变量和对象
在《learning python》中的一个观点:变量无类型,对象有类型
在python中,如果要使用一个变量,不需要提前声明,只需要在用的时候,给这个变量赋值即可。这里特别强调,只要用一个变量,就要给这个变量赋值。
所以,像这样是不行的。
>>> x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'x' is not defined
反复提醒:一定要注意看报错信息。如果光光地写一个变量,而没有赋值,那么python认为这个变量没有定义。赋值,不仅仅是给一个非空的值,也可以给一个空值,如下,都是允许的
>>> x = 3
>>> lst = []
>>> word = ""
>>> my_dict = {}
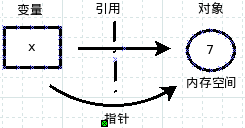
看到上面的图了吧,从图中就比较鲜明的表示了变量和对象的关系。所以,严格地将,只有放在内存空间中的对象(也就是数据)才有类型,而变量是没有类型的。
同一个变量可以同时指向两个对象吗?
>>> x = 4
>>> x = 5
>>> x
5
变量x先指向了对象4,然后指向对象5,自动跟第一个对象4解除关系。再看x,引用的对象就是5了。那么4呢?一旦没有变量引用它了,便成了垃圾,python有一个自动的收回机制。
例如:
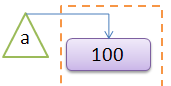
>>> a = 100 #完成了变量a对内存空间中的对象100的引用
然后,又操作了:
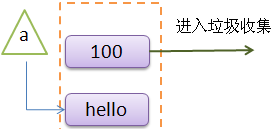
>>> a = "hello"
如下图所示:
原来内存中的那个100就做为垃圾被收集了。而且,这个收集过程是python自动完成的,不用我们操心。
那么,python是怎么进行垃圾收集的呢?在Quora上也有人问这个问题,我看那个回答很精彩,做个链接:Python (programming language): How does garbage collection in Python work?
is和==的效果
以上过程的原理搞清楚了,下面就可以深入一步了。
>>> l1 = [1,2,3]
>>> l2 = l1
这个操作中,l1和l2两个变量,引用的是一个对象,都是[1,2,3]。何以见得?如果通过l1来修改[1,2,3],l2引用对象也修改了,那么就证实这个观点了。
>>> l1[0] = 99 #把对象变为[99,2,3]
>>> l1 #变了
[99, 2, 3]
>>> l2 #真的变了吔
[99, 2, 3]
再换一个方式:
>>> l1 = [1,2,3]
>>> l2 = [1,2,3]
>>> l1[0] = 99
>>> l1
[99, 2, 3]
>>> l2
[1, 2, 3]
l1和l2貌似指向了同样的一个对象[1,2,3],其实,在内存中,这是两块东西,互不相关。只是在内容上一样。所以,当通过l1修改引用对象的后,l2没有变化。
进一步还能这么检验:
>>> l1
[1, 2, 3]
>>> l2
[1, 2, 3]
>>> l1 == l2 #两个相等,是指内容一样
True
>>> l1 is l2 #is 是比较两个引用对象在内存中的地址是不是一样
False #前面的检验已经说明,这是两个东东
>>> l3 = l1 #顺便看看如果这样,l3和l1应用同一个对象
>>> l3
[1, 2, 3]
>>> l3 == l1
True
>>> l3 is l1 #is的结果是True
True
某些对象,有copy函数,通过这个函数得到的对象,是一个新的还是引用到同一个对象呢?
实验:
>>> l1
[1, 2, 3]
>>> l2 = l1[:]
>>> l2
[1, 2, 3]
>>> l1[0] = 22
>>> l1
[22, 2, 3]
>>> l2
[1, 2, 3]
>>> adict = {"name":"hiekay","web":"hiekay.github.io"}
>>> bdict = adict.copy()
>>> bdict
{'web': 'hiekay.github.io', 'name': 'hiekay'}
>>> adict["email"] = "hiekay@gmail.com"
>>> adict
{'web': 'hiekay.github.io', 'name': 'hiekay', 'email': 'hiekay@gmail.com'}
>>> bdict
{'web': 'hiekay.github.io', 'name': 'hiekay'}
不过,python不总按照前面说的方式,比如小数字的时候
>>> x = 2
>>> y = 2
>>> x is y
True
>>> x = 200000
>>> y = 200000
>>> x is y #什么道理呀,小数字的时候,就用缓存中的.
False
>>> x = 'hello'
>>> y = 'hello'
>>> x is y
True
>>> x = "what is you name?"
>>> y = "what is you name?"
>>> x is y #不光小的数字,短的字符串也是
False
赋值是不是简单地就是等号呢?从上面得出来,=的作用就是让变量指针指向某个对象。