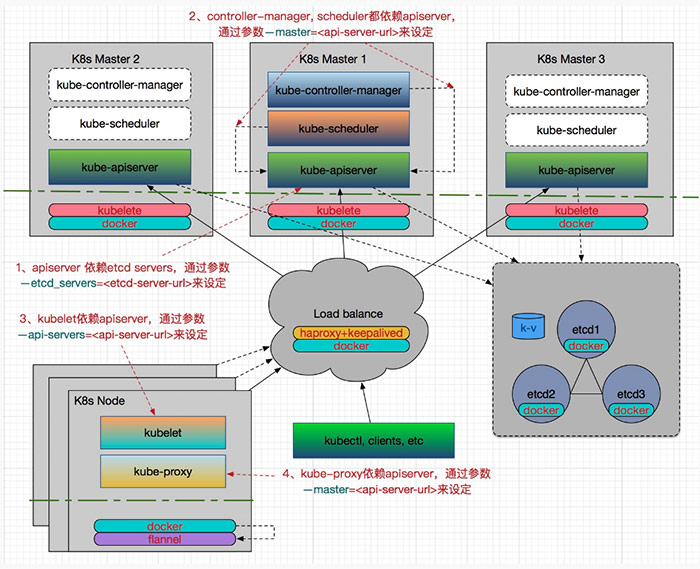
Java容器深入浅出之HashSet、TreeSet和EnumSet
Java集合中的Set接口,定义的是一类无顺序的、不可重复的对象集合。如果尝试添加相同的元素,add()方法会返回false,同时添加失败。Set接口包括3个主要的实现类:HashSet、TreeSet和EnumSet。 通过查看Java源码,事实上Java是先实现了Map,然后通过包装一个所有value都为null的集合,形成Set。 HashSet HashSet基于Hash算法实现,因此存取和查找的性能较好。HashSet的主要特点如下: 1. 无顺序的。与添加顺序不同,并且可变。 2. 线程不安全。 3. 集合元素可以是null 4. HashSet是通过元素的HashCode返回值,来确定元素存储位置。 5. 不可重复。HashSet判断元素是否重复的标准是:该元素对象的HashCode()返回值相等,并且equals()方法相等。换句话说,如果两个元素的equals方法相同,但HashCode返回值不相同,HashSet依然可以添加成功。因此,需要注意: 5.1 用Set类保存的元素,尽量保证其equals相等的同时,HashCode返回的值也相等。 5.2 当保存引用类型对象的时候,尽量不要修改其实例变量,否则可能会导致Set集合操作失灵。 1 /* 2 * 测试HashSet的对象添加规则 3 */ 4 class A{ 5 //重写类A的equals方法,恒返回true 6 public boolean equals(Object obj) { 7 return true; 8 } 9 } 10 class B{ 11 //重写类B的HashCode方法,恒返回1 12 public int hashCode() { 13 return 1; 14 } 15 } 16 class C{ 17 //重写类C的HashCode方法,恒返回2 18 public int hashCode() { 19 return 2; 20 } 21 //重写类C的equals方法,恒返回true 22 public boolean equals(Object obj) { 23 return true; 24 } 25 } 26 public class TestHashSet { 27 28 public static void main(String[] args) { 29 30 Set<Object> set = new HashSet<>(); 31 //equals相同,HashCode不相同: 32 //两个对象添加到hash表的不同位置 33 set.add(new A()); 34 set.add(new A()); 35 //HashCode相同, equals不同 36 //此时Hash表会在该HashCode位置,使用链式结构保存这些对象,导致性能下降. 37 set.add(new B()); 38 set.add(new B()); 39 //C类对象只被添加了一次. 40 set.add(new C()); 41 set.add(new C()); 42 43 System.out.println(set); 44 45 } 46 47 } LinkedHashSet LinkedHashSet是HashSet的子类。虽然同样按照元素的HashCode来确定存储位置,但该类同时使用链表来维护添加顺序,也因此,其性能稍低,但是迭代访问元素时优势较大。 TreeSet TreeSet底层采用的是红黑树的数据结构,并且是有序的集合。因此,TreeSet增加了访问第一个、前一个、后一个和最后一个的方法,并且提供了3个截取子树的方法。 TreeSet包括两种排序方法:自然排序和定制排序,默认使用自然排序。 1 public class TestTreeSet { 2 3 public static void main(String[] args) { 4 TreeSet<Integer> nums = new TreeSet<>(); 5 nums.add(5); 6 nums.add(2); 7 nums.add(10); 8 nums.add(-9); 9 //输出,此时已按自然排序 10 System.out.println(nums); 11 System.out.println(nums.first()); 12 System.out.println(nums.last()); 13 //返回<4的子序列 14 System.out.println(nums.headSet(4)); 15 //返回>=5的子序列 16 System.out.println(nums.tailSet(5)); 17 //返回[-3, 4)的子序列 18 System.out.println(nums.subSet(-3, 4)); 19 } 20 21 } TreeSet的自然排序 指的是TreeSet会调用元素的compareTo(Object o)方法来比较元素之间的大小关系,然后将集合按升序排列。 