说明:这个插件可以将构建的产物(例如:Jar)发布到FTP中去。
官方说明:Publish Over FTP Plugin
安装步骤:
系统管理→管理插件→可选插件→Artifact Uploaders→Publish Over FTP Plugin
系统设置
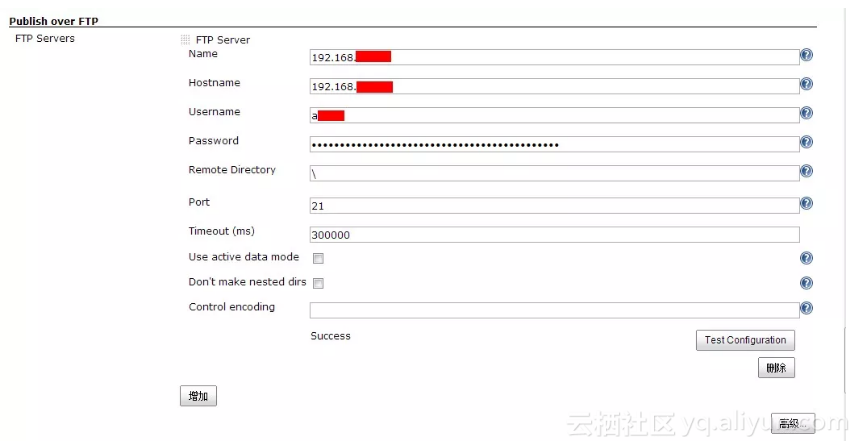
FTP Server Name:给你自己看的名字,爱叫什么叫什么
Hostname:主机IP或者域名
Username:ftp登陆用户名
Password:ftp密码
Remote Directory:远程根目录(建议设置为:/)
![2c49059e9f8e29533144a84ca563106afd90200a]()
图1 系统设置基本界面
点击Test Configuration上面的高级,如下图:
Port:端口(不知道问管理员去)
Timeout (ms):超时时间(毫秒)
Use active data mode: (未选中)默认选项使用PASV(被动模式),选中使用PORT (主动模式)
Don’t make nested dirs:不创建下级目录(具体的自己看帮助)
![7035cd8498b336262536fd080b640bf71ab9a16f]()
图2 系统设置高级界面
上图右下角还有一个高级选项。有兴趣的自己可以折腾下。提示:你需要先保存后,刷新页面,在配置。不然有个选项无法选择的。
项目配置
启用步骤:
构建后操作→Add post-build action→Send build artifacts over FTP
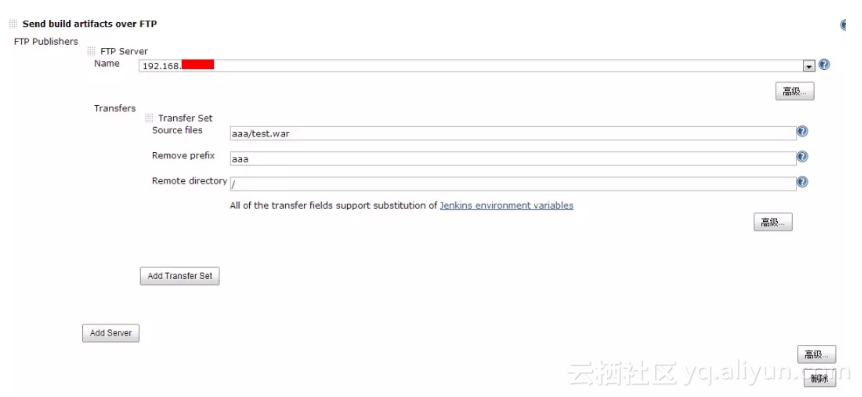
FTP Server Name:选个一个你在系统设置里配置的配置的名字
Transfer Set Source files:需要上传的文件(注意:相对于工作区的路径,可以是单个文件也可以是目录)
Remove prefix:移除目录(只能指定Transfer Set Source files中的目录)
Remote directory:远程目录(根据你的需求填写吧,因为我这儿是测试,所以偷懒直接用/)
![d852986b04d078657545822c124f6724642f2253]()
图3 项目设置基本界面
点击Remote directory后面的高级,如下图
Exclude files:排除的文件(在你传输目录的时候很有用,使用通配符,例如:**/*.log,**/*.tmp,.git/)
Pattern separator:分隔符(配置Exclude files和Source files的分隔符。如果你这儿更改了,上面的内容也需要更改)
No default excludes:禁止默认的排除规则(具体的自己看帮助)
Make empty dirs:此选项会更改插件的默认行为。默认行为是匹配该文件是否存在,如果存在则创建目录存放。选中此选项会直接创建一个目录存放文件,即使是空目录。(个人理解)
Flatten files:只在ftp上建立文件,不创建目录(除了远程目录)
Remote directory is a date format:远程目录建立带日期的文件夹(需要在Remote directory中配置日期格式),具体格式参考下表:
| Remote directory |
Directories created |
'qa-approved/'yyyyMMddHHmmss |
qa-approved/20101107154555 |
'builds/'yyyy/MM/dd/'build-${BUILD_NUMBER}' |
builds/2010/11/07/build-456 (if the build was number 456) |
yyyy_MM/'build'-EEE-d-HHmmss |
2010_11/build-Sun-7-154555 |
yyyy-MM-dd_HH-mm-ss |
2010-11-07_15-45-55 |
Clean remote:上传前会删除远程目录中的所有的文件(血的教训啊,测试的时候用的是运营小组的ftp,然后一不小心就把他们的数据删除了,害的我去做数据恢复。)
ASCII mode:文件传输的方式,一般默认不选。
![a0e1ed98d40c063a97db3353fe4041793bb002bf]()
图4 项目设置高级界面
好了,常用的选项就这些,其他的自己折腾吧。这个插件适合动手能力强的人。
原文发布时间为:2018-11-26
本文来自云栖社区合作伙伴“Java杂记”,了解相关信息可以关注“Java杂记”。