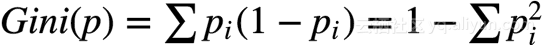SparkML机器学习之特征工程(二)特征转化(Binarizer、StandardScaler、MaxAbsScaler、Normaliz...
特征转化 为什么要转化数据呢,就是要让它成为有效的特征,因为原始数据是很多脏数据无用数据的。常用的方法是标准化,归一化,特征的离散化等等。比如我输入的数据是句子,我得把它切分为一个个单词进行分析,这就是一种转化。 连续型数据处理之二值化:Binarizer 假设淘宝现在有个需求,我得根据年龄来进行物品推荐,把50以上的人分为老年,50以下分为非老年人,那么我们根据二值化可以很简单的把50以上的定为1,50以下的定为0。这样就方便我们后续的推荐了。Binarizer就是根据阈值进行二值化,大于阈值的为1.0,小于等于阈值的为0.0 package ml.test import org.apache.spark.ml.feature.Binarizer import org.apache.spark.sql.SparkSession /** * Created by liuyanling on 2018/3/19 */ object BinarizerDemo { def main(args: Array[String]): Unit = { var spark = SparkSession.builder().appName("BinarizerDemo").master("local[2]").getOrCreate(); val array = Array((1,34.0),(2,56.0),(3,58.0),(4,23.0)) //将数组转为DataFrame val df = spark.createDataFrame(array).toDF("id","age") //初始化Binarizer对象并进行设定:setThreshold是设置我们的阈值,InputCol是设置需要进行二值化的输入列,setOutputCol设置输出列 val binarizer = new Binarizer().setThreshold(50.0).setInputCol("age").setOutputCol("binarized_feature") //transform方法将DataFrame二值化。 val binarizerdf = binarizer.transform(df) //show是用于展示结果 binarizerdf.show } } 输出结果: +---+----+-----------------+ | id| age|binarized_feature| +---+----+-----------------+ | 1|34.0| 0.0| | 2|56.0| 1.0| | 3|58.0| 1.0| | 4|23.0| 0.0| +---+----+-----------------+ 连续型数据处理之给定边界离散化:Bucketizer 现在淘宝的需求变了,他们觉得把人分为50以上和50以下太不精准了,应该分为20岁以下,20-30岁,30-40岁,36-50岁,50以上,那么就得用到数值离散化的处理方法了。离散化就是把特征进行适当的离散处理,比如上面所说的年龄是个连续的特征,但是我把它分为不同的年龄阶段就是把它离散化了,这样更利于我们分析用户行为进行精准推荐。Bucketizer能方便的将一堆数据分成不同的区间。 object BucketizerDemo { def main(args: Array[String]): Unit = { var spark = SparkSession.builder().appName("BucketizerDemo").master("local[2]").getOrCreate(); val array = Array((1,13.0),(2,16.0),(3,23.0),(4,35.0),(5,56.0),(6,44.0)) //将数组转为DataFrame val df = spark.createDataFrame(array).toDF("id","age") // 设定边界,分为5个年龄组:[0,20),[20,30),[30,40),[40,50),[50,正无穷) // 注:人的年龄当然不可能正无穷,我只是为了给大家演示正无穷PositiveInfinity的用法,负无穷是NegativeInfinity。 val splits = Array(0, 20, 30, 40, 50, Double.PositiveInfinity) //初始化Bucketizer对象并进行设定:setSplits是设置我们的划分依据 val bucketizer = new Bucketizer().setSplits(splits).setInputCol("age").setOutputCol("bucketizer_feature") //transform方法将DataFrame二值化。 val bucketizerdf = bucketizer.transform(df) //show是用于展示结果 bucketizerdf.show } } 输出结果: +---+----+------------------+ | id| age|bucketizer_feature| +---+----+------------------+ | 1|13.0| 0.0| | 2|16.0| 0.0| | 3|23.0| 1.0| | 4|35.0| 2.0| | 5|56.0| 4.0| | 6|44.0| 3.0| +---+----+------------------+ 连续型数据处理之给定分位数离散化:QuantileDiscretizer 有时候我们不想给定分类标准,可以让spark自动给我们分箱。 object QuantileDiscretizerDemo { def main(args: Array[String]): Unit = { var spark = SparkSession.builder().appName("QuantileDiscretizerDemo").master("local[2]").getOrCreate(); val array = Array((1,13.0),(2,14.0),(3,22.0),(4,35.0),(5,44.0),(6,56.0),(7,21.0)) val df = spark.createDataFrame(array).toDF("id","age") //和Bucketizer类似:将连续数值特征转换离散化。但这里不再自己定义splits(分类标准),而是定义分几箱就可以了。 val quantile = new QuantileDiscretizer().setNumBuckets(5).setInputCol("age").setOutputCol("quantile_feature") //因为事先不知道分桶依据,所以要先fit,相当于对数据进行扫描一遍,取出分位数来,再transform进行转化。 val quantiledf = quantile.fit(df).transform(df) //show是用于展示结果 quantiledf.show } } 标准化 对于同一个特征,不同的样本中的取值可能会相差非常大,一些异常小或异常大的数据会误导模型的正确训练;另外,如果数据的分布很分散也会影响训练结果。