整理分享C#通过user32.dll模拟物理按键操作的代码
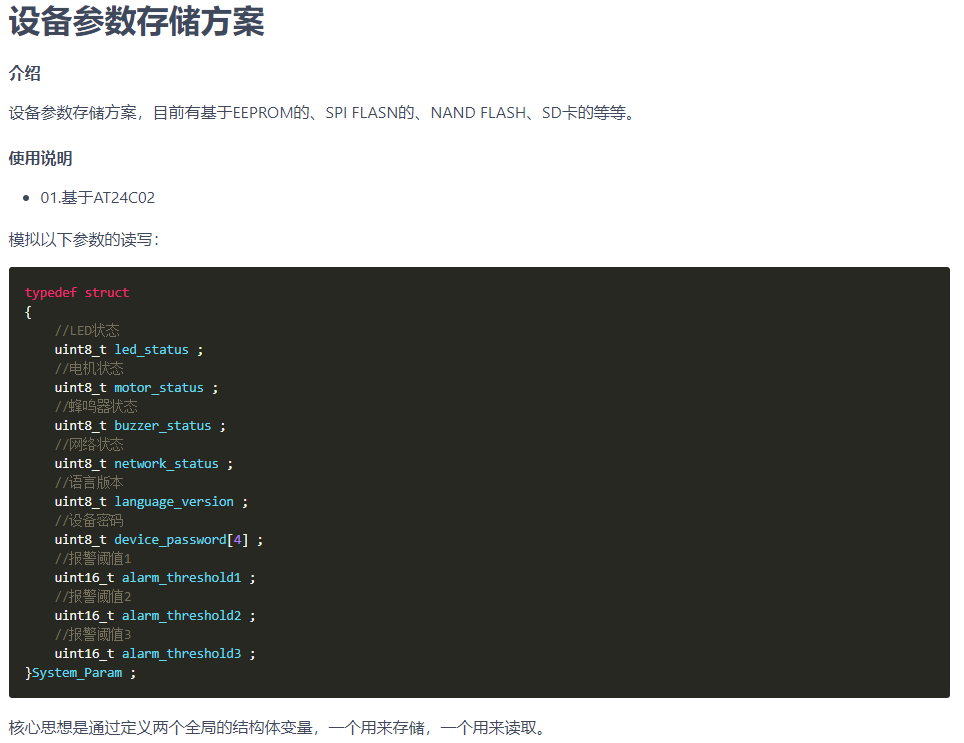
对系统模拟按键方面的知识和按键映射代码做了一下梳理,在这里分享出来,适用于开发自动操作工具和游戏外挂。 主代码: public const int KEYEVENTF_EXTENDEDKEY = 0x0001; //Key click flag public const int KEYEVENTF_KEYUP = 0x0002; //Key up flag [DllImport("user32.dll")] private static extern void keybd_event(byte bVk, byte bSCan, int dwFlags, int dwExtraInfo); [DllImport("user32.dll")] private static extern byte MapVirtualKey(byte wCode, int wMap); public static void 模拟按下按键(VirtualKeyCode 虚拟按键代码) { var code = (byte)虚拟按键代码; keybd_event(code, 0, 0, 0); } public static void 模拟弹起按键(VirtualKeyCode 虚拟按键代码) { var code = (byte) 虚拟按键代码; keybd_event(code, 0, KEYEVENTF_KEYUP, 0); } public static void 模拟单击按键(VirtualKeyCode 虚拟按键代码) { var code = (byte)虚拟按键代码; keybd_event(code, 0, KEYEVENTF_EXTENDEDKEY, 0); } 网上关于keybd_event的dwFlags参数功能说法很混乱,经我测试貌似是KEYEVENTF_EXTENDEDKEY表示一次单击,0表示按下,KEYEVENTF_KEYUP表示弹起,不一定完全正确,希望高人指点一下。 另外MapVirtualKey的作用实在不懂,所以就没用上,看到有人这么调用不知有什么区别: var code = (byte)虚拟按键代码; keybd_event(code, MapVirtualKey(code,0), 0, 0); 我试过好像也没什么变化~到底MapVirtualKey是干什么用的呢?? VirtualKeyCode枚举: /// <summary> /// 虚拟按键代码 /// 参考于 http://msdn.microsoft.com/zh-cn/library/dd375731(v=vs.85).aspx /// </summary> public enum VirtualKeyCode { /// <summary> /// Left mouse button /// </summary> Left_mouse_button = 0x01, /// <summary> /// Right mouse button /// </summary> Right_mouse_button = 0x02, /// <summary> /// Control-break processing /// </summary> Control_break_processing = 0x03, /// <summary> /// Middle mouse button (three-button mouse) /// </summary> Middle_mouse_button = 0x04, /// <summary> /// X1 mouse button /// </summary> X1_mouse_button = 0x05, /// <summary> /// X2 mouse button /// </summary> X2_mouse_button = 0x06, /// <summary> /// Undefined /// </summary> Undefined1 = 0x07, /// <summary> /// BACKSPACE key /// </summary> BACKSPACE_key = 0x08, /// <summary> /// TAB key /// </summary> TAB_key = 0x09, /// <summary> /// CLEAR key /// </summary> CLEAR_key = 0x0C, /// <summary> /// ENTER key /// </summary> ENTER_key = 0x0D, /// <summary> /// SHIFT key /// </summary> SHIFT_key = 0x10, /// <summary> /// CTRL key /// </summary> CTRL_key = 0x11, /// <summary> /// ALT key /// </summary> ALT_key = 0x12, /// <summary> /// PAUSE key /// </summary> PAUSE_key = 0x13, /// <summary> /// CAPS LOCK key /// </summary> CAPS_LOCK_key = 0x14, /// <summary> /// IME Kana mode /// </summary> IME_Kana_mode = 0x15, /// <summary> /// IME Hanguel mode (maintained for compatibility; use VK_HANGUL) /// </summary> IME_Hanguel_mode = 0x15, /// <summary> /// IME Hangul mode /// </summary> IME_Hangul_mode = 0x15, /// <summary> /// Undefined /// </summary> Undefined2 = 0x16, /// <summary> /// IME