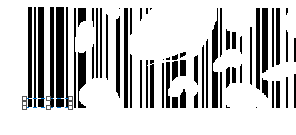前言
渣渣一枚,萌新一个,会划水,会喊六六
上一篇文章:蓝鲸安全CTF打卡题——第一期密码学
个人博客:https://www.cnblogs.com/lxz-1263030049/
本文首发先知社区:蓝鲸安全CTF打卡题——第一期隐写术
i春秋:蓝鲸安全CTF打卡题——第一期隐写术
再过几天就是中秋节了,我打算尽自己最大的能力把蓝鲸安全平台上面的打卡题目的writeup整理出来。
有什么错误的地方 希望各位大佬指正(谢谢Orz)
![img_93bc2dd65f573a16dbde48abaab6e1c7.jpe]()
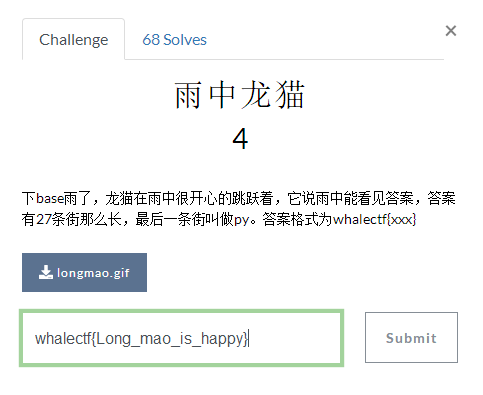
一:雨中龙猫
![img_ebc9cd2c48c7d5dfa3878ce4d181bc94.png]()
知识点
图片源码隐写、base64编码
解题思路
使用普通的记事本打卡图片就可以了,这一题感觉有点坑(MISC不按常规套路出牌),使用常规的方法没有想出来,后来看了塔主的解题视频(5分钟的) 里面说了一下关于base64的内容,所以想到了方法(HHHH)
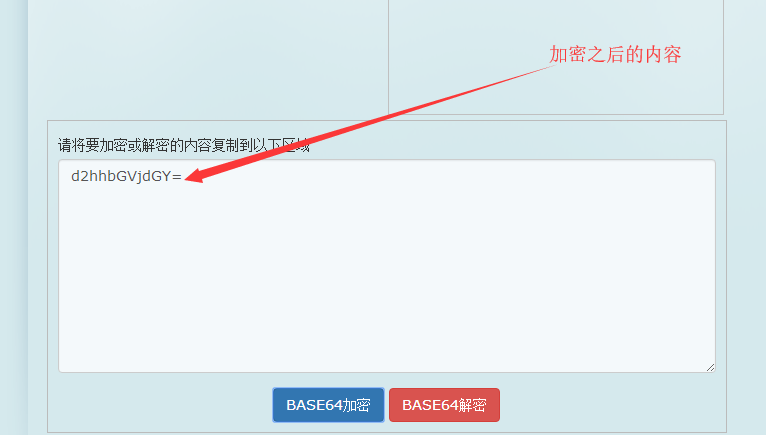
由于题目中提示有答案的格式,所以先对whalectf进行base64加密(base64加解密平台)
![img_be4145a5e9db9a66e272e5874e12b870.png]()
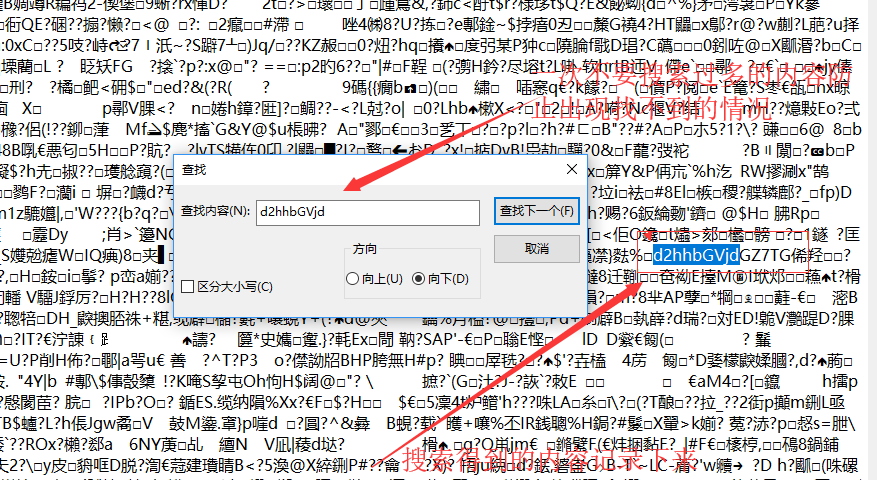
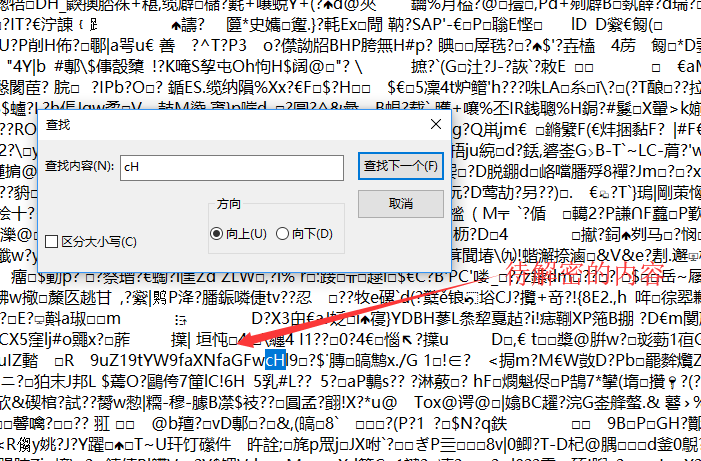
