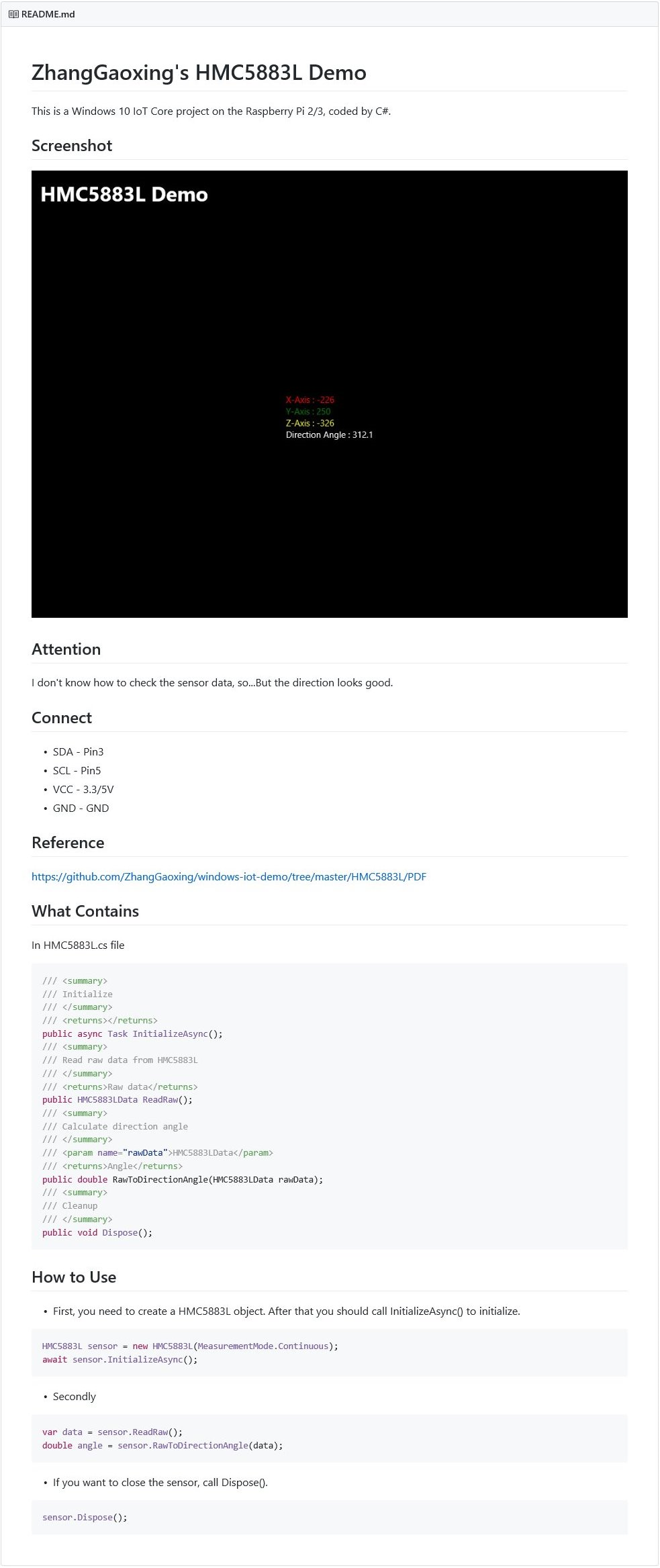
张高兴的 Windows 10 IoT 开发笔记:使用 ADS1115 读取模拟信号
考虑到 Raspberry Pi 读取模拟信号是很烦人的事情,更何况是在没人玩的 Windows 10 IoT 下,所以准备正儿八经的写点东西。 需求:使用 Raspberry Pi 读取输出模拟信号的 MQ 系列气体传感器。(GitHub:https://github.com/ZhangGaoxing/windows-iot-demo/tree/master/ADS1115) 由于 Raspberry Pi 3B 内部并没有集成 ADC,因此需要外接 ADC 来进行模数转换。外接 ADC 选用的是 ADS1115,淘宝到处都是,而且还不贵, I2C 的通讯方式实现起来相对容易些。 1. 过程分析 在 ADS1115 的数据手册(GitHub项目中附带了PDF)的第11页中,官方给出了一个简单的快速开始 (1)设置配置寄存器 (2)定位到转换寄存器 (3)读取转换寄存器 2. 寄存器配置分析 了解了大概过程后接下来就是查寄存器的格式及配置方法了。 ADS1115 的 ADDR 接口的接法决定了地址。 地址确定后,下面来看看寄存器的地址指针。由于我们只是简单的读取,只需要用到最上面的两个指针。配置寄存器为 0x01,转换寄存器为 0x00。 按照第一点的过程分析,第一步我们要设置配置寄存器。配置寄存器分高八位和低八位,指针定位到配置寄存器后,需要分别写入两个 byte 的配置数据。详细的比特位的功能可以查下数据手册。在这里只介绍用的到的。 在14-12位,是 MUX 配置。简单的说,这决定了 ADS1115 的 A0-A3 接口的测量方式。比如说,当设置为 0x04 时测量的为 A0-GND 的电压,当设置为 0x00 时测量的为 A0-A1 间的电压。 在11-9位,是 PGA 配置。这决定了 ADS1115 的量程。 在第8位,是 ADS1115 的状态配置。0x00 为测量模式,0x01 为休眠。 在第7-5位,是每秒采样次数的配置。 以上是我们需要的配置位,其他的按照数据手册上的默认即可。即高八位 0 100 001 0(0x42),低八位 100 0 0 0 11(0x83)。需要其他的功能,按照数据手册上的更改即可。 配置完成后,读取数据是非常简单的,直接读取即可。 3. 连线 VDD - 5V GND - GND SCL - SCL SDA - SDA ADDR - GND A0 - MQ 传感器的 A0 4. 部分代码 详细的代码已经放在 GitHub 上了,这里只给出 ADS1115.cs 的简单介绍。 /// <summary> /// Constructor /// </summary> /// <param name="addr">ADS1115 Address</param> /// <param name="mux">Input Multiplexer</param> /// <param name="pga">Programmable Gain Amplifier</param> /// <param name="rate">Data Rate </param> public ADS1115(AddressSetting addr = AddressSetting.GND, InputMultiplexeConfig mux = InputMultiplexeConfig.AIN0, PgaConfig pga = PgaConfig.FS4096, DataRate rate = DataRate.SPS128); /// <summary> /// Initialize ADS1115 /// </summary> /// <returns></returns> public async Task InitializeAsync(); /// <summary> /// Read Raw Data /// </summary> /// <returns>Raw Value</returns> public short ReadRaw(); /// <summary> /// Convert Raw Data to Voltage /// </summary> /// <param name="val">Raw Data</param> /// <returns>Voltage</returns> public double RawToVoltage(short val); /// <summary> /// Cleanup /// </summary> public void Dispose(); 5. 如何使用 第一步,需要实例化 ADS1115,并调用InitializeAsync()。 ADS1115 adc = new ADS1115(AddressSetting.GND, InputMultiplexeConfig.AIN0, PgaConfig.FS4096, DataRate.SPS860); await adc.InitializeAsync(); 第二步,读取数据。 short raw = adc.ReadRaw(); double vol = adc.RawToVoltage(raw); 如果需要释放,调用adc.Dispose(); 6. 运行图