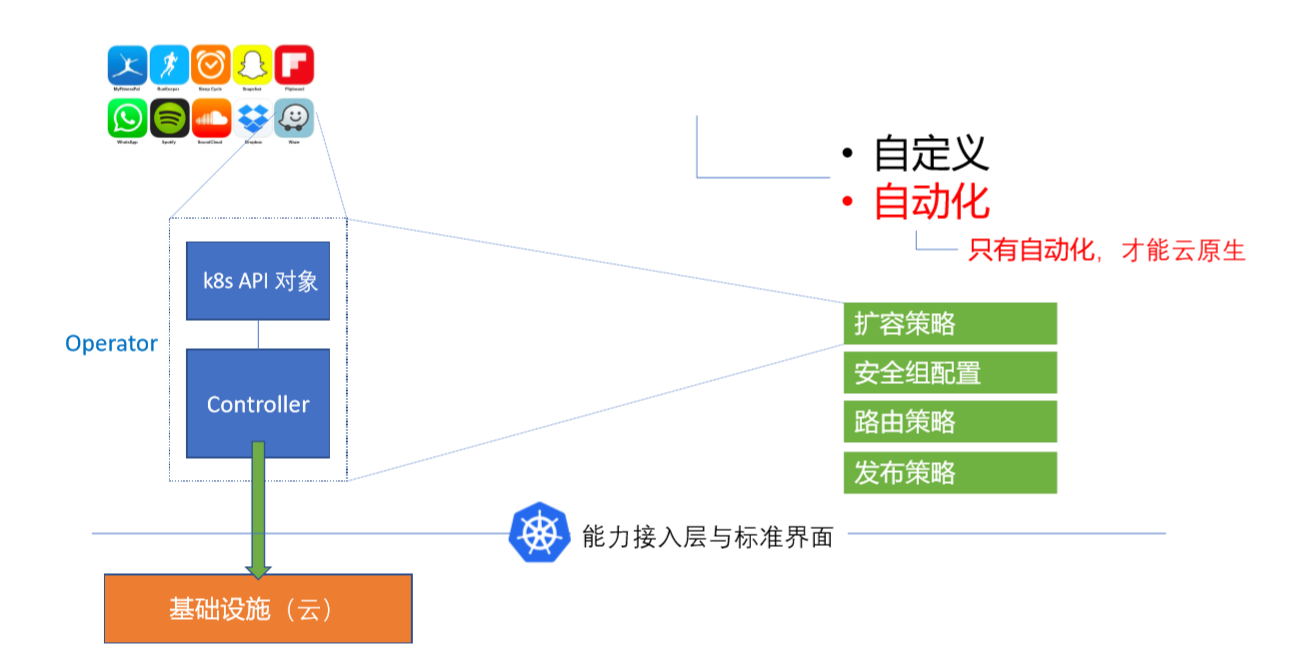
从认证到调度,K8s 集群上运行的小程序到底经历了什么?
作者 | 声东 阿里云售后技术专家 导读:不知道大家有没有意识到一个现实:大部分时候,我们已经不像以前一样,通过命令行,或者可视窗口来使用一个系统了。 前言 现在我们上微博、或者网购,操作的其实不是眼前这台设备,而是一个又一个集群。通常,这样的集群拥有成百上千个节点,每个节点是一台物理机或虚拟机。集群一般远离用户,坐落在数据中心。为了让这些节点互相协作,对外提供一致且高效的服务,集群需要操作系统。Kubernetes 就是这样的操作系统。 比较 Kubernetes 和单机操作系统,Kubernetes 相当于内核,它负责集群软硬件资源管理,并对外提供统一的入口,用户可以通过这个入口来使用集群,和集群沟通。 而运行在集群之上的程序,与普通程序有很大的不同。这样的程序,是“关在笼子里”的程序。它们从被制作,到被部署,再到被使用,都不寻常。我们只有深挖根源,才能理解其本质。 “关在笼子里”的程序 代码 我们使用 go 语言写了一个简单的 web 服务器程序 app.go,这个程序监听在 2580 这个端口。通过 http 协议访问这个服务的根路径,服务会返回 "This is a small app for kubernetes..." 字符串。 package main import ( "github.com/gorilla/mux" "log" "net/http" ) func about(w http.ResponseWriter, r *http.Request) { w.Write([]byte("This is a small app for kubernetes...\n")) } func main() { r := mux.NewRouter() r.HandleFunc("/", about) log.Fatal(http.ListenAndServe("0.0.0.0:2580", r)) } 使用 go build 命令编译这个程序,产生 app 可执行文件。这是一个普通的可执行文件,它在操作系统里运行,会依赖系统里的库文件。 # ldd app linux-vdso.so.1 => (0x00007ffd1f7a3000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f554fd4a000) libc.so.6 => /lib64/libc.so.6 (0x00007f554f97d000) /lib64/ld-linux-x86-64.so.2 (0x00007f554ff66000) “笼子” 为了让这个程序不依赖于操作系统自身的库文件,我们需要制作容器镜像,即隔离的运行环境。Dockerfile 是制作容器镜像的“菜谱”。我们的菜谱就只有两个步骤,下载一个 centos 的基础镜像,把 app 这个可执行文件放到镜像中 /usr/local/bin 目录中去。 FROM centos ADD app /usr/local/bin 地址 制作好的镜像存再本地,我们需要把这个镜像上传到镜像仓库里去。这里的镜像仓库,相当于应用商店。我们使用阿里云的镜像仓库,上传之后镜像地址是: registry.cn-hangzhou.aliyuncs.com/kube-easy/app:latest 镜像地址可以拆分成四个部分:仓库地址/命名空间/镜像名称:镜像版本。显然,镜像上边的镜像,在阿里云杭州镜像仓库,使用的命名空间是 kube-easy,镜像名:版本是 app:latest。至此,我们有了一个可以在 Kubernetes 集群上运行的、“关在笼子里”的小程序。 得其门而入 入口 Kubernetes 作为操作系统,和普通的操作系统一样,有 API 的概念。有了 API,集群就有了入口;有了 API,我们使用集群,才能得其门而入。Kubernetes 的 API 被实现为运行在集群节点上的组件 API Server。这个组件是典型的 web 服务器程序,通过对外暴露 http(s) 接口来提供服务。 这里我们创建一个阿里云 Kubernetes 集群。登录集群管理页面,我们可以看到 API Server 的公网入口。 API Server 内网连接端点: https://xx.xxx.xxx.xxx:6443 双向数字证书验证 阿里云 Kubernetes 集群 API Server 组件,使用基于 CA 签名的双向数字证书认证来保证客户端与 api server 之间的安全通信。