
【翻译】Sklearn与TensorFlow机器学习实用指南 ——第12章 设备和服务器上的分布式TensorFlow(下)
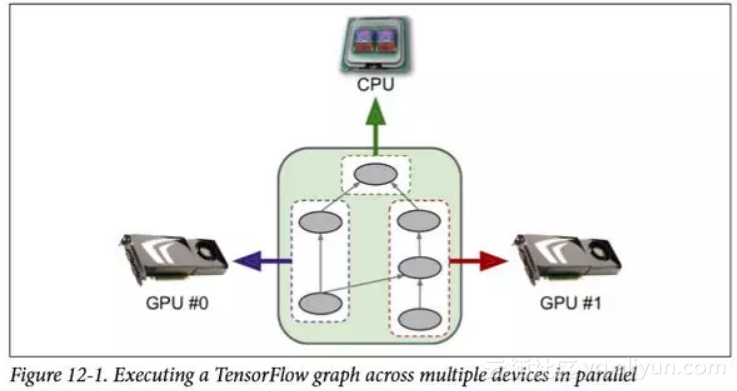
并行运行 当 TensorFlow 运行图时,它首先找出需要求值的节点列表,然后计算每个节点有多少依赖关系。 然后 TensorFlow 开始求值具有零依赖关系的节点(即源节点)。 如果这些节点被放置在不同的设备上,它们显然会被并行求值。 如果它们放在同一个设备上,它们将在不同的线程中进行求值,因此它们也可以并行运行(在单独的 GPU 线程或 CPU 内核中)。 TensorFlow 管理每个设备上的线程池以并行化操作(参见图 12-5)。 这些被称为 inter-op 线程池。 有些操作具有多线程内核:它们可以使用其他线程池(每个设备一个)称为 intra-op 线程池(下面写成内部线程池)。 <p style="text-align:center">![image](https://yqfile.alicdn.com/d