Junja mode /// </summary> IME_Junja_mode = 0x17, /// <summary> /// IME final mode /// </summary> IME_final_mode = 0x18, /// <summary> /// IME Hanja mode /// </summary> IME_Hanja_mode = 0x19, /// <summary> /// IME Kanji mode /// </summary> IME_Kanji_mode = 0x19, /// <summary> /// Undefined /// </summary> Undefined = 0x1A, /// <summary> /// ESC key /// </summary> ESC_key = 0x1B, /// <summary> /// IME convert /// </summary> IME_convert = 0x1C, /// <summary> /// IME nonconvert /// </summary> IME_nonconvert = 0x1D, /// <summary> /// IME accept /// </summary> IME_accept = 0x1E, /// <summary> /// IME mode change request /// </summary> IME_mode_change_request = 0x1F, /// <summary> /// SPACEBAR /// </summary> SPACEBAR = 0x20, /// <summary> /// PAGE UP key /// </summary> PAGE_UP_key = 0x21, /// <summary> /// PAGE DOWN key /// </summary> PAGE_DOWN_key = 0x22, /// <summary> /// END key /// </summary> END_key = 0x23, /// <summary> /// HOME key /// </summary> HOME_key = 0x24, /// <summary> /// LEFT ARROW key /// </summary> LEFT_ARROW_key = 0x25, /// <summary> /// UP ARROW key /// </summary> UP_ARROW_key = 0x26, /// <summary> /// RIGHT ARROW key /// </summary> RIGHT_ARROW_key = 0x27, /// <summary> /// DOWN ARROW key /// </summary> DOWN_ARROW_key = 0x28, /// <summary> /// SELECT key /// </summary> SELECT_key = 0x29, /// <summary> /// PRINT key /// </summary> PRINT_key = 0x2A, /// <summary> /// EXECUTE key /// </summary> EXECUTE_key = 0x2B, /// <summary> /// PRINT SCREEN key /// </summary> PRINT_SCREEN_key = 0x2C, /// <summary> /// INS key /// </summary> INS_key = 0x2D, /// <summary> /// DEL key /// </summary> DEL_key = 0x2E, /// <summary> /// HELP key /// </summary> HELP_key = 0x2F, /// <summary> /// 0 key /// </summary> _0_key = 0x30, /// <summary> /// 1 key /// </summary> _1_key = 0x31, /// <summary> /// 2 key /// </summary> _2_key = 0x32, /// <summary> /// 3 key /// </summary> _3_key = 0x33, /// <summary> /// 4 key /// </summary> _4_key = 0x34, /// <summary> /// 5 key /// </summary> _5_key = 0x35, /// <summary> /// 6 key /// </summary> _6_key = 0x36, /// <summary> /// 7 key /// </summary> _7_key = 0x37, /// <summary> /// 8 key /// </summary> _8_key = 0x38, /// <summary> /// 9 key /// </summary> _9_key = 0x39, /// <summary> /// A key /// </summary> A_key = 0x41, /// <summary> /// B key /// </summary> B_key = 0x42, /// <summary> /// C key /// </summary> C_key = 0x43, /// <summary> /// D key /// </summary> D_key = 0x44, /// <summary> /// E key /// </summary> E_key = 0x45, /// <summary> /// F key /// </summary> F_key = 0x46, /// <summary> /// G key /// </summary> G_key = 0x47, /// <summary> /// H key /// </summary> H_key = 0x48, /// <summary> /// I key /// </summary> I_key = 0x49, /// <summary> /// J key /// </summary> J_key = 0x4A, /// <summary> /// K key /// </summary> K_key = 0x4B, /// <summary> /// L key /// </summary> L_key = 0x4C, /// <summary> /// M key /// </summary> M_key = 0x4D, /// <summary> /// N key /// </summary> N_key = 0x4E, /// <summary> /// O key /// </summary> O_key = 0x4F, /// <summary> /// P key /// </summary> P_key = 0x50, /// <summary> /// Q key /// </summary> Q_key = 0x51, /// <summary> /// R key /// </summary> R_key = 0x52, /// <summary> /// S key /// </summary> S_key = 0x53, /// <summary> /// T key /// </summary> T_key = 0x54, /// <summary> /// U key /// </summary> U_key = 0x55, /// <summary> /// V key /// </summary> V_key = 0x56, /// <summary> /// W key /// </summary> W_key = 0x57, /// <summary> /// X key /// </summary> X_key = 0x58, /// <summary> /// Y key /// </summary> Y_key = 0x59, /// <summary> /// Z key /// </summary> Z_key = 0x5A, /// <summary> /// Left Windows key (Natural keyboard) /// </summary> Left_Windows_key = 0x5B, /// <summary> /// Right Windows key (Natural keyboard) /// </summary> Right_Windows_key = 0x5C, /// <summary> /// Applications key (Natural keyboard) /// </summary> Applications_key = 0x5D, /// <summary> /// Reserved /// </summary> Reserved1 = 0x5E, /// <summary> /// Computer Sleep key /// </summary> Computer_Sleep_key = 0x5F, /// <summary> /// Numeric keypad 0 key /// </summary> Numeric_keypad_0_key = 0x60, /// <summary> /// Numeric keypad 1 key /// </summary> Numeric_keypad_1_key = 0x61, /// <summary> /// Numeric keypad 2 key /// </summary> Numeric_keypad_2_key = 0x62, /// <summary> /// Numeric keypad 3 key /// </summary> Numeric_keypad_3_key = 0x63, /// <summary> /// Numeric keypad 4 key /// </summary> Numeric_keypad_4_key = 0x64, /// <summary> /// Numeric keypad 5 key /// </summary> Numeric_keypad_5_key = 0x65, /// <summary> /// Numeric keypad 6 key /// </summary> Numeric_keypad_6_key = 0x66, /// <summary> /// Numeric keypad 7 key /// </summary> Numeric_keypad_7_key = 0x67, /// <summary> /// Numeric keypad 8 key /// </summary> Numeric_keypad_8_key = 0x68, /// <summary> /// Numeric keypad 9 key /// </summary> Numeric_keypad_9_key = 0x69, /// <summary> /// Multiply key /// </summary> Multiply_key = 0x6A, /// <summary> /// Add key /// </summary> Add_key = 0x6B, /// <summary> /// Separator key /// </summary> Separator_key = 0x6C, /// <summary> /// Subtract key /// </summary> Subtract_key = 0x6D, /// <summary> /// Decimal key /// </summary> Decimal_key = 0x6E, /// <summary> /// Divide key /// </summary> Divide_key = 0x6F, /// <summary> /// F1 key /// </summary> F1_key = 0x70, /// <summary> /// F2 key /// </summary> F2_key = 0x71, /// <summary> /// F3 key /// </summary> F3_key = 0x72, /// <summary> /// F4 key /// </summary> F4_key = 0x73, /// <summary> /// F5 key /// </summary> F5_key = 0x74, /// <summary> /// F6 key /// </summary> F6_key = 0x75, /// <summary> /// F7 key /// </summary> F7_key = 0x76, /// <summary> /// F8 key /// </summary> F8_key = 0x77, /// <summary> /// F9 key /// </summary> F9_key = 0x78, /// <summary> /// F10 key /// </summary> F10_key = 0x79, /// <summary> /// F11 key /// </summary> F11_key = 0x7A, /// <summary> /// F12 key /// </summary> F12_key = 0x7B, /// <summary> /// F13 key /// </summary> F13_key = 0x7C, /// <summary> /// F14 key /// </summary> F14_key = 0x7D, /// <summary> /// F15 key /// </summary> F15_key = 0x7E, /// <summary> /// F16 key /// </summary> F16_key = 0x7F, /// <summary> /// F17 key /// </summary> F17_key = 0x80, /// <summary> /// F18 key /// </summary> F18_key = 0x81, /// <summary> /// F19 key /// </summary> F19_key = 0x82, /// <summary> /// F20 key /// </summary> F20_key = 0x83, /// <summary> /// F21 key /// </summary> F21_key = 0x84, /// <summary> /// F22 key /// </summary> F22_key = 0x85, /// <summary> /// F23 key /// </summary> F23_key = 0x86, /// <summary> /// F24 key /// </summary> F24_key = 0x87, /// <summary> /// NUM LOCK key /// </summary> NUM_LOCK_key = 0x90, /// <summary> /// SCROLL LOCK key /// </summary> SCROLL_LOCK_key = 0x91, /// <summary> /// Left SHIFT key /// </summary> Left_SHIFT_key = 0xA0, /// <summary> /// Right SHIFT key /// </summary> Right_SHIFT_key = 0xA1, /// <summary> /// Left CONTROL key /// </summary> Left_CONTROL_key = 0xA2, /// <summary> /// Right CONTROL key /// </summary> Right_CONTROL_key = 0xA3, /// <summary> /// Left MENU key /// </summary> Left_MENU_key = 0xA4, /// <summary> /// Right MENU key /// </summary> Right_MENU_key = 0xA5, /// <summary> /// Browser Back key /// </summary> Browser_Back_key = 0xA6, /// <summary> /// Browser Forward key /// </summary> Browser_Forward_key = 0xA7, /// <summary> /// Browser Refresh key /// </summary> Browser_Refresh_key = 0xA8, /// <summary> /// Browser Stop key /// </summary> Browser_Stop_key = 0xA9, /// <summary> /// Browser Search key /// </summary> Browser_Search_key = 0xAA, /// <summary> /// Browser Favorites key /// </summary> Browser_Favorites_key = 0xAB, /// <summary> /// Browser Start and Home key /// </summary> Browser_Start_and_Home_key = 0xAC, /// <summary> /// Volume Mute key /// </summary> Volume_Mute_key = 0xAD, /// <summary> /// Volume Down key /// </summary> Volume_Down_key = 0xAE, /// <summary> /// Volume Up key /// </summary> Volume_Up_key = 0xAF, /// <summary> /// Next Track key /// </summary> Next_Track_key = 0xB0, /// <summary> /// Previous Track key /// </summary> Previous_Track_key = 0xB1, /// <summary> /// Stop Media key /// </summary> Stop_Media_key = 0xB2, /// <summary> /// Play/Pause Media key /// </summary> Play_Or_Pause_Media_key = 0xB3, /// <summary> /// Start Mail key /// </summary> Start_Mail_key = 0xB4, /// <summary> /// Select Media key /// </summary> Select_Media_key = 0xB5, /// <summary> /// Start Application 1 key /// </summary> Start_Application_1_key = 0xB6, /// <summary> /// Start Application 2 key /// </summary> Start_Application_2_key = 0xB7, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters1 = 0xBA, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters2 = 0xBF, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters3 = 0xC0, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters4 = 0xDB, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters5 = 0xDC, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters6 = 0xDD, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters7 = 0xDE, /// <summary> /// Used for miscellaneous characters; it can vary by keyboard. /// </summary> Used_for_miscellaneous_characters8 = 0xDF, /// <summary> /// Reserved /// </summary> Reserved2 = 0xE0, /// <summary> /// OEM specific /// </summary> OEM_specific1 = 0xE1, /// <summary> /// Either the angle bracket key or the backslash key on the RT 102-key keyboard /// </summary> Either_the_angle_bracket_key_or_the_backslash_key_on_the_RT_102_key_keyboard = 0xE2, /// <summary> /// IME PROCESS key /// </summary> IME_PROCESS_key = 0xE5, /// <summary> /// OEM specific /// </summary> OEM_specific2 = 0xE6, /// <summary> /// Used to pass Unicode characters as if they were keystrokes. The VK_PACKET key is the low word of a 32-bit Virtual Key value used for non-keyboard input methods. For more information, see Remark in KEYBDINPUT, SendInput, WM_KEYDOWN, and WM_KEYUP /// </summary> Used_to_pass_Unicode_characters_as_if_they_were_keystrokes = 0xE7, /// <summary> /// Unassigned /// </summary> Unassigned = 0xE8, /// <summary> /// Attn key /// </summary> Attn_key = 0xF6, /// <summary> /// CrSel key /// </summary> CrSel_key = 0xF7, /// <summary> /// ExSel key /// </summary> ExSel_key = 0xF8, /// <summary> /// Erase EOF key /// </summary> Erase_EOF_key = 0xF9, /// <summary> /// Play key /// </summary> Play_key = 0xFA, /// <summary> /// Zoom key /// </summary> Zoom_key = 0xFB, /// <summary> /// Reserved /// </summary> Reserved = 0xFC, /// <summary> /// PA1 key /// </summary> PA1_key = 0xFD, /// <summary> /// Clear key /// </summary> Clear_key = 0xFE } 调用演示://模拟实现Ctrl+O操作 模拟按下按键(VirtualKeyCode.CTRL_key) 模拟单击按键(VirtualKeyCode.O_key) 模拟弹起按键(VirtualKeyCode.CTRL_key) 本文转自斯克迪亚博客园博客,原文链接:http://www.cnblogs.com/SkyD/p/4070743.html,如需转载请自行联系原作者