



Python正则表达式初识(八)
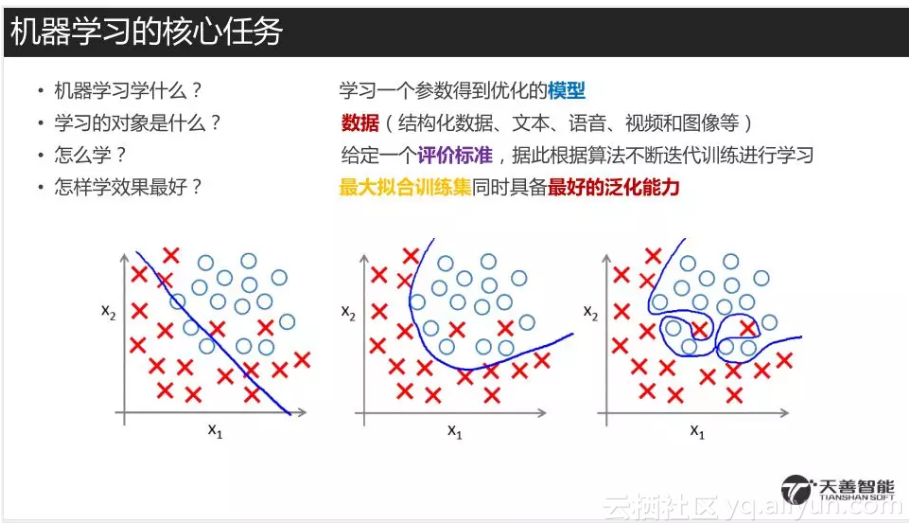
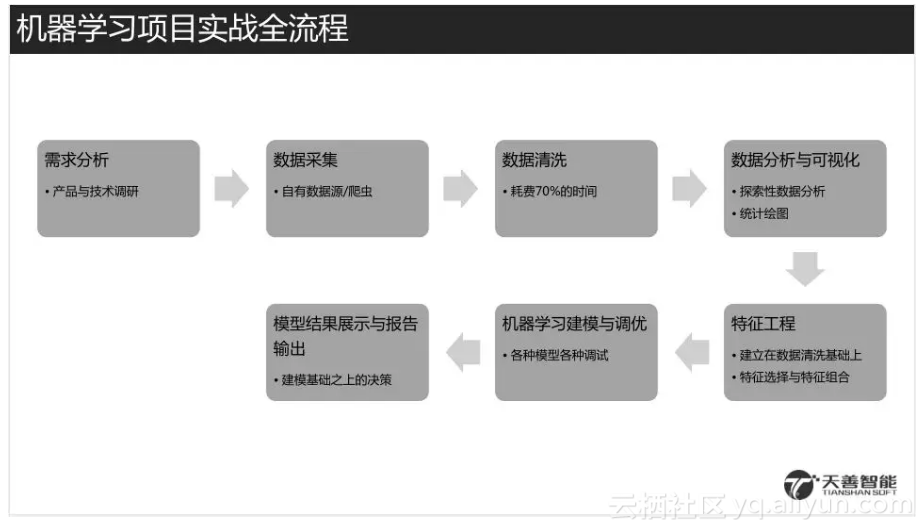
继续分享Python正则表达式的基础知识,今天给大家分享的特殊字符是“\w”和“\W”,具体的教程如下。 1、“\w”代表的意思是该字符为任意字符,但是和特殊字符“.”的意思不同。“\w”代表的字符主要包括26个大写字母A到Z,即[A-Z]、26个小写字母a到z,即[a-z]、10个阿拉伯数字0到9,即[0-9]和下划线“_”。总结起来就是,“\w”代表的意思是[A-Za-z0-9_]中任意一个字符。“.” 代表的意思是任意字符,其范围比“\w”代表的意思要广。 下面是具体的代码演示,如下图所示: 可以看到此时用的是特殊字符中括号来代替特殊字符“\w”,匹配成功。 2、现在将[A-Za-z0-9_]改为\w,如下图所示。 可以看到仍然可以匹配成功。 3、将原始字符串改为“加A油”,如下图所示。 可以看到仍然可以匹配成功。 4、将原始字符串改为“加_油”,如下图所示。 可以看到仍然可以匹配成功。 5、当将原始字符串改为“加-油”,如下图所示。 可以看到此时就不可以匹配成功了,因为字符“-”并在包括在\w涵盖的范围之内。 6、“\W”代表的意思与“\w”刚刚相反,也就是匹配除了[A-Za-...