0025-CENTOS6.5安装CDH5.12.1(二)
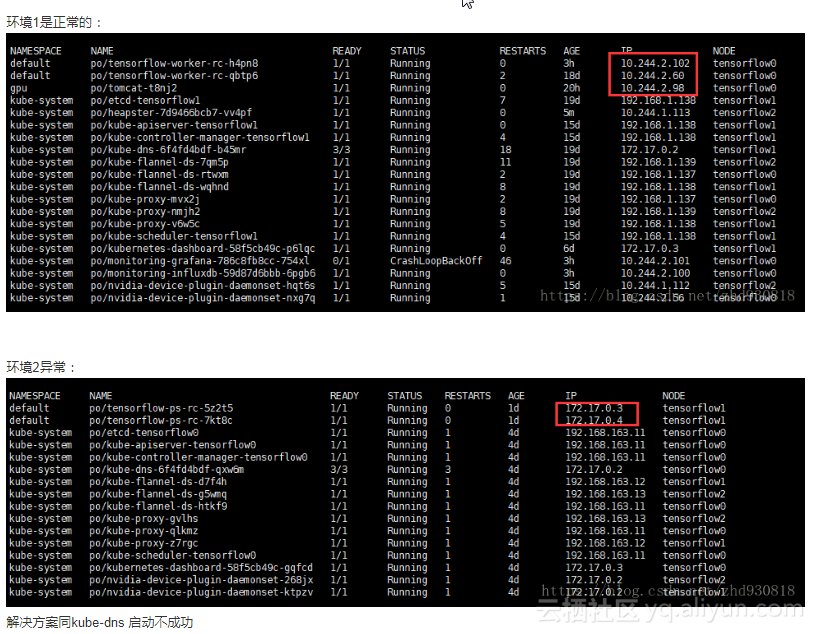
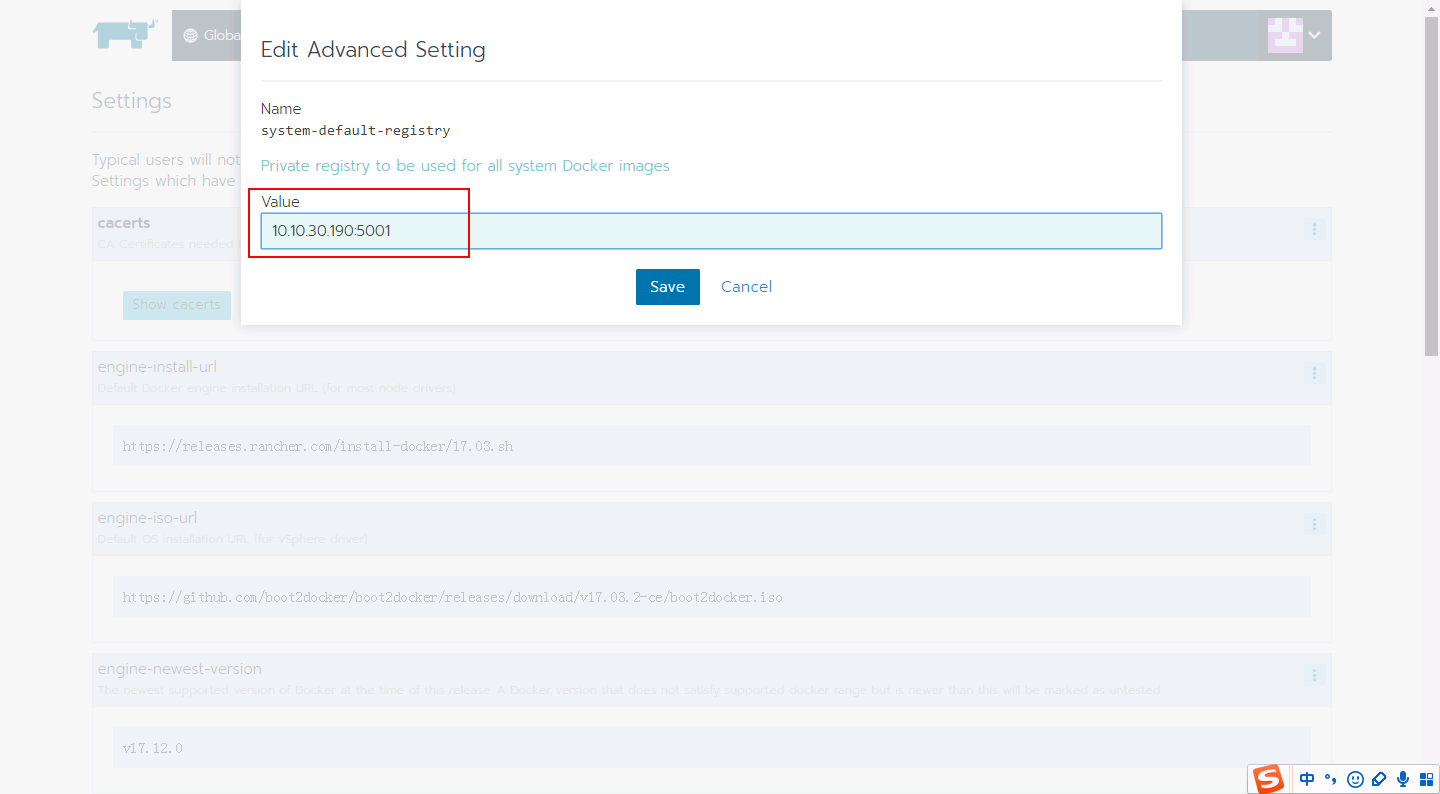
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。 5.快速组件服务验证 5.1HDFS验证(mkdir+put+cat+get) mkdir操作: _[root@ip-172-31-6-148_~]# hadoop fs -mkdir -p /fayson/test [root@ip-172-31-6-148 ~]# hadoop fs -ls / Found 3 items drwxr-xr-x - root supergroup 0 2017-09-0506:16 /fayson drwxrwxrwt - hdfs supergroup 0 2017-09-0504:24 /tmp drwxr-xr-x - hdfs supergroup 0 2017-09-0504:24 /user [root@ip-172-31-6-148 ~]# put操作: _[root@ip-172-31-6-148_~]# vim a.txt 1,test 2,fayson 3.zhangsan [root@ip-172-31-6-148 ~]#hadoop fs -put a.txt /fayson/test [root@ip-172-31-6-148 ~]# hadoop fs -ls /fayson/test Found 1 items -rw-r--r-- 3 root supergroup 27 2017-09-05 06:20 /fayson/test/a.txt [root@ip-172-31-6-148 ~]# cat操作: [root@ip-172-31-6-148 ~]# hadoop fs -cat /fayson/test/a.txt 1,test 2,fayson 3.zhangsan [root@ip-172-31-6-148 ~]# get操作: _[root@ip-172-31-6-148_~]# rm -rf a.txt [root@ip-172-31-6-148 ~]# hadoop fs -get /fayson/test/a.txt [root@ip-172-31-6-148 ~]# cat a.txt 1,test 2,fayson 3.zhangsan [root@ip-172-31-6-148 ~]# 5.2Hive验证 使用hive命令行操作 _[root@ip-172-31-6-148_~]# hive ... hive> create external table test_table( > s1 string, > s2 string > ) row formatdelimited fields terminated by ',' > stored as textfile location '/fayson/test'; OK Time taken: 1.933 seconds hive_>_ select * from test_table; OK 1 test 2 fayson 3 zhangsan Time taken: 0.44 seconds, Fetched: 3row(s) hive> insert into test_table values("4"_,_"lisi"); ... OK Time taken: 18.815 seconds hive_>_ select * from test_table; OK 4 lisi 1 test 2 fayson 3 zhangsan Time taken: 0.079 seconds, Fetched: 4row(s) hive_>_ Hive MapReduce操作 hive_>_ select count(*) from test_table; Query ID = root_20170905064545_100f033c-49b9-488b-9920-648a2e1c7285 ... OK 4 Time taken: 26.428 seconds, Fetched: 1 row(s) hive_>_ 5.3MapReduce验证 [root@ip-172-31-6-148 hadoop-mapreduce]# pwd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce [root@ip-172-31-6-148 hadoop-mapreduce]#hadoop jar