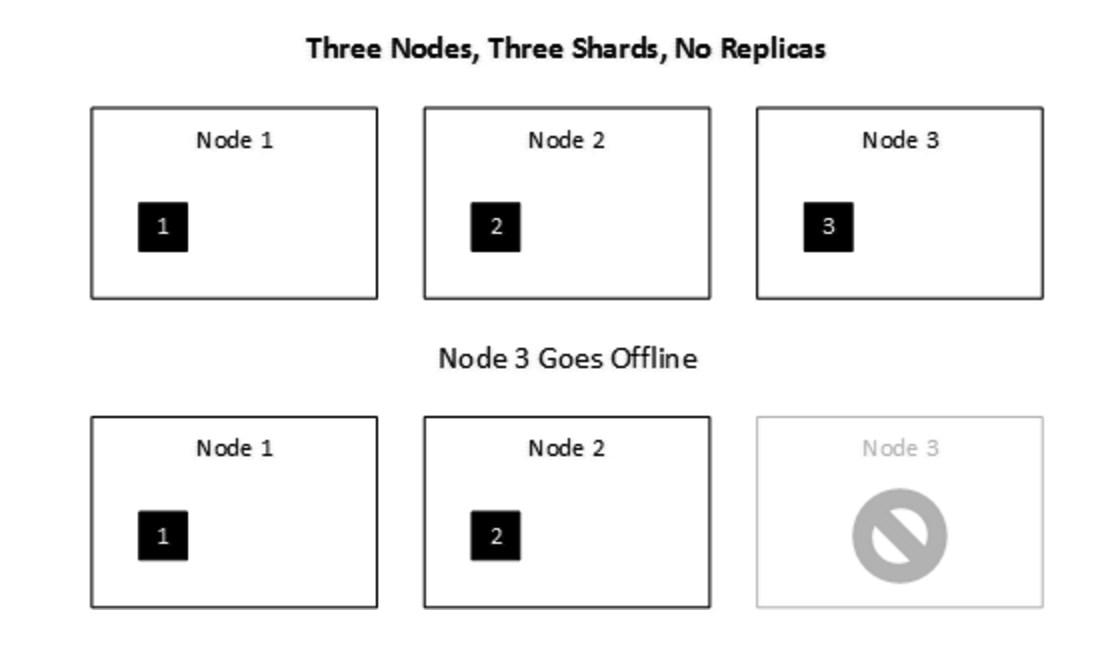
Elasticsearch压缩索引——lucene倒排索引本质是列存储+使用嵌套文档可以大幅度提高压缩率
注意:由于是重复数据,词法不具有通用性!文章价值不大! 摘自:https://segmentfault.com/a/1190000002695169 Doc Values 会压缩存储重复的内容。给定这样一个简单的 mapping mappings = { 'testdata': { '_source': {'enabled': False}, '_all': {'enabled': False}, 'properties': { 'name': { 'type': 'string', 'index': 'no', 'store': False, 'dynamic': 'strict', 'fielddata': {'format': 'doc_values'} } } } } 插入100万行随机的重复值 words = ['hello', 'world', 'there', 'here'] def read_test_data_in_batches(): batch = [] for i in range(10000 * 100): if i % 50000 == 0: print(i) if len(batch) > 10000: yield batch batch = [] batch.append({ '_index': 'wentao-test-doc-values', '_type': 'testdata', '_source': {'name': random.choice(words)} }) print(i) yield batch 磁盘占用是 size: 28.5Mi (28.5Mi) docs: 1,000,000 (1,000,000) 把每个word搞长一些,同样是插入100万行 words = ['hello' * 100, 'world' * 100, 'there' * 100, 'here' * 100] def read_test_data_in_batches(): batch = [] for i in range(10000 * 100): if i % 50000 == 0: print(i) if len(batch) > 10000: yield batch batch = [] batch.append({ '_index': 'wentao-test-doc-values', '_type': 'testdata', '_source': {'name': random.choice(words)} }) print(i) yield batch 磁盘占用不升反降 size: 14.4Mi (14.4Mi) docs: 1,000,000 (1,000,000) 这说明了lucene在底层用列式存储这些字符串的时候是做了压缩的。这个要是在某个商业列式数据库里,就这么点优化都是要大书特书的dictionary encoding优化云云。 Nested Document 实验表明把一堆小文档打包成一个大文档的nested document可以压缩存储空间。把前面的mapping改成这样: mappings = { 'testdata': { '_source': {'enabled': False}, '_all': {'enabled': False}, 'properties': { 'children': { 'type': 'nested', 'properties': { 'name': { 'type': 'string', 'index': 'no', 'store': False, 'dynamic': 'strict', 'fielddata': {'format': 'doc_values'} } } } } } } 还是插入100万行,但是每一千行打包成一个大文档 words = ['hello', 'world', 'there', 'here'] def read_test_data_in_batches(): batch = [] for i in range(10000 * 100): if i % 50000 == 0: print(i) if len(batch) > 1000: yield [{ '_index': 'wentao-test-doc-values2', '_type': 'testdata', '_source': {'children': batch} }] batch = [] batch.append({'name': random.choice(words)}) print(i) yield [{ '_index': 'wentao-test-doc-values2', '_type': 'testdata', '_source': {'children': batch} }] 磁盘占用是 size: 2.47Mi (2.47Mi) docs: 1,001,000 (1,001,000) 文档数没有变小,但是磁盘空间仅仅占用了2.47M。这个应该受益于lucene内部对于嵌套文档的存储优化。 本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/6269604.html,如需转载请自行联系原作者