TiDB 之 TiCDC6.0 初体验
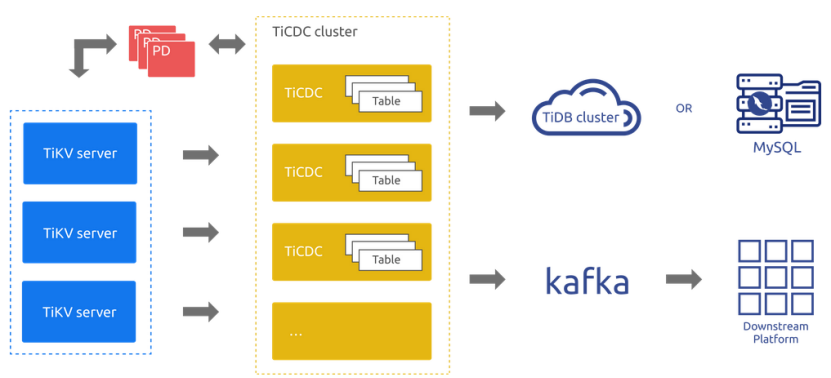
作者: JiekeXu 原文来源:https://tidb.net/blog/2dc4482b TiCDC 是一款 TiDB 增量数据同步工具,通过拉取上游 TiKV 的数据变更日志,具有将数据还原到与上游任意时刻一致的能力,同时提供开放数据协议(TiCDC Open Protocol),支持其他系统订阅数据变更,TiCDC 可以将数据解析为有序的行级变更数据输出到下游。 TiCDC 的系统架构如下图所示: TiCDC 运行时是一种无状态节点,通过 PD 内部的 etcd 实现高可用。TiCDC 集群支持创建多个同步任务,向多个不同的下游进行数据同步。 系统角色 TiKV CDC 组件:只输出 key-value (KV) change log。 o内部逻辑拼装 KV change log。 o提供输出 KV change log 的接口,发送数据包括实时 change log 和增量扫的 change log。 capture:TiCDC 运行进程,多个 capture 组成一个 TiCDC 集群,负责 KV change log 的同步。 o每个 capture 负责拉取一部分 KV change log。 o对拉取的一个或多个 KV change log 进行排序。 o向下游还原事务或按照 TiCDC Open Protocol 进行输出。 原理 原理:TiDB Server 负责接收 SQL,然后调用 TiKV 各个节点,然后输出自己节点的改变日志,然后将日志传到 TiCDC 集群,每个集群的 Capture 实际上为 TiCDC 节点,TiCDC 在内部逻辑拼装接收到的日志,提供输出日志的接口,发送到下游的 MySQL、Kafka 等。 每个 Capture 负责拉取一部分日志,然后自己排序,各个 capture 协同将自己接收的日志发送给capture 选择出来的owner,owner 进一步将日志排序,发送给目标下游端。 TiCDC 适用场景 TiCDC 适合源数据库为 TiDB,目标数据库支持 MySQL 兼容的任何数据库和 Kafka,同时 TiCDC Open Protocol 是一种行级别的数据变更通知协议,为监控、缓存、全文索引、分析引擎、异构数据库的主从复制等提供数据源。 数据库灾备:TiCDC 可以用于同构数据库之间的灾备场景,能够在灾难发生时保证主备集群数据的最终一致性,目前该场景仅支持 TiDB 作为主备集群。 数据集成:TiCDC 提供 TiCDC Canal-JSON Protocol,支持其他系统订阅数据变更,能够为监控、缓存、全文索引、数据分析、异构数据库的主从复制等场景提供数据源。 生产环境推荐配置 一般生产环境最低需要两台 16c 64G SSD 硬盘 万兆网卡的机器资源,如果是测试、学习环境,配置不需要这么高,也可以使用一个节点。 TiCDC环境部署 一般分两种情况:可以前期随 TiDB 一起部署,也可以后期进行扩容部署。 前期使用 tiup 部署 可以在 topology.yaml 文件中增加 tiup cluster deploy jiekexu-tidb v6.0.0 ./topology.yaml --user root -p cdc_servers 约定了将 TiCDC 服务部署到哪些机器上,同时可以指定每台机器上的服务配置。 gc-ttl:TiCDC 在 PD 设置的服务级别 GC safepoint 的 TTL (Time To Live) 时长,单位为秒,默认值为 86400,即 24 小时。 port:TiCDC 服务的监听端口,默认 8300 后期扩容 TiCDC 根据 保姆级分布式数据库 TiDB 6.0 集群安装手册 检查集群状态 tiup cluster status jiekexu-tidb 如果没有启动集群,需要先启动 tiup cluster start jiekexu-tidb 编辑扩容配置文件,准备将 TiCDC 节点 192.168.75.15/16 加入到集群中去. vim scale-out.yaml cdc_servers: - host: 192.168.75.15 gc-ttl: 86400 data_dir: /tidb-data/cdc-data/cdc-8300 - host: 192.168.75.16 gc-ttl: 86400 data_dir: /tidb-data/cdc-data/cdc-8300 加入 2 个 TiCDC 节点,IP 为 192.168.75.15/16,端口默认 8300,软件部署默认在 /tidb-deploy/cdc-8300 中,日志部署在 /tidb-deploy/cdc-8300/log 中,数据目录在 /tidb-data/cdc-data/cdc-8300 中。 使用 tiup 为原有 TiDB 数据库集群扩容 TiCDC 节点。 tiup cluster scale-out jiekexu-tidb scale-out.yaml -uroot -p [root@jiekexu1 ~]# tiup cluster scale-out jiekexu-tidb scale-out.yaml -uroot -p tiup is checking updates for component cluster ... Starting component `cluster`: /root/.tiup/components/cluster/v1.10.2/tiup-cluster scale-out jiekexu-tidb scale-out.yaml -uroot -p Input SSH password: + Detect CPU Arch Name - Detecting node 192.168.75.15 Arch info ... Done - Detecting node 192.168.75.16 Arch info ... Done + Detect CPU OS Name - Detecting node 192.168.75.15 OS info ... Done - Detecting node 192.168.75.16 OS info ... Done Please confirm your topology: Cluster type: tidb Cluster name: jiekexu-tidb Cluster version: v6.0.0 Role Host Ports OS/Arch Directories ---- ---- ----- ------- ----------- cdc 192.168.75.15 8300 linux/x86_64 /tidb-deploy/cdc-8300,/tidb-data/cdc-data/cdc-8300 cdc 192.168.75.16 8300 linux/x86_64 /tidb-deploy/cdc-8300,/tidb-data/cdc-data/cdc-8300 Attention: 1. If the topology is not what you expected, check your yaml file. 2. Please confirm there is no port/directory conflicts in same host. Do you want to continue? [y/N]: (default=N) y + [ Serial ] - SSHKeySet: privateKey=/root/.tiup/storage/cluster/clusters/jiekexu-tidb/ssh/id_rsa, publicKey=/root/.tiup/storage/cluster/clusters/jiekexu-tidb/ssh/id_rsa.pub + [Parallel] - UserSSH: user=tidb, host=192.168.75.16 + [Parallel] - UserSSH: user=tidb, host=192.168.75.14 + [Parallel] - UserSSH: user=tidb, host=192.168.75.15 + [Parallel] - UserSSH: user=tidb, host=192.168.75.13 + [Parallel] - UserSSH: user=tidb, host=192.168.75.12 + [Parallel] - UserSSH: user=tidb, host=192.168.75.11 + [Parallel] - UserSSH: user=tidb, host=192.168.75.17 + [Parallel] - UserSSH: user=tidb, host=192.168.75.17 + [Parallel] - UserSSH: user=tidb, host=192.168.75.17 + [Parallel] - UserSSH: user=tidb, host=192.168.75.17 + Download TiDB components - Download cdc:v6.0.0 (linux/amd64) ... Done + Initialize target host environments + Deploy TiDB instance - Deploy instance cdc -> 192.168.75.15:8300 ... Done - Deploy instance cdc -> 192.168.75.16:8300 ... Done + Copy certificate to remote host ……………………省略中间信息…………………… + Refresh components conifgs - Generate config pd -> 192.168.75.12:2379 ... Done - Generate config pd -> 192.168.75.13:2379 ... Done - Generate config pd -> 192.168.75.14:2379 ... Done - Generate config tikv -> 192.168.75.15:20160 ... Done - Generate config tikv -> 192.168.75.16:20160 ... Done - Generate config tikv -> 192.168.75.17:20160 ... Done - Generate config tidb -> 192.168.75.11:4000 ... Done - Generate config cdc -> 192.168.75.15:8300 ... Done - Generate config cdc -> 192.168.75.16:8300 ... Done - Generate config prometheus -> 192.168.75.17:9090 ... Done - Generate config grafana -> 192.168.75.17:3000 ... Done - Generate config alertmanager -> 192.168.75.17:9093 ... Done + Reload prometheus and grafana - Reload prometheus -> 192.168.75.17:9090 ... Done - Reload grafana -> 192.168.75.17:3000 ... Done + [ Serial ] - UpdateTopology: cluster=jiekexu-tidb Scaled cluster `jiekexu-tidb` out successfully 部署完成后检查集群状态,发现 TiCDC 已经部署到两节点了。我们看到 TiCDC 集群的 ID 为 192.168.75.15:8300, 192.168.75.16:8300,Status(状态)为 UP,表示 TiCDC 部署成功。 