在记事本中搜索内容d2hhbGVjd(一次一次的尝试,每一次尝试就减少几个字符)
![img_b1417825d131a3f306c8fab630a57242.png]()
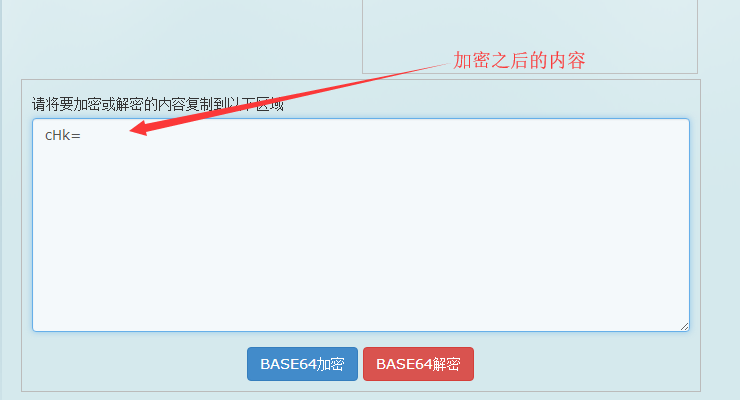
我们能够看到最后提供的提示是:py,同样的操作,我们进行base64操作
![img_34a51cb7677d03be0d1b860957bb8500.png]()
我们继续刚刚的操作就会得到
![img_878cb55cc52dadc856a7563d9d0057dc.png]()
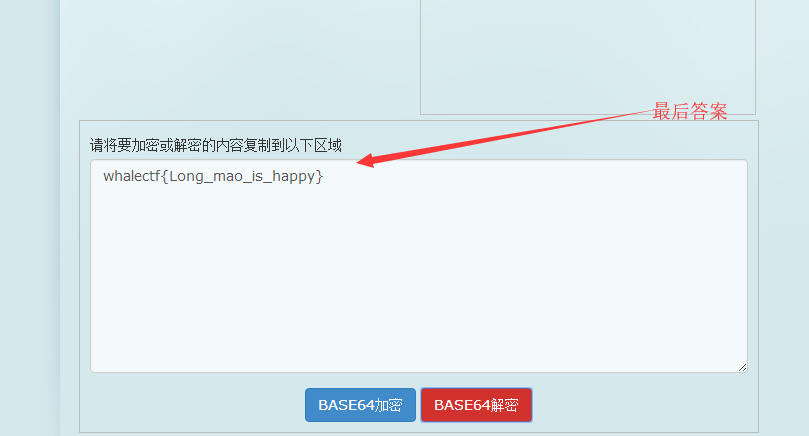
合并两次得到的结果就会得到:d2hhbGVjdGZ7TG9uZ19tYW9faXNfaGFwcHl9
base64解密之后得到:
![img_5b19b2afe1a372d6d7a7b3077e72536d.png]()
最后得到答案:whalectf{Long_mao_is_happy}
二:追加数据
![img_478291da8464244b3f8c4df5f235a483.png]()
知识点
文件绑定、word隐藏
文件绑定的方法
在cmd中
copy /b 1.jpg+2.txt 3.jpg
解题思路
拿到图片,在kali里面使用binwalk工具进行分析
使用命令:
binwalk whalediary.jpg
![img_c54caf79395abcae5efdeefc2954b2cc.png]()
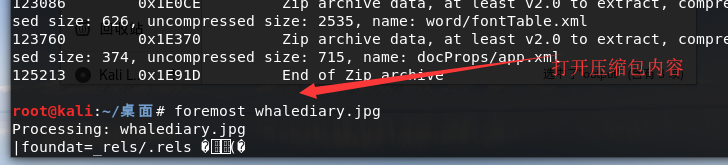
可以看到一个zip压缩包隐藏在里面,使用foremost命令