以上两种方式都体现在方差会非常大。此时,我们可以将特征中的值进行标准差标准化,即转换为均值为0,方差为1的正态分布。如果特征非常稀疏,并且有大量的0(现实应用中很多特征都具有这个特点),Z-score 标准化的过程几乎就是一个除0的过程,结果不可预料。所以在训练模型之前,一定要对特征的数据分布进行探索,并考虑是否有必要将数据进行标准化。基于特征值的均值(mean)和标准差(standard deviation)进行数据的标准化。它的计算公式为:标准化数据=(原数据-均值)/标准差。标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。 StandardScaler object StandardScalerDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").getOrCreate() val df = spark.read.format("libsvm").load("libsvm_data.txt") //setWithMean是否减均值。setWithStd是否将数据除以标准差。这里就是没有减均值但有除以标准差 df.printSchema() val scaler =new StandardScaler().setInputCol("features").setOutputCol("scaledFeatures").setWithMean(false).setWithStd(true) // 计算均值方差等参数 val scalermodel = scaler.fit(df) // 标准化 scalermodel.transform(df).show() } } libsvm_data.txt label 标签,就是属于哪一类,即你要分类的种类,通常是一些整数。 index 是有顺序的索引,通常是连续的整数。就是指特征编号,必须按照升序排列 value 就是特征值,训练,通常是一堆实数组成。 格式:标签 第一维特征编号:第一维特征值 第二维特征编号:第二维特征值 …例: 0 1:1 2:2 1 1:2 2:4 归一化 为什么数据需要归一化?以房价预测为案例,房价(y)通常与离市中心距离(x1)、面积(x2)、楼层(x3)有关,设y=ax1+bx2+cx3,那么abc就是我们需要重点解决的参数。但是有个问题,面积一般数值是比较大的,100平甚至更多,而距离一般都是几公里而已,b参数只要一点变化都能对房价产生巨大影响,而a的变化对房价的影响相对就小很多了。显然这会影响最终的准确性,毕竟距离可是个非常大的影响因素啊。 所以, 需要使用特征的归一化, 取值跨度大的特征数据, 我们浓缩一下, 跨度小的括展一下, 使得他们的跨度尽量统一。归一化就是将所有特征值都等比地缩小到0-1或者-1到1之间的区间内。其目的是为了使特征都在相同的规模中。 绝对值最大标准化:MaxAbsScaler import org.apache.spark.ml.feature.MaxAbsScaler import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession /** * Created by LYL on 2018/3/20. */ object MaxAbsScalerDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName("MaxAbsScalerDemo").master("local[2]").getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(10.0, 0.1, -8.0)), (1, Vectors.dense(100.0, 1.0, -4.0)), (2, Vectors.dense(1000.0, 10.0, 8.0)) )).toDF("id", "features") val maxabs = new MaxAbsScaler().setInputCol("features").setOutputCol("maxabs_features") // fit作用是把所有值都扫描一遍,计算出最大最小值,比如1000的话那么absMax=1000。最后返回MaxAbsScalerModel val scalerModel = maxabs.fit(dataFrame) // 使用每个特征的最大值的绝对值将输入向量的特征值都缩放到[-1,1]范围内 val scalerdf = scalerModel.transform(dataFrame) scalerdf.show } } 运行结果: +---+-----------------+----------------+ | id| features| maxabs_features| +---+-----------------+----------------+ | 0| [10.0,0.1,-8.0]|[0.01,0.01,-1.0]| | 1| [100.0,1.0,-4.0]| [0.1,0.1,-0.5]| | 2|[1000.0,10.0,8.0]| [1.0,1.0,1.0]| +---+-----------------+----------------+ 归一化之最小最大值标准化MinMaxScaler import org.apache.spark.ml.feature.MinMaxScaler import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession /** * Created by LYL on 2018/3/20. */ object MinMaxScalerDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName("MinMaxScalerDemo").master("local[2]").getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(2.0, 0.9, -2.0)), (1, Vectors.dense(3.0, -2.0, -3.0)), (2, Vectors.dense(4.0, -2.0, 2.0)) )).toDF("id", "features") val maxabs = new MinMaxScaler().setInputCol("features").setOutputCol("minmax_features") val scalerModel = maxabs.fit(dataFrame) // 将所有值都缩放到[0,1]范围内 val scalerdf = scalerModel.transform(dataFrame) scalerdf.show } } 运行结果为: +---+---------------+---------------+ | id| features|minmax_features| +---+---------------+---------------+ | 0| [2.0,0.9,-2.0]| [0.0,1.0,0.2]| | 1|[3.0,-2.0,-3.0]| [0.5,0.0,0.0]| | 2| [4.0,-2.0,2.0]| [1.0,0.0,1.0]| +---+---------------+---------------+ 正则化Normalizer 为什么要有正则化?