Apache Storm 官方文档 —— 理解 Storm 拓扑的并行度(parallelism)概念
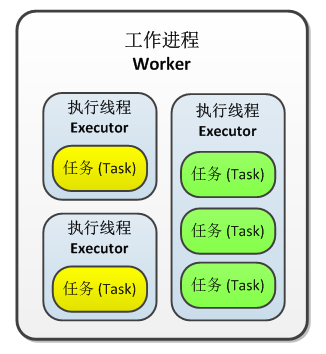
一个运行中的拓扑是由什么构成的:工作进程(worker processes),执行器(executors)和任务(tasks) 在一个 Storm 集群中,Storm 主要通过以下三个部件来运行拓扑: 工作进程(worker processes) 执行器(executors) 任务(tasks) 下面是他们之间相互关系的简单图示。 在 Worker 中运行的是拓扑的一个子集。一个 worker 进程是从属于某一个特定的拓扑的,在 worker 进程中会运行一个或者多个与拓扑中的组件相关联的 executor。一个运行中的拓扑就是由这些运行于 Storm 集群中的很多机器上的进程组成的。 一个 executor 是由 worker 进程生成的一个线程。在 executor 中可能会有一个或者多个 task,这些 task 都是为同一个组件(spout 或者 bolt)服务的。 task 是实际执行数据处理的最小工作单元(注意,task 并不是线程) —— 在你的代码中实现的每个 spout 或者 bolt 都会在集群中运行很多个 task。在拓扑的整个生命周期中每个组件的 task 数量都是保持不变的,不过每个组件的 executor 数量却是有可能会随着时间变化。在默认情况下 task 的数量是和 executor 的数量一样的,也就是说,默认情况下 Storm 会在每个线程上运行一个 task。 配置拓扑的并行度(parallelism) 注意,这里所说的术语“并行度”主要是用于表示所谓的parallelism_hint,它代表着一个组件的初始 executor (也是线程)数量。在这篇文章里,我们使用这个“并行度”术语来说明在 Storm 拓扑中既可以配置 executor 的数量,也可以配置 worker 和 task 的数量。如果“并行度”的概念需要表示其他的一般情况,我们也会特别指出。 下面的内容里显示了很多可配置选项,以及在代码中配置他们的方法。可以用于配置的方法有很多种,这里列出的只是其中一部分。另外需要注意的是,Storm 的配置优先级为defaults.yaml<storm.yaml< 拓扑配置 < 内置型组件信息配置 < 外置型组件信息配置。 Worker 数量 说明:拓扑在集群中运行所需要的工作进程数 配置选项:TOPOLOGY_WORKERS 在代码中如何使用(示例): Config#setNumWorkers Executors(线程)数量 说明:每个组件需要的执行线程数 配置选项:(没有拓扑级的通用配置项) 在代码中如何使用(示例): TopologyBuilder#setSpout() TopologyBuilder#setBolt() 注意:从 Storm 0.8 开始parallelism_hint参数代表 executor 的数量,而不是 task 的数量 Tasks 数量 说明:每个组件需要的执行任务数 配置选项:TOPOLOGY_TASKS 在代码中如何使用(示例): ComponentConfigurationDeclarer#setNumTasks() 以下是配置上述参数的一个简单示例代码: topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout); 在上面的代码中,我们为GreenBolt配置了 2 个初始执行线程(executor)和 4 个关联任务(task)。这样,每个执行线程中会运行 2 个任务。如果你在设置 bolt 的时候不指定 task 的数量,那么每个 executor 的 task 数会默认设置为 1。 拓扑示例 下图显示了一个与实际应用场景很接近的简单拓扑的结构。这个拓扑由三个组件构成:一个名为BlueSpout的 spout,和两个名为GreenBolt和YellowBolt的 bolt。这些组件之间的关系是:BlueSpout将它的输出发送到GreenBolt中,然后GreenBolt将消息继续发送到YellowBolt中。 图中是一个包含有两个 worker 进程的拓扑。其中,蓝色的BlueSpout有两个 executor,每个 executor 中有一个 task,并行度为 2;绿色的GreenBolt有两个 executor,每个 executor 有两个 task,并行度也为2;而黄色的YellowBolt有 6 个 executor,每个 executor 中有一个 task,并行度为 6,因此,这个拓扑的总并行度就是 2 + 2 + 6 = 10。具体分配到每个 worker 就有 10 / 2 = 5 个 executor。 上图中,GreenBolt配置了 task 数,而BlueSpout和YellowBolt仅仅配置了 executor 数。下面是相关代码: Config conf = new Config(); conf.setNumWorkers(2); // use two worker processes topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2 topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout"); topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6) .shuffleGrouping("green-bolt"); StormSubmitter.submitTopology( "mytopology", conf, topologyBuilder.createTopology() ); 当然,Storm 还有一些其他的配置项可以控制拓扑的并行度,包括: TOPOLOGY_MAX_TASK_PARALLELISM:该选项设置了一个组件最多能够分配的 executor 数(线程数上限),一般用于在本地模式运行拓扑时测试分配线程的数量限制。你可以通过Config#setMaxTaskParallelism()来配置该参数。 如何修改运行中的拓扑的并行度 Storm 的一个很有意思的特点是你可以随时增加或者减少 worker 或者 executor 的数量,而不需要重启集群或者拓扑。这个方法就叫做再平衡(rebalance)。 有两种方法可以对一个拓扑执行再平衡操作: 使用 Storm UI 使用以下所示的客户端(CLI)工具 下面是使用 CLI 工具的一个简单示例: ## 重新配置拓扑 "mytopology",使得该拓扑拥有 5 个 worker processes, ## 另外,配置名为 "blue-spout" 的 spout 使用 3 个 executor, ## 配置名为 "yellow-bolt" 的 bolt 使用 10 个 executor。 $ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 转载自并发编程网 - ifeve.com