使用命令:foremost whalediary.jpg
![img_c40fea945f49d860b9a841edb951e546.png]()
使用word,打开docx文件就会得到(由于我事先把word中的隐藏关闭了,所以打开的文档可能和没有关闭的人的不同)
![img_f5eb8b12922ae98c633671f73d0295ab.png]()
我们只需要注意每一段后面的字母就好,把他们组合起来就是答案(可是我没有读懂QAQ)
三:追加数据
![img_99056d5366ceb54e23df9129ad4e7202.png]()
知识点
PNG文件格式、zlib压缩数据、二维码识别
解题思路
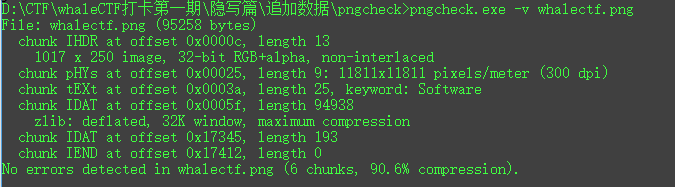
首先使用pngcheck工具检查图片的IDAT位
使用的命令为:pngcheck.exe -v whalectf.png
![img_cd9853d239bb6548ce4fa8d59235a833.png]()
可以看到一个IDAT位为0x17345,长度为193 用winhex打开图片,找到IDTA块对应的位置 如图所示截取:
![img_46b2ff831d7fb32282d98305f196efa1.png]()
这里不需要截取长度标志位C1和IDAT图像数据块和最后四位的CRC冗余校验码,使用如下脚本进行分析即可:
# python2
#! /usr/bin/env python
import zlib
import binascii
