K8S自己动手系列 - 2.3 - PV & PVC
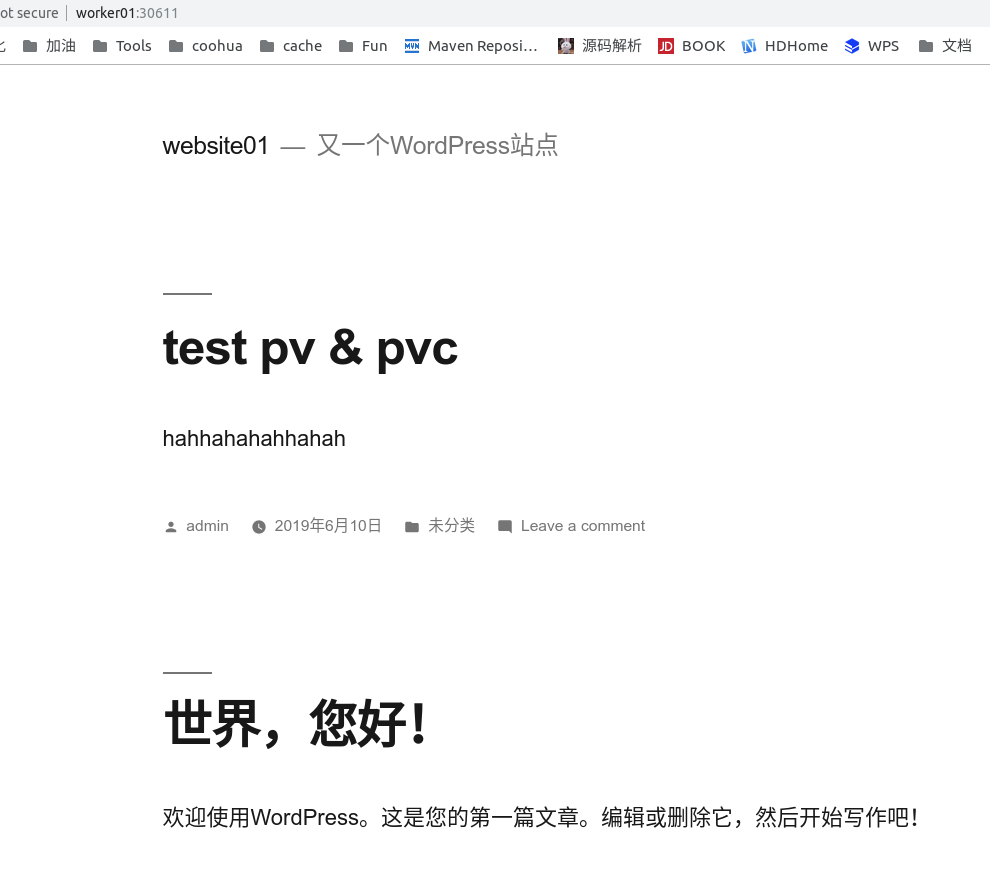
前言 在实验2.2 – Deployment中,我们将原来基于Pod部署的wordpress+mysql成功改造成基于Deployment部署,基于Deployment部署有很多好处,例如:支持滚动升级(Rolling Update),支持水平扩展。 不过有个问题,就是当我们的Deployment修改了,或者Pod删除重建了,数据也随之丢失了,这是我们不希望看到的,本篇文章我们就来尝试一下基于PV & PVC保存数据状态的有状态应用。 场景 对于单实例的有状态应用,我们可以定义Deployment并且replicas只能为1,用指定PVC的方式关联到一个PV上,使用PV提供的状态存储功能。如果要启动多实例,那么Deployment就无法胜任这个任务,必须使用到我们后面会讲到的StatefulSet+PVC Template的方式创建多实例对多PVC的模型。 本文实验所有的源码保存在:https://github.com/zrbcool/blog-public/tree/master/k8s-hands-on/lab06 实战 PVC定义 lab06 git:(master) cat 03-wordpress-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: wordpress-pv-claim spec: accessModes: - ReadWriteOnce resources: requests: storage: 2Gi 部署后查看状态 lab06 git:(master) kubectl apply -f 03-wordpress-pvc.yaml persistentvolumeclaim/wordpress-pv-claim created lab06 git:(master) kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE wordpress-mysql-pv-claim Pending 4s 发现PVC处于Pending状态,追查下原因 lab06 git:(master) kubectl describe pvc/wordpress-mysql-pv-claim Name: wordpress-mysql-pv-claim Namespace: default StorageClass: Status: Pending Volume: Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"v1","kind":"PersistentVolumeClaim","metadata":{"annotations":{},"name":"wordpress-mysql-pv-claim","namespace":"default"},"s... Finalizers: [kubernetes.io/pvc-protection] Capacity: Access Modes: VolumeMode: Filesystem Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal FailedBinding 6s (x4 over 36s) persistentvolume-controller no persistent volumes available for this claim and no storage class is set Mounted By: <none> 接下来我们创建PV PV定义 查看定义 lab06 git:(master) cat 04-wordpress-pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: wordpress-mysql-pv-volume labels: type: local spec: capacity: storage: 2Gi accessModes: - ReadWriteOnce hostPath: path: "/data/pv/wordpress/mysql" 该pv定义是基于hostPath的方式,所以我们要在节点上提前创建好目录,如下: lab06 git:(master) mkdir -p /data/pv/wordpress/mysql lab06 git:(master) kubectl create -f 04-wordpress-pv.yaml persistentvolume/wordpress-mysql-pv-volume created lab06 git:(master) kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE wordpress-mysql-pv-volume 2Gi RWO Retain Bound default/wordpress-mysql-pv-claim 31s lab06 git:(master) kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE wordpress-mysql-pv-claim Bound wordpress-mysql-pv-volume 2Gi RWO 118s 此时我们之前定义的pvc也已经成功绑定了 使Deployment使用该PVC 查看定义 lab06 git:(master) cat 01-wordpress-mysql-deployment.