我的 OpenStack 代码贡献初体验
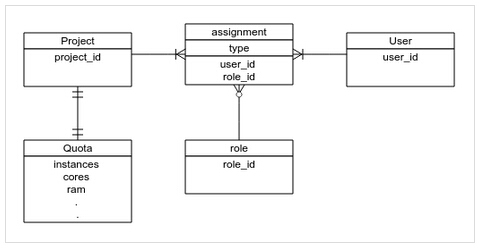
OpenStack如今已成为开源云平台中的明星项目,得到广泛关注。OpenStack的优秀出众依赖于众多开发者的努力,在享受其带来的便利与快捷的同时,为其做一份贡献也是一个开发者的义务。在前段时间的OpenStack的测试过程中,我发现Nova项目中的一个Bug,于是向社区提交了Bug报告,并提交代码修复了该Bug,从提交报告到代码入库经历近一月,下面重现整个过程。 一.发现Bug: Nova中的虚拟机软删除(soft-delete)功能,是指在一段时间内,仅将数据库中的某虚拟机记录做一个标记 (status='SOFT-DELETE'),然后将虚拟化平台(kvm等)中对应的虚拟机实例置为关机状态,当超过某一时间段后才将虚拟机实例真正删除;该功能为云平台用户提供了“后悔时间”,可以在一定程度上挽回误操作。默认情况下,软删除功能是关闭的,其开启方式是在nova配置文件中添加"reclaim_instance_interval"选项,并将其值设置为"后悔时间"的毫秒数。 在描述具体Bug前,需要对openstack中的用户管理方面的基本概念简单介绍一下。 上图是openstack用户模型的简化版本,为了便于理解将不属于keystone管理的quota也拿了过来。 Bug就与软删除相关。具体场景是这样的:假设OpenStack中有两个项目和两个用户:普通项目A其用户a,管理员项目Admin其用户为 admin(用户管理相关概念可以查阅keystone文档),用户a不慎将自己的一台虚拟机删除了,这时求助系统管理员看看有没有办法恢复,好在系统开启的软删除功能,而且被删除的虚拟机还在可回收的时间范围内,这时管理员便以admin的身份登录系统,为用户a恢复了虚拟机,但是细心的管理员却发现了一些不对:其Admin项目下并没有任何虚拟机,但是其配额却被使用了,难道这和刚才的操作有关?再来重试一下:普通用户删除虚拟机,admin用户来为其恢复,这时配额又发生了变化,果然如此:被恢复的虚拟机的配额错误的添加到了Admin项目下。该Bug在最新的kilo版本中仍然存在,感兴趣的同学可以实验一下。 二.定位Bug: 发现了Bug的存在,那就更进一步,到代码中找一下原因吧。 如何确定问题代码的位置呢?这需要对Nova的项目结构有大体的了解,我们来简单了解一下:上图是nova架构的极简版本,与本问题无关的组件都没有画上去,恢复虚拟机的操作过程大致是这样: nova api接收到用户请求,到数据库中查询虚拟机详情,将该虚拟机所在的主机、名称等数据发送到消息队列中; nova compute服务在监听到相关消息后,开始执行具体操作,将虚拟机在数据库中的记录做些调整,调用底层驱动恢复虚拟机。 既然软删除的功能层面没有任何问题,虚拟机的删除和恢复过程都很顺利,可见不会是驱动的问题,顺着API层的代码调用往下找,很快就可以定位了。直接看出问题的代码片段: defrestore(self,context,instance): #该代码做了删减 flavor=instance.get_flavor() #获取quotas对象 num_instances,quotas=self._check_num_instances_quota( context,flavor,1,1) self._record_action_start(context,instance,instance_actions.RESTORE) try: ifinstance.host: instance.task_state=task_states.RESTORING instance.deleted_at=None instance.save(expected_task_state=[None]) self.compute_rpcapi.restore_instance(context,instance) else: instance.vm_state=vm_states.ACTIVE instance.task_state=None instance.deleted_at=None instance.save(expected_task_state=[None]) #更新quotas quotas.commit() 上面的这段代码就是API层面上进行虚拟机回收的主要方法,可以看到其中有明显的配额操作(quotas),在解读这段代码前有必要先对nova 中"context"的概念做个简介。不仅是nova,在openstack其他项目中都随处可见这个"context",它是一个包装了用户请求信息的对象,包含用户的项目和认证信息等,通过它可以简便的进行各项目之间的API调用和用户信息的查询,API服务接收到用户的每一次HTTP请求,都会创建一个新的context。 