IDAT='789CA552B911C3300C5B09D87FB99C65E2A11A17915328FC8487C0C7E17BCEF57CCFAFA27CAB749B8A8E3E754C4C15EF25F934CDFF9DD7C0D413EB7D9E18D16F15D2EB0B2BF1D44C6AE6CAB1664F11933436A9D0D8AA6B5A2D09BA785E58EC8AB264111C0330A148170B90DA0E582CF388073676D2022C50CA86B63175A3FD26AE1ECDF2C658D148E0391591C9916A795432FBDDF27F6D2B71476C6C361C052FAA846A91B22C76A25878681B7EA904A950E28887562FDBC59AF6DFF901E0DBC1AB'.decode('hex')
result = binascii.hexlify(zlib.decompress(IDAT))
bin = result.decode('hex')
print bin
print '\r\n'
print len(bin)
就会得到如下所示:
![img_abf4bb140f5ef715000d6a424d5984ef.png]()
一串0和1的数据 长度为1024是一个正方形 可以想到是要生成一个二维码,把生成的0和1放在result.txt里面,用如下脚本生成二维码
# python2
#! /usr/bin/env python
import Image
MAX = 32
pic = Image.new('RGB',(MAX*9,MAX*9))
f = open('result.txt','r')
str = f.read()
i = 0
for y in range(0,MAX*9,9):
for x in range(0,MAX*9,9):
