] #cat/etc/profile.d/java.sh export JAVA_HOME= /usr/java/default export PATH=$JAVA_HOME /bin :$PATH # 重新加载配置文件使之生效 [root@slave2 ~]# source /etc/profile.d/java.sh # 查看是否配置完成,3台机器都需要测试 [root@slave2 ~]# java -version java version "1.8.0_77" Java(TM) SE Runtime Environment (build 1.8.0_77-b03) Java HotSpot(TM) 64-Bit Server VM (build 25.77-b03, mixed mode) ######################## zookeeper集群配置 ######################## # 参考文档: http://blog.csdn.net/reblue520/article/details/52279486 # 注意:zookeeper因为有主节点和从节点的关系,所以部署的集群台数最好为奇数个,否则可能出现脑裂导致服务异常 # 下载地址: http://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz # 注意三台机器都需要安装,如果对ansible熟悉的话 可以直接使用它 1 2 mkdir /opt/hadoop chown hadoop.hadoop /opt/hadoop/ -R # 安装zookeeper 1 2 3 4 [root@master~] #cd/opt/hadoop/ [root@masterhadoop] #ls zookeeper-3.4.9. tar .gz [root@masterhadoop] #tarxfzookeeper-3.4.9.tar.gz # 弄一个软链接,配置文件直接指向这个地址,未来方便更新版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@masterhadoop] #ln-svzookeeper-3.4.9zookeeper "zookeeper" -> "zookeeper-3.4.9" [root@masterconf] #cd/opt/hadoop/zookeeper/conf [root@masterconf] #cpzoo_sample.cfgzoo.cfg [root@masterconf] #catzoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir= /opt/hadoop/zookeeper/data dataLogDir= /opt/hadoop/zookeeper/logs clientPort=2181 server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888 # 创建数据以及日志目录,将设置属主属组权限 1 2 [root@masterconf] #mkdir/opt/hadoop/zookeeper/data [root@masterconf] #mkdir/opt/hadoop/zookeeper/logs # 在zoo.cfg中的dataDir指定的目录下,新建myid文件。 # 例如:$ZK_INSTALL/data下,新建myid。在myid文件中输入1。表示为server.1。 echo "1" > data/myid 这里表示的是server.1 如果是第二个机器那么表示server.2 启动:在集群中的每台主机上执行如下命令 bin/zkServer.sh start 查看状态,可以看到其中一台为主节点,其他两台为从节点: bin/zkServer.sh status # 启动zookeeper集群 1 2 3 4 [root@masterzookeeper] #bin/zkServer.shstatus ZooKeeperJMXenabledbydefault Usingconfig: /opt/hadoop/zookeeper/bin/ .. /conf/zoo .cfg Mode:leader # 从节点 1 2 3 4 [root@slave1zookeeper] #bin/zkServer.shstart ZooKeeperJMXenabledbydefault Usingconfig: /opt/hadoop/zookeeper/bin/ .. /conf/zoo .cfg Startingzookeeper...STARTED # 启动报错 说明没有配置myid文件, 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 2017-12-0411:56:21,306[myid:]-INFO[main:QuorumPeerConfig@124]-Readingconfigurationfrom: /opt/hadoop/zookeeper/bin/ .. /conf/zoo .cfg 2017-12-0411:56:21,323[myid:]-INFO[main:QuorumPeer$QuorumServer@149]-Resolved hostname :slave2toaddress:slave2 /192 .168.1.112 2017-12-0411:56:21,324[myid:]-INFO[main:QuorumPeer$QuorumServer@149]-Resolved hostname :slave1toaddress:slave1 /192 .168.1.111 2017-12-0411:56:21,324[myid:]-INFO[main:QuorumPeer$QuorumServer@149]-Resolved hostname :mastertoaddress:master /192 .168.1.110 2017-12-0411:56:21,325[myid:]-INFO[main:QuorumPeerConfig@352]-Defaultingtomajorityquorums 2017-12-0411:56:21,326[myid:]-ERROR[main:QuorumPeerMain@85]-Invalidconfig,exitingabnormally org.apache.zookeeper.server.quorum.QuorumPeerConfig$ConfigException:Errorprocessing /opt/hadoop/zookeeper/bin/ .. /conf/zoo .cfg atorg.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:144) atorg.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:101) atorg.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78) Causedby:java.lang.IllegalArgumentException: /opt/hadoop/zookeeper/data/myid file ismissing atorg.apache.zookeeper.server.quorum.QuorumPeerConfig.parseProperties(QuorumPeerConfig.java:362) atorg.