这句话很绕口,对于初学者不太好理解,我们来深入解释一下。 从概念上来讲,数字证书是用来验证网络通信参与者的一个文件。这和学校颁发给学生的毕业证书类似。在学校和学生之间,学校是可信第三方 CA,而学生是通信参与者。如果社会普遍信任一个学校的声誉的话,那么这个学校颁发的毕业证书,也会得到社会认可。参与者证书和 CA 证书可以类比毕业证和学校的办学许可证。 这里我们有两类参与者,CA 和普通参与者;与此对应,我们有两种证书,CA 证书和参与者证书;另外我们还有两种关系,证书签发关系以及信任关系。这两种关系至关重要。 我们先看签发关系。如下图,我们有两张 CA 证书,三个参与者证书。 其中最上边的 CA 证书,签发了两张证书,一张是中间的 CA 证书,另一张是右边的参与者证书;中间的 CA 证书,签发了下边两张参与者证书。这六张证书以签发关系为联系,形成了树状的证书签发关系图。 然而,证书以及签发关系本身,并不能保证可信的通信可以在参与者之间进行。以上图为例,假设最右边的参与者是一个网站,最左边的参与者是一个浏览器,浏览器相信网站的数据,不是因为网站有证书,也不是因为网站的证书是 CA 签发的,而是因为浏览器相信最上边的 CA,也就是信任关系。 理解了 CA(证书),参与者(证书),签发关系,以及信任关系之后,我们回过头来看“基于 CA 签名的双向数字证书认证”。客户端和 API Server 作为通信的普通参与者,各有一张证书。而这两张证书,都是由 CA 签发,我们简单称它们为集群 CA 和客户端 CA。客户端信任集群 CA,所以它信任拥有集群 CA 签发证书的 API Server;反过来 API Server 需要信任客户端 CA,它才愿意与客户端通信。 阿里云 Kubernetes 集群,集群 CA 证书,和客户端 CA 证书,实现上其实是一张证书,所以我们有这样的关系图。 KubeConfig 文件 登录集群管理控制台,我们可以拿到 KubeConfig 文件。这个文件包括了客户端证书,集群 CA 证书,以及其他。证书使用 base64 编码,所以我们可以使用 base64 工具解码证书,并使用 openssl 查看证书文本。 首先,客户端证书的签发者 CN 是集群 id c0256a3b8e4b948bb9c21e66b0e1d9a72,而证书本身的 CN 是子账号 252771643302762862; Certificate: Data: Version: 3 (0x2) Serial Number: 787224 (0xc0318) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 06:03:00 2018 GMT Not After : Nov 28 06:08:39 2021 GMT Subject: O=system:users, OU=, CN=252771643302762862 其次,只有在 API Server 信任客户端 CA 证书的情况下,上边的客户端证书才能通过 API Server 的验证。kube-apiserver 进程通过 client-ca-file 这个参数指定其信任的客户端 CA 证书,其指定的证书是 /etc/kubernetes/pki/apiserver-ca.crt。这个文件实际上包含了两张客户端 CA 证书,其中一张和集群管控有关系,这里不做解释,另外一张如下,它的 CN 与客户端证书的签发者 CN 一致; Certificate: Data: Version: 3 (0x2) Serial Number: 787224 (0xc0318) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 06:03:00 2018 GMT Not After : Nov 28 06:08:39 2021 GMT Subject: O=system:users, OU=, CN=252771643302762862 再次,API Server 使用的证书,由 kube-apiserver 的参数 tls-cert-file 决定,这个参数指向证书 /etc/kubernetes/pki/apiserver.crt。