hadoop-mapreduce-examples.jar pi 5 5 Number of Maps = 5 Samples per Map = 5 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Starting Job 17/09/05 06:48:53 INFO client.RMProxy: Connecting to ResourceManager atip-172-31-6-148.fayson.com/172.31.6.148:8032 17/09/05 06:48:53 INFO input.FileInputFormat: Total input paths to process : 5 17/09/05 06:48:53 INFO mapreduce.JobSubmitter: number of splits:5 17/09/05 06:48:54 INFO mapreduce.JobSubmitter: Submitting tokens for job:job_1504585342848_0003 17/09/05 06:48:54 INFO impl.YarnClientImpl: Submitted applicationapplication_1504585342848_0003 17/09/05 06:48:54 INFO mapreduce.Job: The url to track the job:http://ip-172-31-6-148.fayson.com:8088/proxy/application_1504585342848_0003/ 17/09/05 06:48:54 INFO mapreduce.Job: Running job: job_1504585342848_0003 17/09/05 06:49:01 INFO mapreduce.Job: Job job_1504585342848_0003 running in ubermode : false 17/09/05 06:49:01 INFO mapreduce.Job: map0% reduce 0% 17/09/05 06:49:07 INFO mapreduce.Job: map20% reduce 0% 17/09/05 06:49:08 INFO mapreduce.Job: map60% reduce 0% 17/09/05 06:49:09 INFO mapreduce.Job: map100% reduce 0% 17/09/05 06:49:15 INFO mapreduce.Job: map100% reduce 100% 17/09/05 06:49:16 INFO mapreduce.Job: Job job_1504585342848_0003 completedsuccessfully 17/09/05 06:49:16 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Numberof bytes read=64 FILE: Numberof bytes written=875624 FILE: Numberof read operations=0 FILE: Numberof large read operations=0 FILE: Number of writeoperations=0 HDFS: Numberof bytes read=1400 HDFS: Numberof bytes written=215 HDFS: Numberof read operations=23 HDFS: Numberof large read operations=0 HDFS: Number of writeoperations=3 Job Counters Launched map tasks=5 Launched reduce tasks=1 Data-local map tasks=5 Total time spent by all maps in occupiedslots (ms)=_27513_ _Total_ **time** spentby all reduces **in** occupied slots (ms)=_3803_ _Total_ **time** spentby all map tasks (ms)=_27513_ _Total_ **time** spentby all reduce tasks (ms)=_3803_ _Total_ vcore-milliseconds taken by all map tasks=27513 Total vcore-millisecondstaken