Haproxy+keepalived 高可用负载
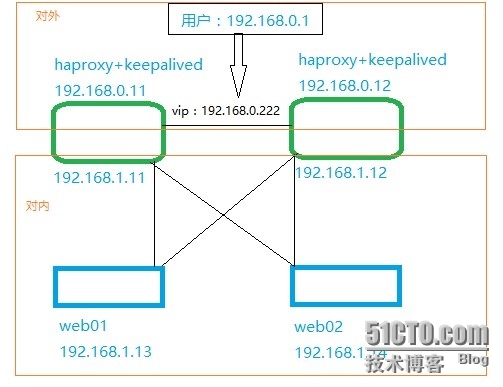
Haproxy+keepalived+apache 一、拓扑图: 二、编译安装haproxy(两台机器一样安装) 解压:tar zxvf haproxy-1.6.4.tar.gz 编译:注意:下边的等号前边的参数必须大写 cd haproxy-1.6.4 make TARGET=linux26 ARCH=x86_64 PREFIX=/usr/local/haproxy make install PREFIX=/usr/local/haproxy 安装后,创建配置文件和启动文件 mkdir -p /usr/local/haproxy/etc/haproxy cp examples/acl-content-sw.cfg/usr/local/haproxy/etc/haproxy/haproxy.cfg cp examples/haproxy.init /etc/init.d/haproxy chmod +x /etc/init.d/haproxy 修改启动文件: vi /etc/init.d/haproxy 修改BIN、CFG路径 BIN=/usr/local/haproxy/sbin/$BASENAME CFG=/usr/local/etc/$BASENAME/$BASENAME.cfg 三、编辑配置文件(两台机器一样) cd /usr/local/haproxy/etc/haproxy cp haproxy.cfg haproxy.cfg.bak vi haproxy.cfg # This sampleconfiguration makes extensive use of the ACLs. It requires # HAProxyversion 1.3.12 minimum. global log localhost local3 maxconn 250 uid 71 gid 71 chroot /usr/local/haproxy pidfile /var/run/haproxy.pid daemon quiet frontendhttp-in bind :80 mode http log global clitimeout 30000 option httplog option dontlognull #option logasap option httpclose maxconn 100 stats refresh 30s stats uri /stats stats realm linuxidc-test-Haproxy stats auth admin:admin123 stats hide-version capture request header Host len 20 capture request header User-Agent len 16 capture request header Content-Length len 10 capture request header Referer len 20 capture response header Content-Lengthlen 10 # block any unwanted source IPaddresses or networks acl forbidden_src src 0.0.0.0/7 224.0.0.0/3 acl forbidden_src src_port 0:1023 block if forbidden_src # block requests beginning with http://on wrong domains acl dangerous_pfx url_beg -ihttp:// acl valid_pfx url_reg -i ^http://[^/]*1wt\.eu/ block if dangerous_pfx !valid_pfx # block apache chunk exploit, ... acl forbidden_hdrshdr_sub(transfer-encoding) -i chunked acl forbidden_hdrs hdr_beg(host) -i apache- localhost # ... some HTTP content smugling andother various things acl forbidden_hdrs hdr_cnt(host) gt 1 acl forbidden_hdrshdr_cnt(content-length) gt 1 acl forbidden_hdrshdr_val(content-length) lt 0 acl forbidden_hdrshdr_cnt(proxy-authorization) gt 0 block if forbidden_hdrs # block annoying worms that fill thelogs... acl forbidden_uris url_reg -i.*(\.|%2e)(\.|%2e)(%2f|%5c|/|\\\\) acl forbidden_uris url_sub -i %00<script xmlrpc.php acl forbidden_uris path_end -i/root.exe /cmd.exe /default.ida /awstats.pl .asp .dll # block other common attacks (awstats,manual discovery...) acl forbidden_uris path_dir -i chatmain.php read_dump.php viewtopic.php phpbb sumthin horde _vti_bin M SOffice acl forbidden_uris url_reg -i(\.php\?temppath=|\.php\?setmodules=|[=:]http://) block if forbidden_uris # we rewrite the "options"request so that it only tries '*', and we # only report GET, HEAD, POST andOPTIONS as valid methods reqirep ^OPTIONS\ /.*HTTP/1\.[01]$ OPTIONS\\\*\ HTTP/1.0 rspirep ^Allow:\ .* Allow:\ GET,\ HEAD,\POST,\ OPTIONS acl web hdr_beg(host) -i www.abc.com use_backend wwwif web backend www modehttp #source 192.168.11.13:0 balance roundrobin cookie SERVERID server web01 192.168.1.13:80 checkinter 30000 fall 3 weight 10 server web02 192.168.1.14:80 checkinter 30000 fall 3 weight 10 # long timeout to support connectionqueueing contimeout 20000 srvtimeout 20000 fullconn 100 redispatch retries 3 option httpchk HEAD / option forwardfor option checkcache option httpclose # allow other syntactically validrequests, and block any other method acl valid_method method GET HEAD POSTOPTIONS block if !valid_method block if HTTP_URL_STAR !METH_OPTIONS block if !HTTP_URL_SLASH !HTTP_URL_STAR!HTTP_URL_ABS # remove unnecessary precisions on theserver version. Let's say # it's an apache under Unix on theFormilux Distro. rspidel ^Server:\ rspadd Server:\ Apache\ (Unix;\Formilux/0.1.8) # end ofdefaults 配置日志相关步骤 haproxy.cfg 上边已经配置 log localhost local3 vi /etc/rsyslog.conf 去掉#号 $ModLoad imudp $UDPServerRun 514 在local7.