当把一个对象加入TreeSet集合中时,会调用compareTo方法与集合中其它对象比较大小,然后根据红黑树结构定位存储位置。如比较相等,则无法添加。 自然排序中判断两个对象是否相等的唯一标准:两个对象通过compareTo方法返回是否为0。 因此,当重写两个对象的equals方法时,应当重写其compareTo方法,确保有一致的结果。与HashSet类似,当保存引用类型对象的时候,尽量不要修改其实例变量,否则可能会导致操作失效。 TreeSet的定制排序 创建TreeSet集合的对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责元素集合的排序逻辑。 定制排序中判断两个对象是否相等的标准:Comparator对象中比较两个元素是否返回0 class M{ int age; public M(int age) { super(); this.age = age; } @Override public String toString() { return "M [age=" + age + "]"; } } public class TestTreeSetComparator { public static void main(String[] args) { TreeSet<M> ts = new TreeSet<>((o1, o2) -> { M m1 = (M)o1; M m2 = (M)o2; //自定义排序:M对象的age属性越大,对比结果反而越小 return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0; }); ts.add(new M(5)); ts.add(new M(-3)); ts.add(new M(9)); System.out.println(ts); } } EnumSet EnumSet专为枚举类设计,其元素必须是指定枚举类的枚举值,并且不能为null。 EnumSet为有序集合,顺序由枚举值在枚举类中的定义顺序决定。其常用方法如下: 1 enum Season{ 2 SPRING, SUMMER, FALL, WINTER 3 } 4 5 public class TestEnumSet { 6 7 public static void main(String[] args) { 8 //创建一个指定枚举类Season的枚举集合 9 EnumSet<Season> es1 = EnumSet.allOf(Season.class); 10 System.out.println(es1); 11 //创建一个指定枚举类Season的空集合 12 EnumSet<Season> es2 = EnumSet.noneOf(Season.class); 13 System.out.println(es2); 14 //手动添加枚举值 15 es2.add(Season.WINTER); 16 es2.add(Season.SUMMER); 17 System.out.println(es2); 18 //创建一个指定枚举值的枚举集合 19 EnumSet<Season> es3 = EnumSet.of(Season.SPRING, Season.FALL); 20 System.out.println(es3); 21 //创建一个指定枚举值及顺序的枚举集合 22 EnumSet<Season> es4 = EnumSet.range(Season.SUMMER, Season.WINTER); 23 System.out.println(es4); 24 //创建一个es4集合的其余集合es5, 其中es4+es5=es1 25 EnumSet<Season> es5 = EnumSet.complementOf(es4); 26 System.out.println(es5); 27 } 28 } 关于HashSet和TreeSet的选择 作为两个Set接口的典型实现,一般的选择考虑点是: 1. 优先选择HashSet,快速满足日常添加、查询的操作。 2. 有迭代需求时,可以考虑LinkedHashSet 3. 当需要一个排序的Set的时候,再考虑TreeSet 4. 操作枚举类时,优先考虑EnumSet 当需要在多线程环境下使用集合,应该使用Collections工具类在创建集合时就封装为线程安全。 SortedSet set = Collections.synchronizedSortedSet(new TreeSet());