执行缩容操作 tiup cluster scale-in jiekexu-tidb --node 192.168.75.15:8300 这里仅下掉 75.15其中 --node 参数为需要下线节点的 ID。预期输出 Scaled cluster jiekexu-tidb in successfully 信息,表示缩容操作成功。 TiCDC 管理工具初尝试 cdc cli 是指通过 cdc binary 执行 cli 子命令,在以下接口描述中,通过 cdc binary 直接执行 cli 命令,PD 的监听 IP 地址为 192.168.75.12,端口2379。 使用 tiup ctl:v6.0.0 cdc 检查 TiCDC 的状态,如下: tiup ctl:v6.0.0 cdc capture list --pd=http://192.168.75.12:2379 命令中 --pd==http://192.168.75.12:2379,可以是任何一个 PD 节点,“is-owner”: true 代表当 TiCDC 节点为 owner 节点。为 false 代表备节点。 如果使用 TiUP 工具部署 TiCDC,那么则使用 TiUP 管理,命令可以写成 tiup cdc cli 数据同步准备 首先下游需要 MySQL 数据库,并为 MySQL 数据库( 端口号为 3306 )加入时区信息,创建数据库 jiekexu,并创建表 T1 ,注意不插入数据,如下操作: 192.168.75.12 已经安装好 MySQL5.7.38 数据库实例。 su – mysql mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root -p mysql -S /mysql/data/mysql3306/socket/mysql3306.sock mysql -uroot -p -P 3306 -S /mysql/data/mysql3306/socket/mysql3306.sock create database jiekexu; use jiekexu; create table T1(id int primary key, name varchar(20)); select * from T1; 然后 TiDB 端数据库准备 create database jiekexu; use jiekexu; create table T1(id int primary key, name varchar(20)); select * from T1; 创建同步任务 cd /tidb-deploy/cdc-8300/bin ./cdc cli changefeed create --pd=http://192.168.75.12:2379 --sink-uri="mysql://root:root@192.168.75.12:3306/" --changefeed-id="simple-replication-task" --sort-engine="unified" [WARN] some tables are not eligible to replicate, []model.TableName{model.TableName{Schema:"test", Table:"t1", TableID:0, IsPartition:false}} Could you agree to ignore those tables, and continue to replicate [Y/N] Y Create changefeed successfully! ID: simple-replication-task Info: {"sink-uri":"mysql://root:root@192.168.75.12:3306/","opts":{"_changefeed_id":"sink-verify"},"create-time":"2022-06-30T00:14:25.821140534+08:00","start-ts":434246584426037251,"target-ts":0,"admin-job-type":0,"sort-engine":"unified","sort-dir":"","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["*.*"],"ignore-txn-start-ts":null},"mounter":{"worker-num":16},"sink":{"dispatchers":null,"protocol":"","column-selectors":null},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"scheduler":{"type":"table-number","polling-time":-1},"consistent":{"level":"none","max-log-size":64,"flush-interval":1000,"storage":""}},"state":"normal","error":null,"sync-point-enabled":false,"sync-point-interval":600000000000,"creator-version":"v6.0.0"} 说明: –changefeed-id:同步任务的 ID,格式需要符合正则表达式 [1]+(-[a-zA-Z0-9]+)*$。如果不指定该 ID,TiCDC 会自动生成一个 UUID(version 4 格式)作为 ID。 –sink-uri:同步任务下游的地址,需要按照以下格式进行配置,目前 scheme 支持 mysql/tidb/kafka/pulsar。 –sort-engine:指定 changefeed 使用的排序引擎。因 TiDB 和 TiKV 使用分布式架构,TiCDC 需要对数据变更记录进行排序后才能输出。该项支持 unified(默认)/memory/file: unified:优先使用内存排序,内存不足时则自动使用硬盘暂存数据。该选项默认开启。 memory:在内存中进行排序。 不建议使用,同步大量数据时易引发 OOM。 