web服务器:
动态语言服务器,运行方式的不同
现在的运行方式是通过网络来激发运行
服务器的用处:
动态语言就是在服务器中运行
平时的运行方式是通过本地进行运行的。
动态语言是通过到达请求,来激发运行URL网页地址来激发运行
web服务器是用来解析http协议,相当于一个平台在这个平台做web开发,好多东西他都给你搭建好了
浏览器请求—— WEB 解析(判读运行那些Java代码) —— Java服务器—— 输出内容到—— Web服务器(HTML) —— 浏览器接受显示
Web服务器:帮我们处理请求,处理链接的容器,代码在容器中运行。(帮我们处理相应的请求)
1.接受请求
2.解析请求头信息
3.找到指定代码运行
4.得到运行输出的HTML 代码 输出到浏览器
web有多线程多任务访问的处理机制,web服务器也是可以进行集群操作的。
![f6f9ee65193f2282de46e83ecc8fb0c64df03d67]()
![f6f9ee65193f2282de46e83ecc8fb0c64df03d67]()
Tomcat服务器 WEB容器
WEBLongic 服务器 WEB容器 EJB容器
JBoss服务器 WEB容器 EJB容器
等等很多
Tomcat:
用Java语言制作的服务器,可以在任何平台运行
多线程服务器
服务器集群
Tomcat下载和安装:
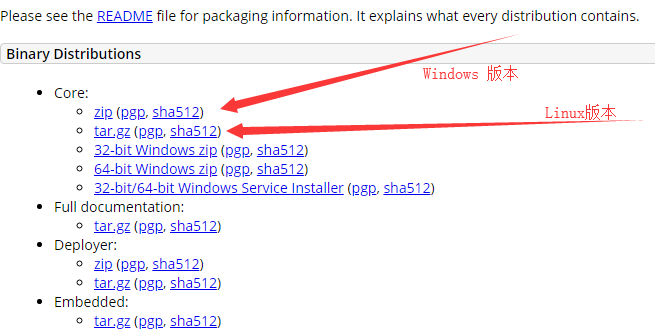
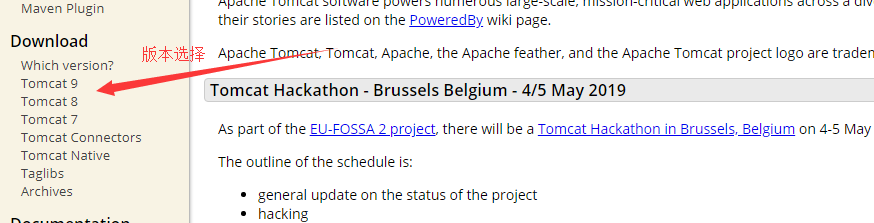
1.下载tomcat 网站 tomcat.apache.org
![fcbfe60e645b8977b1d9a9328ad789cb33da64ac]()
![f6f9ee65193f2282de46e83ecc8fb0c64df03d67]()
2.检查jdk环境是否配置好来 Java_Home 必须要有
3.将压缩包解压出去,打开tomcat下的bin目录,下面有一个startup.bat(Windows上的启动文件) startup.sh (Linux上启动文件)
正常的关闭tomcat需要启动 shutdown.bat shutdown.sh 直接按X关闭是强制关闭,非法关闭 会丢失一些数据
4.检查环境变量,启动tomcat 如果有闪退 或者运行一会就退出 就是环境变量配置有问题 或者是jdk版本过低 版本不匹配
错误情况:
1.闪退 环境变量没有配置好,必须有Java_Home (如果配置还有闪退 有可能是jdk版本过低或者 过高)
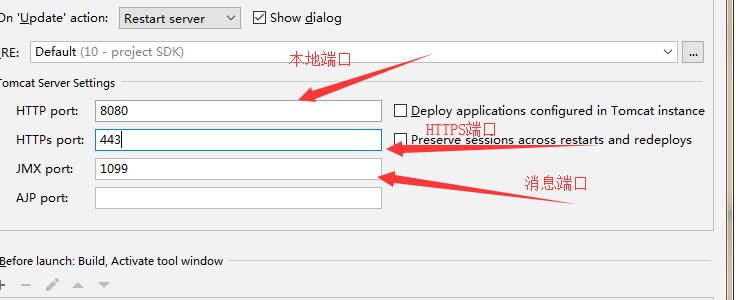
2.打开后 不到 几秒中就退出了,端口占用 (一个端口是网络通讯的口子,这口子是一个数字,一个端口只能给一个协议占用)你的电脑启动了2个tomcat 非要启动两个tomcat 可以修改另一个tomcat端口这样就不冲突了
默认配置的tomca访问
默认端口数字是8080
http://localhost:8080
http://127.0.0.1:8080
http://地址:端口
测试启动tomcat服务器,然后用本地连接进行测试(会弹出tomcat网页)
如果他可以在本机没有配置jdk环境的情况下运行 只需要将你的jdk放入到tomcat包中 在写个批处理指定 jdk路径
set Java_Home ./ jdk-11.0.2
set path=./ jdk-11.0.2/bin;%path%
bin/startup.bat
配置在你的bat文件中 用bat执行 在没有配置jdk的环境下都可以执行
tomcat一定要到官网上下载纯净版 比较干净
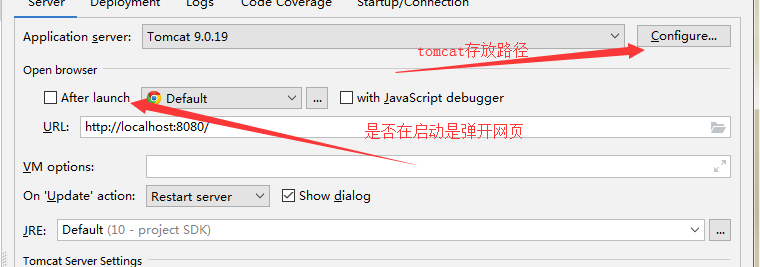
idea配置tomcat运行环境:
1.创建maven工程 web工程
2.![2f1c9e1a6d07e1629727164c9434781cb3568a68]() 3.
3.![752f9bdee84aced651071ec1cba0b0bb85213f0b]() 4.
4.![a9e5ae50390547db910bebb5dcbed52420502944]()
5.![f9169d63648f4a5a3389a54d1ad33aadaa386b33]() 6.
6.![a9fa3b0130835b3bedbbde81b87a869ee8f43f8c]()
7.![561d7c969e0989f3ee18e92db82a610867d12128]()
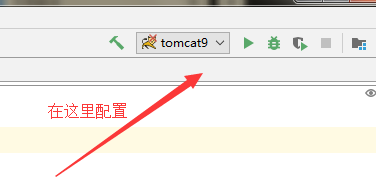 3.
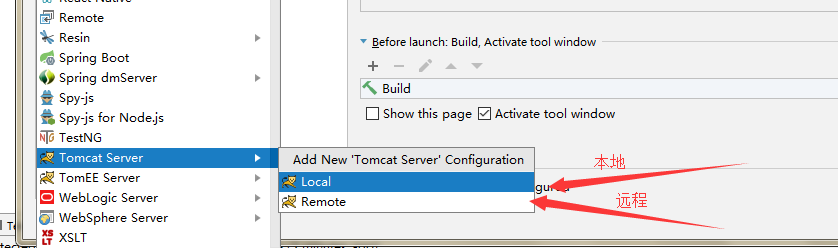
3.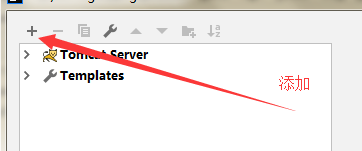 4.
4.
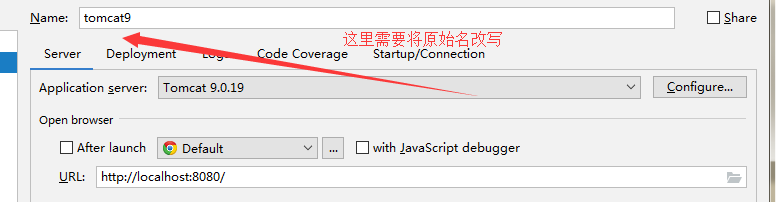 6.
6.