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:140) ...2 more Invalidconfig,exitingabnormally # 这里是因为防火墙开着,没有开放端口的原因 1 2 3 4 5 2016-03-2603:48:07,957[myid:1]-WARN[QuorumPeer[myid=1] /0 :0:0:0:0:0:0:0:2181:QuorumCnxManager@400]-Cannot open channelto3atelectionaddressS2/这里是地址 java.net.ConnectException:主机无法连接 atjava.net.PlainSocketImpl.socketConnect(NativeMethod) atjava.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) atjava.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) ######################## hbase 与hadoop的版本需要对应 ######################## http://blog.csdn.net/shuaigexiaobo/article/details/78114221 低版本与高版本会安不上,还需要注意jdk版本 ######################## hadoop 集群配置 ######################## # 软件放置路径为初级配置的路径 /opt/hadoop 1 2 3 [root@masterhadoop] #tarxfhadoop-2.7.4.tar.gz [root@masterhadoop] #ln-svhadoop-2.7.4hadoop "hadoop" -> "hadoop-2.7.4" # 配置属主属组权限 1 [root@masterhadoop] #chownhadoop.hadoop/opt/hadoop/hadoop-2.7.4-R # 环境变量设置 1 2 3 4 5 6 7 8 9 10 vim /etc/profile .d /hadoop .sh export HADOOP_HOME= /opt/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME /lib/native export PATH=$PATH:$HADOOP_HOME /sbin :$HADOOP_HOME /bin #exportHADOOP_SSH_OPTS="-p22" # 复制到其它主机中 1 2 [root@masterhadoop] #scp/etc/profile.d/hadoop.shslave1:/etc/profile.d/ [root@masterhadoop] #scp/etc/profile.d/hadoop.shslave2:/etc/profile.d/ # 加载环境变量 1 [root@masterhadoop] #soure/etc/profile.d/hadoop.sh # 查看是否生效 1 2 3 [root@masterhadoop] #hadoopversion Hadoop2.7.4 Subversionhttps: //shv @git-wip-us.apache.org /repos/asf/hadoop .git-rcd915e1e8d9d0131462a0b7301586c175728a282 # hadoop配置文件在放置于/opt/hadoop/hadoop/etc/hadoop 1 2 3 4 5 6 7 vimcore-site.xml #添加如下内容 <configuration> <property> <name>fs.default.name< /name > <value>hdfs: //master :9000< /value > < /property > < /configuration > 1 2 3 vimhadoop- env .sh #exportJAVA_HOME=${JAVA_HOME} export JAVA_HOME= /usr/java/default 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vimhdfs-site.xml #配置hdfs文件数据节点以及名称节点 <configuration> <property> <name>dfs.name. dir < /name > <value> /opt/hadoop/hadoop/name < /value > < /property > <property> <name>dfs.data. dir < /name > <value> /opt/hadoop/hadoop/data < /value > < /property > <property> <name>dfs.replication< /name > <value>3< /value > < /property > < /configuration > mkdir /opt/hadoop/hadoop/name mkdir /opt/hadoop/hadoop/data 1 2 3 4 5 6 7 8 [root@masterhadoop] #cpmapred-site.xml.templatemapred-site.xml [root@masterhadoop] #vim!$ <configuration> <property> <name>mapred.job.tracker< /name > <value>master:9001< /value > < /property > < /configuration > # 配置从节点 先删除localhost 1 2 3 /opt/hadoop/hadoop/etc/hadoop/slaves slave1 slave2 # 三台机器都是一样的配置,放置相同的路径 1 2 [root@masterhadoop] #scp-rhadoop-2.7.4slave1:/opt/hadoop/ [root@masterhadoop] #scp-rhadoop-2.7.4slave2:/opt/hadoop/ # 使用ansible或者手动直接软链接过去就行 1 [root@masterhadoop] #ansiblehbase-mshell-a'ln-sv/opt/hadoop/hadoop-2.7.4/opt/hadoop/hadoop' # 配置属主属组文件 1 [root@masterhadoop] #ansiblehbase-mshell-a'chownhadoop.hadoop/opt/hadoop/hadoop-R' # 进入master的/opt/hadoop/hadoop目录,执行以下操作 1 #bin/hadoopnamenode-format #格式化namenode,第一次启动服务前执行的操作,以后不需要执行 # 启动hadoop服务 1 2 3 4 5 [root@masterlogs] #sbin/start-all.sh ThisscriptisDeprecated.Insteadusestart-dfs.shandstart-yarn.sh 17 /12/04 15:56:51WARNutil.NativeCodeLoader:Unabletoloadnative-hadooplibrary for yourplatform...using builtin -javaclasseswhereapplicable Startingnamenodeson[master] master:startingnamenode,loggingto /opt/hadoop/hadoop-2 .7.4 /logs/hadoop-root-namenode-master .out # 查看进程 会发现多了资源名称节点以及namanode 1 2 3 4 5 6 [root@masterlogs] #jps 