if(str[i] == '1'):
for n in range(9):
for j in range(9):
pic.putpixel([x+j,y+n],(0,0,0))
else:
for k in range(9):
for l in range(9):
pic.putpixel([x+l,y+k],(255,255,255))
i = i+1
pic.show()
pic.save("flag.png")
f.close()
得到二维码:
![img_4b92dc51965506307badac5ec9e88d4f.png]()
使用QR_Research或者其它工具也是可以的,扫描后就出现flag
![img_f298e7b346cf9aac0c3a08b32288f9aa.png]()
最后得到答案:whale{QR_code_and_png}
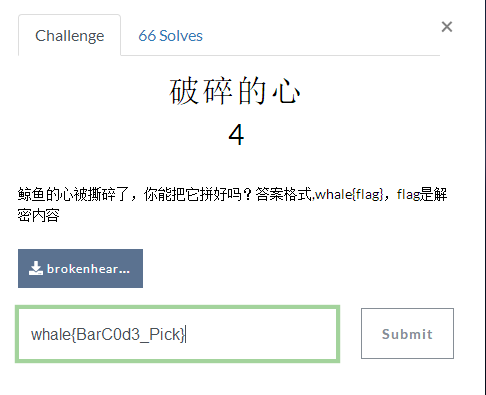
四:破碎的心
![img_83eef68fc2a7ff3dbe87f7ff9d74a775.png]()
知识点
条形码
解题思路
我们把图片下载下来之后会发现这是一个不完整的条形码
![img_f95834359fc1ddb375af6e7acab571cb.png]()
我们选择其中的条形码还原即可 在画图里,先用矩形框选择一些连续的条纹,按住ctrl,按上下键不断还原即可
![img_71dbbdd93b7331bcfb890e8df7562e86.png]()
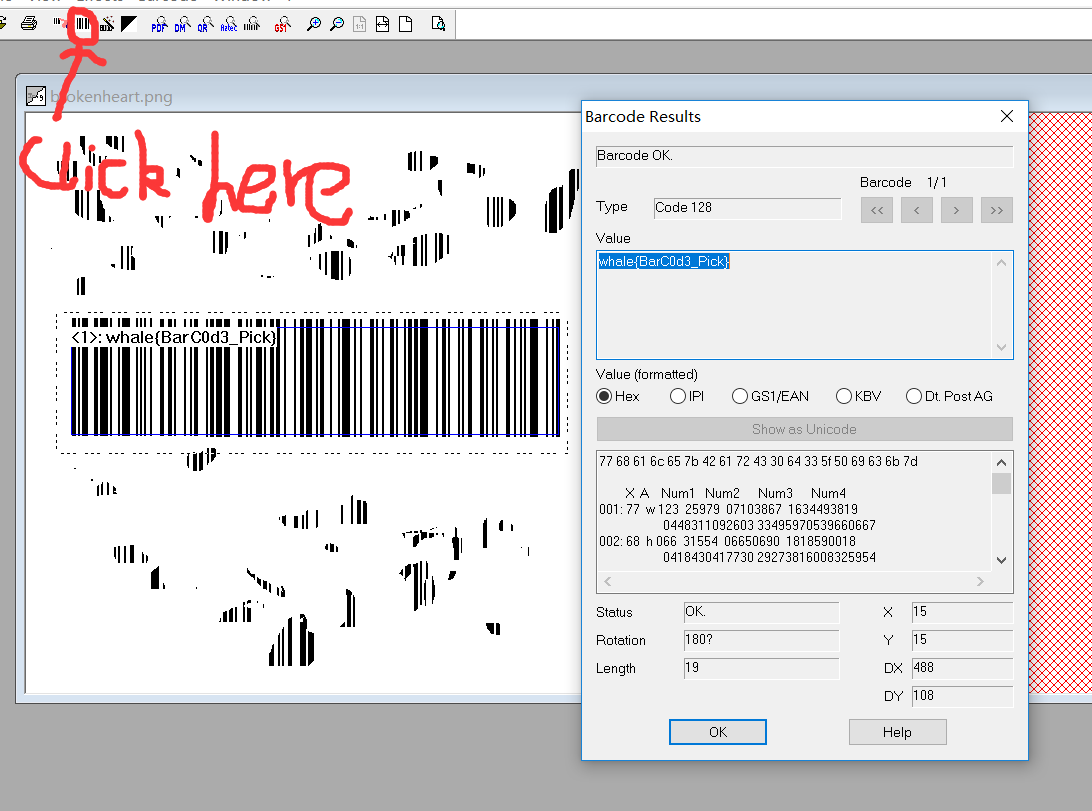
最后用BcTester打开即可得到flag
![img_d7fe305ee1a5fd65347015712082ba6f.png]()