这个证书的 CN 是 kube-apiserver,签发者是 c0256a3b8e4b948bb9c21e66b0e1d9a72,即集群 CA 证书; Certificate: Data: Version: 3 (0x2) Serial Number: 2184578451551960857 (0x1e512e86fcba3f19) Signature Algorithm: sha256WithRSAEncryption Issuer: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 Validity Not Before: Nov 29 03:59:00 2018 GMT Not After : Nov 29 04:14:23 2019 GMT Subject: CN=kube-apiserver 最后,客户端需要验证上边这张 API Server 的证书,因而 KubeConfig 文件里包含了其签发者,即集群 CA 证书。对比集群 CA 证书和客户端 CA 证书,发现两张证书完全一样,这符合我们的预期。 Certificate: Data: Version: 3 (0x2) Serial Number: 786974 (0xc021e) Signature Algorithm: sha256WithRSAEncryption Issuer: C=CN, ST=ZheJiang, L=HangZhou, O=Alibaba, OU=ACS, CN=root Validity Not Before: Nov 29 03:59:00 2018 GMT Not After : Nov 24 04:04:00 2038 GMT Subject: O=c0256a3b8e4b948bb9c21e66b0e1d9a72, OU=default, CN=c0256a3b8e4b948bb9c21e66b0e1d9a72 访问 理解了原理之后,我们可以做一个简单的测试:以证书作为参数,使用 curl 访问 api server,并得到预期结果。 # curl --cert ./client.crt --cacert ./ca.crt --key ./client.key https://xx.xx.xx.xxx:6443/api/ { "kind": "APIVersions", "versions": [ "v1" ], "serverAddressByClientCIDRs": [ { "clientCIDR": "0.0.0.0/0", "serverAddress": "192.168.0.222:6443" } ] } 择优而居 两种节点,一种任务 如开始所讲,Kubernetes 是管理集群多个节点的操作系统。这些节点在集群中的角色,却不必完全一样。Kubernetes 集群有两种节点:master 节点和 worker 节点。 这种角色的区分,实际上就是一种分工:master 负责整个集群的管理,其上运行的以集群管理组件为主,这些组件包括实现集群入口的 api server;而 worker 节点主要负责承载普通任务。 在 Kubernetes 集群中,任务被定义为 pod 这个概念。pod 是集群可承载任务的原子单元,pod 被翻译成容器组,其实是意译,因为一个 pod 实际上封装了多个容器化的应用。原则上来讲,被封装在一个 pod 里边的容器,应该是存在相当程度的耦合关系。 择优而居 调度算法需要解决的问题,是替 pod 选择一个舒适的“居所”,让 pod 所定义的任务可以在这个节点上顺利地完成。 为了实现“择优而居”的目标,Kubernetes 集群调度算法采用了两步走的策略: 第一步,从所有节点中排除不满足条件的节点,即预选; 第二步,给剩余的节点打分,最后得分高者胜出,即优选。 下面我们使用文章开始的时候制作的镜像,创建一个 pod,并通过日志来具体分析一下,这个 pod 怎么样被调度到某一个集群节点。 Pod 配置 首先,我们创建 pod 的配置文件,配置文件格式是 json。这个配置文件有三个地方比较关键,分别是镜像地址,命令以及容器的端口。 { "apiVersion": "v1", "kind": "Pod", "metadata": { "name": "app" }, "spec": { "containers": [ { "name": "app", "image": "registry.cn-hangzhou.aliyuncs.com/kube-easy/app:latest", "command": [ "app" ], "ports": [ { "containerPort": 2580 } ] } ] } } 日志级别 集群调度算法被实现为运行在 master 节点上的系统组件,这一点和 api server 类似。