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: wordpress name: wordpress spec: replicas: 1 selector: matchLabels: app: wordpress template: metadata: labels: app: wordpress spec: containers: - image: wordpress:latest imagePullPolicy: IfNotPresent name: wordpress env: - name: WORDPRESS_DB_HOST value: "127.0.0.1" - name: WORDPRESS_DB_USER value: "root" - name: WORDPRESS_DB_PASSWORD value: "passw0rd" - image: mysql:5.7.26 imagePullPolicy: IfNotPresent name: mysql env: - name: MYSQL_ROOT_PASSWORD value: "passw0rd" - name: MYSQL_DATABASE value: "wordpress" volumeMounts: - name: mysql-persistent-storage mountPath: /var/lib/mysql volumes: - name: mysql-persistent-storage persistentVolumeClaim: claimName: wordpress-mysql-pv-claim 执行更新并查看效果 lab06 git:(master) kubectl apply -f 01-wordpress-mysql-deployment.yaml deployment.extensions/wordpress configured lab06 git:(master) kubectl get pod NAME READY STATUS RESTARTS AGE wordpress-6cfd879fcd-9mlhb 2/2 Running 0 29s lab06 git:(master) ls -l /data/pv/wordpress/mysql/ total 188480 -rw-r----- 1 999 999 56 Jun 10 23:42 auto.cnf -rw------- 1 999 999 1675 Jun 10 23:42 ca-key.pem -rw-r--r-- 1 999 999 1107 Jun 10 23:42 ca.pem ... drwxr-x--- 2 999 999 12288 Jun 10 23:42 sys drwxr-x--- 2 999 999 4096 Jun 10 23:42 wordpress 可见,Pod已经在/data/pv/wordpress/mysql/下产生数据了,接下来我们来试一下配置数据后,删除Pod,使Deployment控制Pod重建,配置数据是否能够保存通过下面命令删除Pod使其重建 lab06 git:(master) kubectl get pod NAME READY STATUS RESTARTS AGE wordpress-6cfd879fcd-9mlhb 2/2 Running 0 7m34s lab06 git:(master) kubectl delete pod/wordpress-6cfd879fcd-9mlhb pod "wordpress-6cfd879fcd-9mlhb" deleted lab06 git:(master) kubectl get pod NAME READY STATUS RESTARTS AGE wordpress-6cfd879fcd-29qg9 2/2 Running 1 11s 刷新网页,发布的测试文件还在,测试成功 新问题 查看官网说明:意思是说,对于这个单实例的有状态Deployment不要对其进行扩容,同时当Deployment定义发生更新时也不能使用滚动更新,而应该先删除再创建,也就是strategy: type: Recreate修改后的文件如下: lab06 git:(master) cat 01-wordpress-mysql-deployment.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: wordpress name: wordpress spec: strategy: type: Recreate replicas: 1 selector: matchLabels: app: wordpress template: metadata: labels: app: wordpress spec: containers: - image: wordpress:latest imagePullPolicy: IfNotPresent name: wordpress env: - name: WORDPRESS_DB_HOST value: "127.0.0.1" - name: WORDPRESS_DB_USER value: "root" - name: WORDPRESS_DB_PASSWORD value: "passw0rd" - image: mysql:5.7.26 imagePullPolicy: IfNotPresent name: mysql env: - name: MYSQL_ROOT_PASSWORD value: "passw0rd" - name: MYSQL_DATABASE value: "wordpress" volumeMounts: - name: mysql-persistent-storage mountPath: /var/lib/mysql volumes: - name: mysql-persistent-storage persistentVolumeClaim: claimName: wordpress-mysql-pv-claim 清除数据 lab06 git:(master) kubectl delete -f . deployment.extensions "wordpress" deleted service "wordpress-svc" deleted persistentvolumeclaim "wordpress-mysql-pv-claim" deleted persistentvolume "wordpress-mysql-pv-volume" deleted