by all reduce tasks=3803 Total megabyte-millisecondstaken by all map tasks=28173312 Total megabyte-millisecondstaken by all reduce tasks=3894272 Map-Reduce Framework Map inputrecords=5 Map outputrecords=10 Map outputbytes=90 Map outputmaterialized bytes=167 Input splitbytes=810 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=167 Reduce input records=10 Reduce output records=0 Spilled Records=20 Shuffled Maps =5 Failed Shuffles=0 Merged Map outputs=5 GC timeelapsed (ms)=_273_ _CPU_ **time** spent(ms)=_4870_ _Physical_ memory (bytes) snapshot=2424078336 Virtual memory (bytes) snapshot=9435451392 Total committedheap usage (bytes)=_2822766592_ _Shuffle_ Errors BAD\_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input FormatCounters Bytes Read=590 File Output FormatCounters Bytes Written=97 Job Finished in 23.453 seconds Estimated value of Pi is 3.68000000000000000000 [root@ip-172-31-6-148 hadoop-mapreduce]# 5.4Spark验证 _[root@ip-172-31-6-148_~]# spark-shell Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). Welcome to _\_\_\_\__ \_\_ / __/__ ___ _____/ /__ \_\ \/ \_ \/ \_ _`_/\_\_/ '\_/ /___/ .__/_,_/_//_/_ version 1.6.0 /_/ ... Spark context available as sc (master = yarn-client, app id = application_1504585342848_0004). 17/09/05 06:51:59 WARN metastore.ObjectStore: Version information not found in metastore.hive.metastore.schema.verification is not enabled so recording the schemaversion 1.1.0-cdh5.12.1 17/09/05 06:51:59 WARN metastore.ObjectStore: Failed to get database default,returning NoSuchObjectException SQL context available as sqlContext. scala> val textFile=sc.textFile("hdfs://ip-172-31-6-148.fayson.com:8020/fayson/test/a.txt") textFile: org.apache.spark.rdd.RDDString =hdfs://ip-172-31-6-148.fayson.com:8020/fayson/test/a.txt MapPartitionsRDD1 at textFileat :27 _scala> textFile.count_() res0: Long = 3 scala_>_ 醉酒鞭名马,少年多浮夸! 岭南浣溪沙,呕吐酒肆下!挚友不肯放,数据玩的花!温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。 欢迎关注Hadoop实操,第一时间,分享更多Hadoop干货,喜欢请关注分享。 原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操