最后得到答案:whale{BarC0d3_Pick}
五:我们不一样
![img_bf4574356d9f22f8349b85eb6b072b14.png]()
知识点
双图对比 compare命令的使用
解题思路
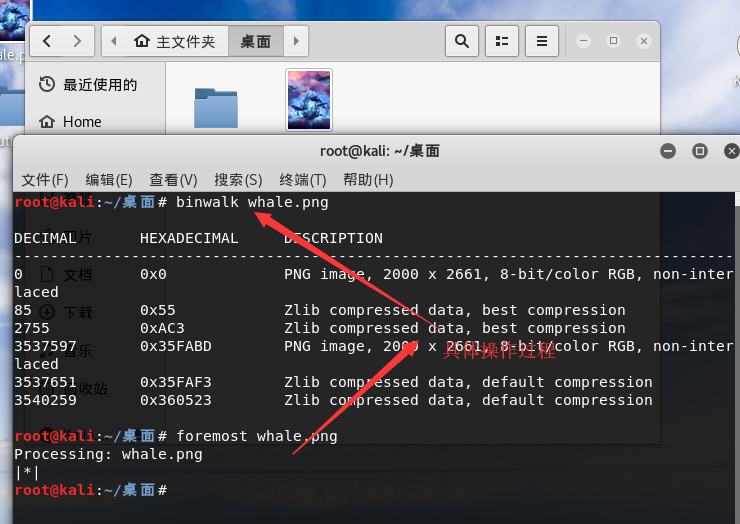
首先使用Linux中的binwalk命令
![img_29032fa17166965ea90dad84dc463e01.png]()
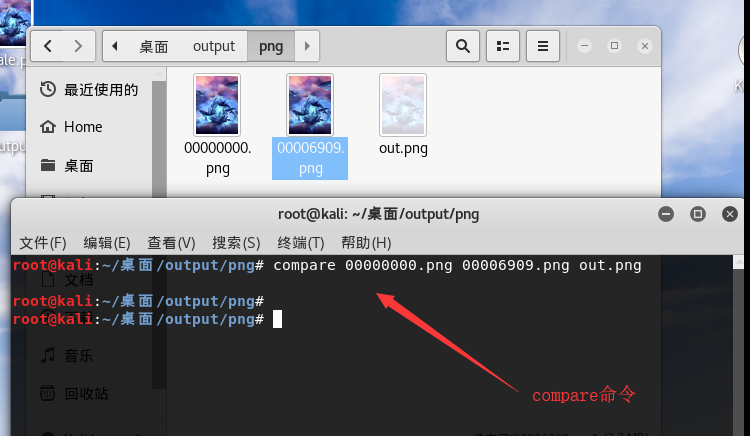
我们可以看到有两张图 使用compare命令
![img_3aa80f487daa5390cc2ea0ba3d40b943.png]()
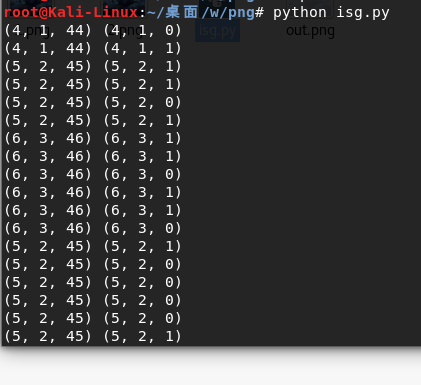
看到图片左下角有一个非常小的变化,使用python脚本打印出来
# python2
#coding:utf-8
import Image
import random
img1 = Image.open("1.png")
im1 = img1.load()
img2 = Image.open("2.png")
im2 = img2.load()
a=''
i=0
s=''
for y in range(img1.size[1]):
for x in range(img1.size[0]):
if(im1[x,y]!=im2[x,y]):
print im1[x,y],im2[x,y]
if i == 8: #以8个为一组 打印出字符串
s=s+chr(int(a,2))
a=''
i=0
a=a+str(im2[x,y][2])
