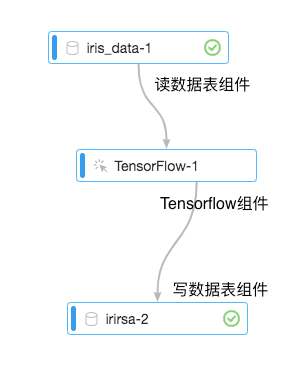



EMR Spark Relational Cache 利用数据预组织加速查询
Relational Cache相关文章链接: 使用Relational Cache加速EMR Spark数据分析使用EMR Spark Relational Cache跨集群同步数据EMR Spark Relational Cache的执行计划重写EMR Spark Relational Cache如何支持雪花模型中的关联匹配 背景 在利用Relational Cache进行查询优化时,我们需要通过预计算,存储大量数据。而在查询时,我们真正需要读取的数据量也许并不大。为了能让查询实现秒级响应,这就涉及到优化从大量数据中快速定位所需数据的场景。本文介绍在EMR Spark Relational Cache中,我们如何针对这种场景进行了优化。 存储格式 在数据存储格式上,我们默认选择Spark社区支持最好的Parquet格式。Parquet是