就是为了防止过拟合。来看一下正则化是怎么计算的: def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.5, -1.0)), (1, Vectors.dense(2.0, 1.0, 1.0)), (2, Vectors.dense(4.0, 10.0, 2.0)) )).toDF("id", "features") //setP是指L1正则化还是L2正则化,比如1.0就是上面说到的L1正则化,计算如下:1/(1+0.5+1) val normalizer = new Normalizer().setInputCol("features").setOutputCol("normalizer_features").setP(1.0) normalizer.transform(dataFrame).show(truncate = false) } 输出结果为: +---+--------------+-------------------+ |id |features |normalizer_features| +---+--------------+-------------------+ |0 |[1.0,0.5,-1.0]|[0.4,0.2,-0.4] | |1 |[2.0,1.0,1.0] |[0.5,0.25,0.25] | |2 |[4.0,10.0,2.0]|[0.25,0.625,0.125] | +---+--------------+-------------------+ N-gram N-Gram认为语言中每个单词只与其前面长度 N-1 的上下文有关。主要分为bigram和trigram,bigram假设下一个词的出现依赖它前面的一个词,trigram假设下一个词的出现依赖它前面的两个词。在SparkML中用NGram类实现,setN(2)为bigram,setN(3)为trigram。 def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").getOrCreate() val wordDataFrame = spark.createDataFrame(Seq( (0, Array("Hi", "I", "heard", "about", "Spark")), (1, Array("I", "wish", "Java", "could", "use", "case", "classes")), (2, Array("Logistic", "regression", "models", "are", "neat")) )).toDF("id", "words") val ngram2 = new NGram().setN(2).setInputCol("words").setOutputCol("ngrams") val ngram3 = new NGram().setN(3).setInputCol("words").setOutputCol("ngrams") ngram2.transform(wordDataFrame).show(false) ngram3.transform(wordDataFrame).show(false) } 输出结果为: +---+------------------------------------------+------------------------------------------------------------------+ |id |words |ngrams | +---+------------------------------------------+------------------------------------------------------------------+ |0 |[Hi, I, heard, about, Spark] |[Hi I, I heard, heard about, about Spark] | |1 |[I, wish, Java, could, use, case, classes]|[I wish, wish Java, Java could, could use, use case, case classes]| |2 |[Logistic, regression, models, are, neat] |[Logistic regression, regression models, models are, are neat] | +---+------------------------------------------+------------------------------------------------------------------+ 18/03/24 11:23:32 INFO CodeGenerator: Code generated in 14.198881 ms +---+------------------------------------------+--------------------------------------------------------------------------------+ |id |words |ngrams | +---+------------------------------------------+--------------------------------------------------------------------------------+ |0 |[Hi, I, heard, about, Spark] |[Hi I heard, I heard about, heard about Spark] | |1 |[I, wish, Java, could, use, case, classes]|[I wish Java, wish Java could, Java could use, could use case, use case classes]| |2 |[Logistic, regression, models, are, neat] |[Logistic regression models, regression models are, models are neat] | +---+------------------------------------------+--------------------------------------------------------------------------------+ 多项式转化PolynomialExpansion 有时候要对特征值进行一些多项式的转化,比如平方啊,三次方啊等等,那就用到了PolynomialExpansion。 object PolynomialExpansionDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").getOrCreate() val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 5.0)), (1, Vectors.dense(2.0, 1.0)), (2, Vectors.dense(4.0, 8.0)) )).toDF("id", "features") //setDegree表示多项式最高次幂 比如1.0,5.0可以是 三次:1.0^3 5.0^3 1.0+5.0^2 二次:1.0^2+5.0 1.0^2 5.0^2 1.0+5.0 一次:1.0 5.0 val po = new PolynomialExpansion().setDegree(3).setInputCol("features").setOutputCol("Polynomial_features") po.transform(dataFrame).show(truncate = false) } } 输出结果为: +---+---------+-----------------------------------------------+ |id |features |Polynomial_features | +---+---------+-----------------------------------------------+ |0 |[1.0,5.0]|[1.0,1.0,1.0,5.0,5.0,5.0,25.0,25.0,125.0] | |1 |[2.0,1.0]|[2.0,4.0,8.0,1.0,2.0,4.0,1.0,2.0,1.0] | |2 |[4.0,8.0]|[4.0,16.0,64.0,8.0,32.0,128.0,64.0,256.0,512.0]| +---+---------+-----------------------------------------------+ Tokenizer分词器 当我们的输入数据为文本(句子)的时候,我们会想把他们切分为单词再进行数据处理,这时候就要用到Tokenizer类了。 object TokenizerDemo { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").appName("TokenizerDemo").getOrCreate() val dataFrame = spark.createDataFrame(Seq((0, "Hello I am LYL"), (1, "I Love Bigdata"), (2, "1 2 3 4"))).toDF("id", "sentence") // Tokenization(分词器)是一个接受文本(通常是句子)输入,然后切分成单词。 val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words") tokenizer.transform(dataFrame).show() // RegexTokenizer(正则化分词器)基于正则表达式匹配提供了更多高级的分词功能。将gaps参数设置为false,表明使用正则表达式匹配标记,而不是使用分隔符。 // 此处\\d表示匹配数字。 val regextokenizer = new RegexTokenizer().setInputCol("sentence").setOutputCol("words").setGaps(false).setPattern("\\d") regextokenizer.transform(dataFrame).show() //使用udf函数 统计单词个数 val wordcount = udf { (word: Seq[String]) => word.length } tokenizer.transform(dataFrame).select("words").withColumn("wordcount", wordcount(col("words"))).show() } 输出结果为: +---+--------------+-------------------+ | id| sentence| words| +---+--------------+-------------------+ | 0|Hello I am LYL|[hello, i, am, lyl]| | 1|I Love Bigdata| [i, love, bigdata]| | 2| 1 2 3 4| [1, 2, 3, 4]| +---+--------------+-------------------+ +---+--------------+------------+ | id| sentence| words| +---+--------------+------------+ | 0|Hello I am LYL| []| | 1|I Love Bigdata| []| | 2| 1 2 3 4|[1, 2, 3, 4]| +---+--------------+------------+ +-------------------+---------+ | words|wordcount| +-------------------+---------+ |[hello, i, am, lyl]| 4| | [i, love, bigdata]| 3| | [1, 2, 3, 4]| 4| +-------------------+---------+ SQLTransformer 我们都很喜欢sql语句,简单好用又熟悉,那么Spark ML很人性化的为我们提供了SQLTransformer类,使得我们能用我们熟悉的SQL来做特征转化。它支持SparkSql中的所有select选择语句,sum(),count(),group by,order by等等都可以用!形如"SELECT ...FROM __THIS__"。'__THIS__'代表输入数据的基础表。 def main(args: Array[String]): Unit = { val spark = SparkSession.builder().master("local[2]").getOrCreate() val df = spark.createDataFrame(Seq((1, "lyl", 90), (2, "ddd", 88), (3, "ccc", 95))) .toDF("id", "name", "score") //__THIS__代表输入数据的基础表 在这里就是指df val sqltransformer1 = new SQLTransformer().setStatement("select id from __THIS__") val sqltransformer2 = new SQLTransformer().setStatement("select sum(score)/3 as average from __THIS__") sqltransformer1.transform(df).show() sqltransformer2.transform(df).show() } 输出结果为: +---+ | id| +---+ | 1| | 2| | 3| +---+ |average| +-------+ | 91.0| +-------+