5057ResourceManager 4900SecondaryNameNode 4709NameNode 5208Jps 2734QuorumPeerMain # 登陆其它节点 会发现多了一个数据节点 1 2 3 4 5 [root@slave2hadoop] #jps 2624QuorumPeerMain 3489NodeManager 3378DataNode 3603Jps ######################## hbase集群配置 ######################## # 软件放置路径为初级配置的路径 /opt/hadoop 1 2 3 [root@masterhadoop] #tarxfhbase-1.3.1-bin.tar.gz [root@masterhadoop] #ln-svhbase-1.3.1hbase "hbase" -> "hbase-1.3.1" # 配置文件目录 /opt/hadoop/hbase/conf vim hbase-env.sh 1 2 3 export JAVA_HOME= /usr/java/default/ export HBASE_CLASSPATH= /opt/hadoop/hadoop/etc/hadoop export HBASE_MANAGES_ZK= false #不使用自带的zk,使用独立的zookeeper vim hbase-site.xml # 配置站点信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <configuration> <property> <name>hbase.rootdir< /name > <value>hdfs: //master :9000 /hbase < /value > < /property > <property> <name>hbase.master< /name > <value>master< /value > < /property > <property> <name>hbase.cluster.distributed< /name > <value> true < /value > < /property > <property> <name>hbase.zookeeper.property.clientPort< /name > <value>2181< /value > #这里指的是zook的端口 < /property > <property> <name>hbase.zookeeper.quorum< /name > #主机名一定要对应上 <value>master,slave1,slave2< /value > < /property > <property> <name>zookeeper.session.timeout< /name > #zook的session超时时长 <value>60000000< /value > < /property > <property> <name>dfs.support.append< /name > <value> true < /value > < /property > < /configuration > vim regionservers# 配置从节点 一定要对应上 1 2 slave1 slave2 # 设置软链接,方便未来升级 [root@master hadoop]# ansible hbase -m shell -a "ln -sv /opt/hadoop/hbase-1.3.1 /opt/hadoop/hbase" # 设置属主属组权限 [root@master hadoop]# ansible hbase -m shell -a "chown hadoop.hadoop /opt/hadoop/hbase-1.3.1 -R" # 启动三台机器上的 hbase服务 [root@master hadoop]# ansible hbase -m shell -a "/opt/hadoop/hbase-1.3.1/bin/start-hbase.sh" # 只需要启动master上的,其它机器上会自动启动 [root@master hadoop]# /opt/hadoop/hbase/bin/start-hbase.sh # 查看master上的服务 1 2 3 4 5 6 7 [root@masterhadoop] #jps 5057ResourceManager 4900SecondaryNameNode 6516HMaster 4709NameNode 6809Jps 2734QuorumPeerMain # 查看slave上的从节点服务 1 2 3 4 5 6 7 [root@slave1~] #jps 3510NodeManager 3399DataNode 2680QuorumPeerMain 5464Jps 5049HMaster 4730HRegionServer # 进入hbase shell进行验证 /opt/hadoop/hbase/bin/hbase shell 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 2017-12-0416:20:28,690WARN[main]util.NativeCodeLoader:Unabletoloadnative-hadooplibrary for yourplatform...using builtin -javaclasseswhereapplicable SLF4J:ClasspathcontainsmultipleSLF4Jbindings. SLF4J:Foundbinding in [jar: file : /opt/hadoop/hbase-1 .3.1 /lib/slf4j-log4j12-1 .7.5.jar! /org/slf4j/impl/StaticLoggerBinder .class] SLF4J:Foundbinding in [jar: file : /opt/hadoop/hadoop-2 .7.4 /share/hadoop/common/lib/slf4j-log4j12-1 .7.10.jar! /org/slf4j/impl/StaticLoggerBinder .class] SLF4J:Seehttp: //www .slf4j.org /codes .html #multiple_bindingsforanexplanation. SLF4J:Actualbindingisof type [org.slf4j.impl.Log4jLoggerFactory] HBaseShell;enter 'help<RETURN>' for listofsupportedcommands. Type "exit<RETURN>" toleavetheHBaseShell Version1.3.1,r930b9a55528fe45d8edce7af42fef2d35e77677a,ThuApr619:36:54PDT2017 hbase(main):001:0> hbase(main):002:0*list TABLE 0row(s) in 0.2350seconds =>[] hbase(main):003:0>create 'scores' , 'grade' , 'course' 0row(s) in 2.4310seconds =>Hbase::Table-scores hbase(main):004:0>list TABLE scores 1row(s) in 0.0080seconds =>[ "scores" ] #### 此处打开的地址都是 master的IP , 192.168.1.110 本文转自812374156 51CTO博客,原文链接:http://blog.51cto.com/xiong51/2047261,如需转载请自行联系原作者