其对应的进程名是 kube-scheduler。kube-scheduler 支持多个级别的日志输出,但社区并没有提供详细的日志级别说明文档。查看调度算法对节点进行筛选、打分的过程,我们需要把日志级别提高到 10,即加入参数 --v=10。 kube-scheduler --address=127.0.0.1 --kubeconfig=/etc/kubernetes/scheduler.conf --leader-elect=true --v=10 创建 Pod 使用 curl,以证书和 pod 配置文件等作为参数,通过 POST 请求访问 api server 的接口,我们可以在集群里创建对应的 pod。 # curl -X POST -H 'Content-Type: application/json;charset=utf-8' --cert ./client.crt --cacert ./ca.crt --key ./client.key https://47.110.197.238:6443/api/v1/namespaces/default/pods -d@app.json 预选 预选是 Kubernetes 调度的第一步,这一步要做的事情,是根据预先定义的规则,把不符合条件的节点过滤掉。不同版本的 Kubernetes 所实现的预选规则有很大的不同,但基本的趋势,是预选规则会越来越丰富。 比较常见的两个预选规则是 PodFitsResourcesPred 和 PodFitsHostPortsPred。前一个规则用来判断,一个节点上的剩余资源,是不是能够满足 pod 的需求;而后一个规则,检查一个节点上某一个端口是不是已经被其他 pod 所使用了。 下图是调度算法在处理测试 pod 的时候,输出的预选规则的日志。这段日志记录了预选规则 CheckVolumeBindingPred的执行情况。某些类型的存储卷(PV),只能挂载到一个节点上,这个规则可以过滤掉不满足 pod 对 PV 需求的节点。 从 app 的编排文件里可以看到,pod 对存储卷并没有什么需求,所以这个条件并没有过滤掉节点。 优选 调度算法的第二个阶段是优选阶段。这个阶段,kube-scheduler 会根据节点可用资源及其他一些规则,给剩余节点打分。 目前,CPU 和内存是调度算法考量的两种主要资源,但考量的方式并不是简单的,剩余 CPU、内存资源越多,得分就越高。 日志记录了两种计算方式:LeastResourceAllocation 和 BalancedResourceAllocation。 前一种方式计算 pod 调度到节点之后,节点剩余 CPU 和内存占总 CPU 和内存的比例,比例越高得分就越高; 第二种方式计算节点上 CPU 和内存使用比例之差的绝对值,绝对值越大,得分越少。 这两种方式,一种倾向于选出资源使用率较低的节点,第二种希望选出两种资源使用比例接近的节点。这两种方式有一些矛盾,最终依靠一定的权重来平衡这两个因素。 除了资源之外,优选算法会考虑其他一些因素,比如 pod 与节点的亲和性,或者如果一个服务有多个相同 pod 组成的情况下,多个 pod 在不同节点上的分散程度,这是保证高可用的一种策略。 得分 最后,调度算法会给所有的得分项乘以它们的权重,然后求和得到每个节点最终的得分。因为测试集群使用的是默认调度算法,而默认调度算法把日志中出现的得分项所对应的权重,都设置成了 1,所以如果按日志里有记录得分项来计算,最终三个节点的得分应该是 29,28 和 29。 之所以会出现日志输出的得分和我们自己计算的得分不符的情况,是因为日志并没有输出所有的得分项,猜测漏掉的策略应该是 NodePreferAvoidPodsPriority,这个策略的权重是 10000,每个节点得分 10,所以才得出最终日志输出的结果。 结束语 在本文中,我们以一个简单的容器化 web 程序为例,着重分析了客户端怎么样通过 Kubernetes 集群 API Server 认证,以及容器应用怎么样被分派到合适节点这两件事情。 在分析过程中,我们弃用了一些便利的工具,比如 kubectl,或者控制台。我们用了一些更接近底层的小实验,比如拆解 KubeConfig 文件,再比如分析调度器日志来分析认证和调度算法的运作原理。希望这些对大家进一步理解 Kubernetes 集群有所帮助。 架构师成长系列直播 “阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”