回到这段代码,我们重点关注对quotas所作的操作:在方法的第二行,通过了一个方法获取了quotas,有在方法的结尾执行了 quotas.commit(),能够获取到的信息不多,我们再看一下获取quotas的方法:_check_num_instances_quota #这里只截取一部分 def_check_num_instances_quota(self,context,instance_type,min_count, max_count): req_cores=max_count*instance_type['vcpus'] vram_mb=int(instance_type.get('extra_specs',{}).get(VIDEO_RAM,0)) req_ram=max_count*(instance_type['memory_mb']+vram_mb) try: quotas=objects.Quotas(context) quotas.reserve(context,instances=max_count, cores=req_cores,ram=req_ram) ... returnmax_count,quotas 这里可以看到获取quotas的过程:通过当前的context创建quotas对象,并且执行了reserve操作; 我们知道context是由HTTP请求而来,里面保存的是发请求的用户的信息,所以这里的quotas对象的“所有者”也就是context中的用户。 结合Bug发生的场景来看:管理员还原用户a的虚拟机,发请求的是管理员,当前context中记录的是管理员的信息,这里的quotas理所当然的就是管理员的,然后操作了用户a的虚拟机,更新的却是管理员的quotas。嗯,真相大白! 三.修复Bug: Bug的原因是获取的quotas并不属于期望的用户,但是直接修改context显然不合适(会影响后续的操作),先了解一下quotas对象自身吧: classQuotas(base.NovaObject): #部分代码 def__init__(self,*args,**kwargs): super(Quotas,self).__init__(*args,**kwargs) #Setupdefaults. self.reservations=[] self.project_id=None self.user_id=None self.obj_reset_changes() ... defreserve(self,context,expire=None,project_id=None,user_id=None, **deltas): reservations=quota.QUOTAS.reserve(context,expire=expire, project_id=project_id, user_id=user_id, **deltas) self.reservations=reservations self.project_id=project_id self.user_id=user_id self.obj_reset_changes() defcommit(self,context=None): ifnotself.reservations: return ifcontextisNone: context=self._context quota.QUOTAS.commit(context,self.reservations, project_id=self.project_id, user_id=self.user_id) self.reservations=None self.obj_reset_changes() 注意看reserve方法的参数,默认为None的project_id和user_id,这正是改变quotas属主的方便入口! 修改后的代码这里就不贴了,感兴趣的同学可以到这次提交中看:Code Review 四.代码提交和Review: openstack社区有着整套项目管理流程,这里有一张图能够较详细的描述工作流程: 由图可见bugfix是其中最简单的流程。 关于如何提交代码,这篇文章有详细的介绍: 向 OpenStack 贡献您的代码。另外需要注意一点,在国内向社区提交代码,经常会因为网络问题导致无法提交,幸好找到了大牛的博客介绍了该类问题的解决办法。 修改完代码的单元测试和pep8本地测试当然不能少,早就知道社区对单元测试要求很严格,这次才真正领教了,三行代码的修改,单元测试却写了30 行,review期间多次因为单元测试的问题重提代码(哭)。社区里面的开发者,尤其是项目的core,对待项目有着像对自己孩子般的认真与细致:他们会在一个自己根本不会在意的地方提醒你、面对当前的问题他们会延伸的考虑类似的问题。他们的态度让我首先感受到的吃惊,然后是敬佩! 经历八次review、历时近一个月,我的代码总算是入库了!希望我的这篇记录能对你有帮助。 感谢休伦公司技术总监 孙琦 提供的英文支持,社区大牛Alex Xu给出的修改建议。 Launchpad上面的bug提交:Abnormal changes of quota usage after instance restored by admin 代码审查过程:Fix abnormal quota usage after restore by admin Git@OSC中的代码:Fix abnormal quota usage after restore by admin 博文出处:http://my.oschina.net/zyzzy/blog/509315 关于OpenStack OpenStack是一个由NASA(美国国家航空航天局)和Rackspace合作研发并发起的,是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。 OpenStack除了有Rackspace和NASA的大力支持外,还有包括戴尔、Citrix、Cisco、Canonical等重量级公司的贡献和支持,致力于简化云的部署过程并为其带来良好的可扩展性。 本文作者:YueZheng 来源:51CTO