file:完全使用磁盘暂存数据。已经弃用,不建议在任何情况使用。 查看同步任务 ./cdc cli changefeed list --pd=http://192.168.75.12:2379 [ { "id": "simple-replication-task", "summary": { "state": "normal", "tso": 434246659203137537, "checkpoint": "2022-06-30 00:19:03.469", "error": null } } ] 注意:“state”: “normal” : 表示任务状态正常。 “tso”: 434246659203137537: 表示同步任务的时间戳信息。 “checkpoint”: “2022-06-30 00:19:03.469” :表示同步任务的时间。 详细查询复制任务信息 { "info": { "sink-uri": "mysql://root:root@192.168.75.12:3306/", "opts": { "_changefeed_id": "sink-verify" }, "create-time": "2022-06-30T00:14:25.821140534+08:00", "start-ts": 434246584426037251, "target-ts": 0, "admin-job-type": 0, "sort-engine": "unified", "sort-dir": "", "config": { "case-sensitive": true, "enable-old-value": true, "force-replicate": false, "check-gc-safe-point": true, "filter": { "rules": [ "*.*" ], "ignore-txn-start-ts": null }, "mounter": { "worker-num": 16 }, "sink": { "dispatchers": null, "protocol": "", "column-selectors": null }, "cyclic-replication": { "enable": false, "replica-id": 0, "filter-replica-ids": null, "id-buckets": 0, "sync-ddl": false }, "scheduler": { "type": "table-number", "polling-time": -1 }, "consistent": { "level": "none", "max-log-size": 64, "flush-interval": 1000, "storage": "" } }, "state": "normal", "error": null, "sync-point-enabled": false, "sync-point-interval": 600000000000, "creator-version": "v6.0.0" }, "status": { "resolved-ts": 434246739838369793, "checkpoint-ts": 434246739313819649, "admin-job-type": 0 }, "count": 0, "task-status": [ { "capture-id": "9163a533-97e2-4b64-838a-139c70ea89f3", "status": { "tables": null, "operation": null, "admin-job-type": 0 } }, { "capture-id": "6155ee47-1e22-4369-b2b7-670c43b11b46", "status": { "tables": null, "operation": null, "admin-job-type": 0 } } ] } 数据同步测试 对于同步任务进行验证,登录 TiDB 数据库,查询刚刚创建的 jiekexu 数据库下面的表 T1,并且插入三行数据,如下所示: 源端插入数据 insert into T1 values(1,'jiekexu'); insert into T1 values(2,'jiekexu dba'); insert into T1 values(2,'jiekexu tidb'); select * from T1; 登录 MySQL 数据库,查询 jiekexu 数据库下面的表 T1,发现数据库已经同步过去,如下所示: mysql> select * from T1; +----+--------------+ | id | name | +----+--------------+ | 1 | jiekexu | | 2 | jiekexu dba | | 3 | jiekexu tidb | +----+--------------+ 3 rows in set (0.00 sec) 源端更新、删除数据 mysql> update T1 set name='jiekexu tidb dba' where id=3; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from T1; +----+------------------+ | id | name | +----+------------------+ | 1 | jiekexu | | 2 | jiekexu dba | | 3 | jiekexu tidb dba | +----+------------------+ 3 rows in set (0.00 sec) mysql> delete from T1 where id=1; Query OK, 1 row affected (0.01 sec) mysql> select * from T1; +----+------------------+ | id | name | +----+------------------+ | 2 | jiekexu dba | | 3 | jiekexu tidb dba | +----+------------------+ 2 rows in set (0.01 sec) 目标端 MySQL 端查看 mysql> select * from T1; +----+------------------+ | id | name | +----+------------------+ | 1 | jiekexu | | 2 | jiekexu dba | | 3 | jiekexu tidb dba | +----+------------------+ 3 rows in set (0.00 sec) mysql> select * from T1; +----+------------------+ | id | name | +----+------------------+ | 2 | jiekexu dba | | 3 | jiekexu tidb dba | +----+------------------+ 2 rows in set (0.00 sec) 源端添加、修改、删除列 alter table T1 add addr varchar(50); alter table T1 modify name varchar(32); alter table t1 add changeTime datetime default now(); Alter table t1 drop column changeTime; 目标端查看也能正常同步。 源端新建表数据插入测试 CREATE TABLE `Test` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `addr` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) ); insert into Test values(1,'jiekexu','beijing'); 目标端 MySQL 端查看 停止同步任务 ./cdc cli changefeed --help Manage changefeed (changefeed is a replication task) Usage: cdc cli changefeed [flags] cdc cli changefeed [command] Available Commands: create Create a new replication task (changefeed) cyclic (Experimental) Utility about cyclic replication list List all replication tasks (changefeeds) in TiCDC cluster pause Pause a replication task (changefeed) query Query information and status of a replication task (changefeed) remove Remove a replication task (changefeed) resume Resume a paused replication task (changefeed) statistics Periodically check and output the status of a replication task (changefeed) update Update config of an existing replication task (changefeed) ./cdc cli changefeed pause --pd=192.168.75.12:2379 --changefeed-id simple-replication-task ./cdc cli changefeed pause --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-task 注意:pause 停止任务时,pd 后面也可以不跟 http:// 协议,不会报错。 恢复同步任务 ./cdc cli changefeed resume --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-task 注意:Pd 后面需要跟 http 协议,不然会报错。 删除同步任务 ./cdc cli changefeed remove --pd=http://192.168.75.12:2379 --changefeed-id simple-replication-task TiCDC 的限制 有效索引的相关要求 TiCDC 只能同步至少存在一个有效索引的表,有效索引的定义如下: 主键 (PRIMARY KEY) 为有效索引。 同时满足下列条件的唯一索引 (UNIQUE INDEX) 为有效索引: 索引中每一列在表结构中明确定义非空 (NOT NULL)。 索引中不存在虚拟生成列 (VIRTUAL GENERATED COLUMNS)。 TiCDC 从 4.0.8 版本开始,可通过修改任务配置来同步没有有效索引的表,但在数据一致性的保证上有所减弱。具体使用方法和注意事项参考同步没有有效索引的表。 暂不支持的场景 目前 TiCDC 暂不支持的场景如下: 暂不支持单独使用 RawKV 的 TiKV 集群。 暂不支持在 TiDB 中创建 SEQUENCE 的 DDL 操作和 SEQUENCE 函数。在上游 TiDB 使用 SEQUENCE 时,TiCDC 将会忽略掉上游执行的 SEQUENCE DDL 操作/函数,但是使用 SEQUENCE 函数的 DML 操作可以正确地同步。 对上游存在较大事务的场景提供部分支持,详见 TiCDC 是否支持同步大事务?有什么风险吗? 参考链接: https://docs.pingcap.com/zh/tidb/v6.0/ticdc-overview https://learn.pingcap.com/learner/course/30002