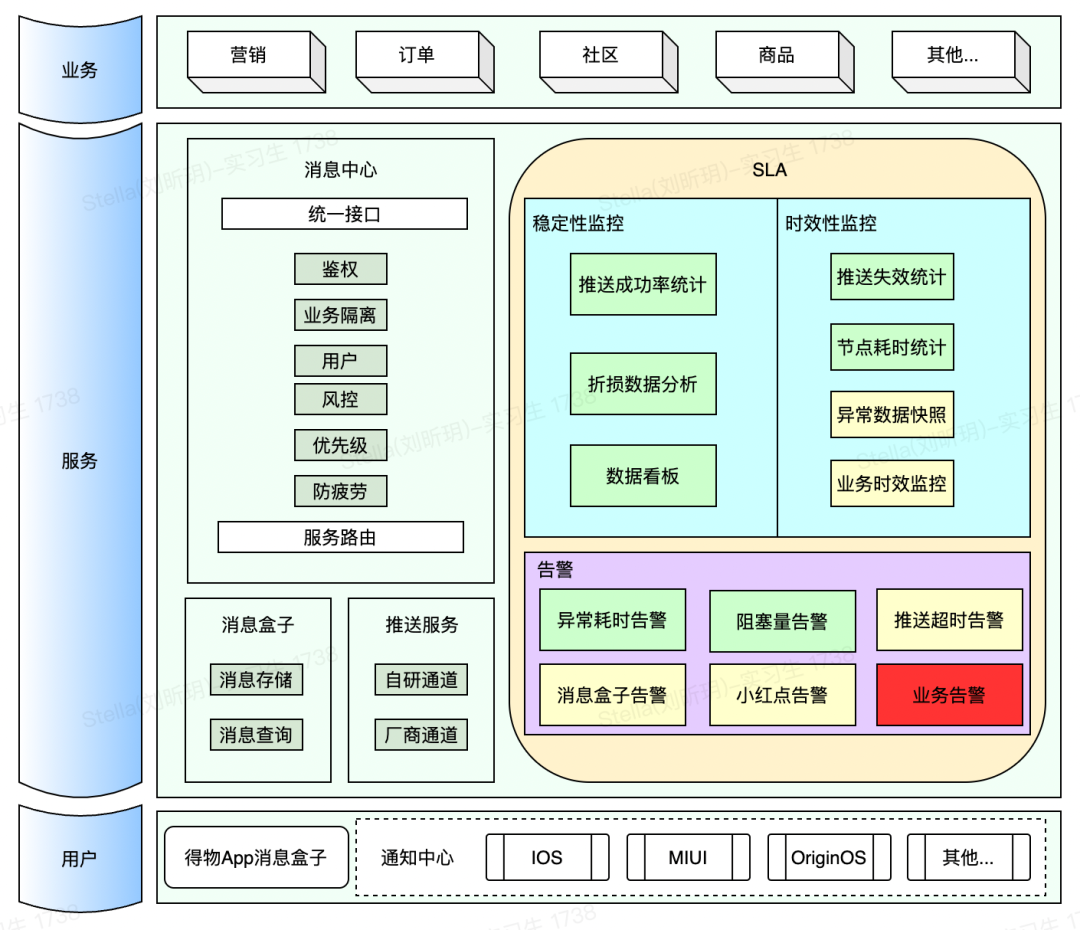
Xmake v2.9.2 发布,各种细节和稳定性改进
新特性 #5005: 显示所有 API #5003: 添加 build.fence 策略 #5060: 支持 Verilator 静态库目标构建 #5074: 添加xrepo download命令去快速下载包源码 #5086: 添加包检测支持 #5103: 添加 qt ts 构建支持 #5104: 改进 find_program,在 windows 上调用 where 改进查找 改进 #5077: 当构建 x86 目标时,使用 x64 的 msvc 编译工具 #5109: 改进 add_rpathdirs 支持 runpath/rpath 切换 #5132: 改进 ifort/icc/icx 在 windows 上的支持 Bugs 修复 #5059: 修复加载大量 targets 时候卡住 #5029: 修复在 termux 上崩溃问题