*下边添加以下内容: local3.* /var/log/haproxy/haproxy.log vi /etc/sysconfig/rsyslog 修改为: SYSLOGD_OPTIONS="-r -m 0" 重启rsyslog和haproxy服务service rsyslog restart service haproxy restart 日志文件:/var/log/haproxy/haproxy.log 查看haproxy状态信息http://ip/stats用户密码:admin:admin123 四、Web01和web02安装httpd yum –y install httpd 分别建立配置文件: Web01: vi /var/www/html/index.html Wo shi 13. Web02: vi /var/www/html/index.html Wo shi 14. 两台都执行以下配置: 关闭selinux vi /etc/sysconfig/selinux SELINUX=disabled 重启 service iptables stop chkconfig iptables off chkconfig httpd on service httpd start 浏览器测试是否都能打开web01和web02 五、编译安装keepalived 安装相关包:yum -y install openssl openssl-devel 解压:tar zxvf keepalived-1.2.20.tar.gz 编译cd keepalived-1.2.20./configure --prefix=/usr/local/keepalived1.2.20makemake install 配置启动文件:cd /usr/local/keepalived1.2.20/cp etc/rc.d/init.d/keepalived /etc/init.d/vi /etc/init.d/keepalived修改三处:. /usr/local/keepalived1.2.20/etc/sysconfig/keepalivedconfig="/usr/local/keepalived1.2.20/etc/keepalived/keepalived.conf"daemon keepalived -D -f $config 配置keepalived.conf文件cd etc/keepalived/备份:cp keepalived.conf keepalived.conf.bakvi keepalived.conf(注意两个配置文件有所不同)192.168.0.11的keepalived.conf ! Configuration File for keepalived global_defs { notification_email { 506@qq.com } notification_email_from postmaster@it.com smtp_server mail.it.com smtp_connect_timeout 30 router_id LVS_01 } vrrp_script chk_haproxy { script "/usr/local/keepalived1.2.20/check_haproxy.sh" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface eth2 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.0.222/24 } } 192.168.0.12的keepalived.conf ! Configuration File for keepalived global_defs { notification_email { 506@qq.com } notification_email_from postmaster@it.com smtp_server mail.it.com smtp_connect_timeout 30 router_id LVS_01 } vrrp_script chk_haproxy { script "/usr/local/keepalived1.2.20/check_haproxy.sh" interval 2 weight 2 } vrrp_instance VI_1 { state BACKUP interface eth2 virtual_router_id 51 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.0.222/24 } } ln -s/usr/local/keepalived1.2.20/sbin/keepalived /usr/sbin/ 开启路由功能 net.ipv4.ip_forward= 1 开启IP转发功能 net.ipv4.ip_nonlocal_bind= 1 开启允许绑定非本机的IP 如果使用LVS的DR或者TUN模式结合Keepalived需要在后端真实服务器上特别设置两个arp相关的参数。这里也设置好。 net.ipv4.conf.lo.arp_ignore= 1 net.ipv4.conf.lo.arp_announce= 2 net.ipv4.conf.all.arp_ignore= 1 net.ipv4.conf.all.arp_announce= 2 创建防止haproxy服务关闭导致keepalived不自动切换脚本 cat /usr/local/keepalived1.2.20/check_haproxy.sh #!/bin/bash if [ $(ps-C haproxy --no-header | wc -l) -eq 0 ]; then /etc/init.d/haproxy start fi sleep 2 if [ $(ps-C haproxy --no-header | wc -l) -eq 0 ]; then /etc/init.d/keepalived stop fi 启动服务 service keepalived restart ip addr查看有没有创建vip 这时候备的keepalived是没有vip地址的: 当主keepalived断掉,备keepalived接管vip(这里停止服务模仿) 当keepalived切换的时候,ping会丢一个包: 当主keepalived关掉的时候,丢包: 当主keepalived恢复的时候,丢包: 六、Haproxy本机测试www.abc.com访问 由于是测试没有dns解析,临时做hosts解析记录: 测试:curl www.abc.com测试两次,实现轮询 七、客户端测试www.abc.com Windows客户端测试,添加hosts记录 浏览器访问www.abc.com访问两次,也成功实现轮询