i=i+1
s=s+'}'
print s
运行之后就会得到:
![img_f691916efcfacedfed9cc98db8a1ce87.png]()
我们可以看到它的蓝色通道不一样,它是把蓝色像素转换成为0和1,8个位一组转换成字符,当然 flag也是在
最后的答案:whale{w3_ar3_d1ffe2en7}
六:黑白打字机
![img_86a97edabc84047078ea689159569eb2.png]()
知识点
二维码、steganography、五笔编码
解题思路
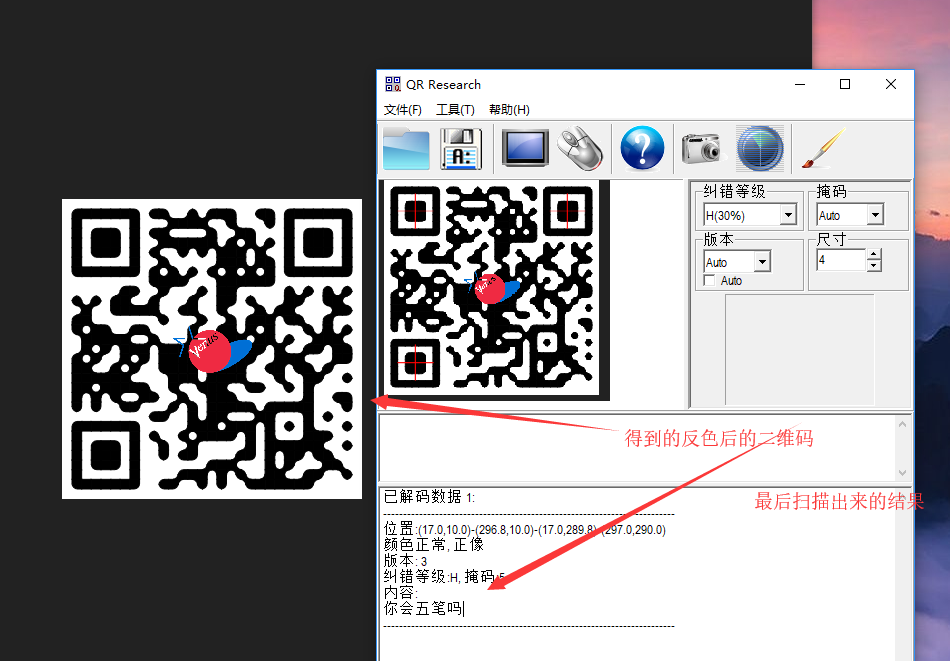
把图片下载之后发现,不是正确的二维码,需要使用光影魔术手进行反色处理,再使用QR_Research就可以得到:
![img_3dd73e6755f26ae85fa8819976750000.png]()
提示我'你会五笔吗'
图片的名字yhpargonagets反过来是steganography,
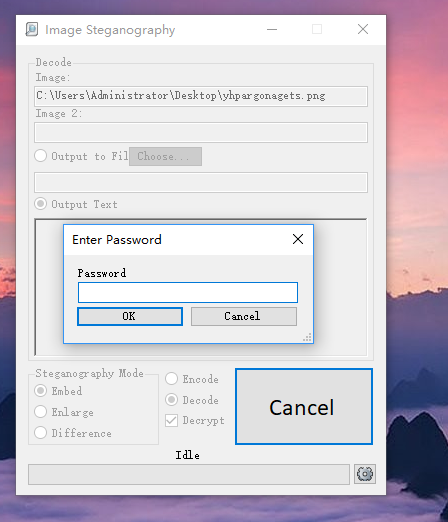
百度得到这个工具(下载需要积分,不过我有)我们使用这个工具解密,勾选Decode和Decrypt,发现需要密码
![img_3dcfa441c1e20756c7116a339a288cc7.png]()
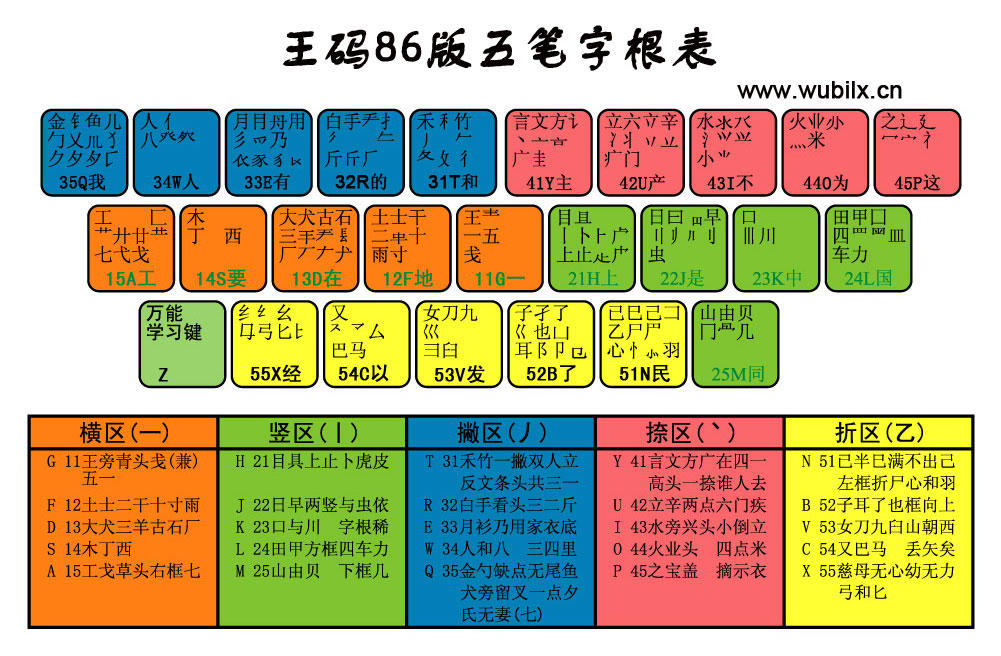
之前提示我们的话,我们针对每个字都进行五笔解密查询(一定要86版五笔)
![img_73362ea871e7a476ff98a68a1b75dd1c.jpe]()
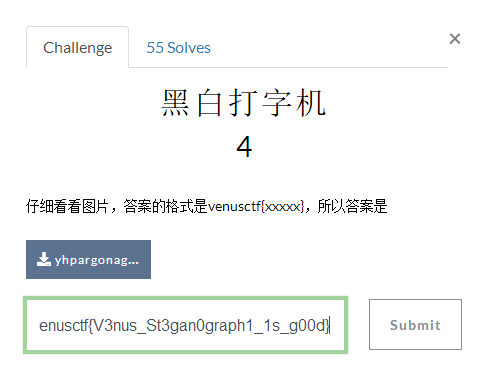
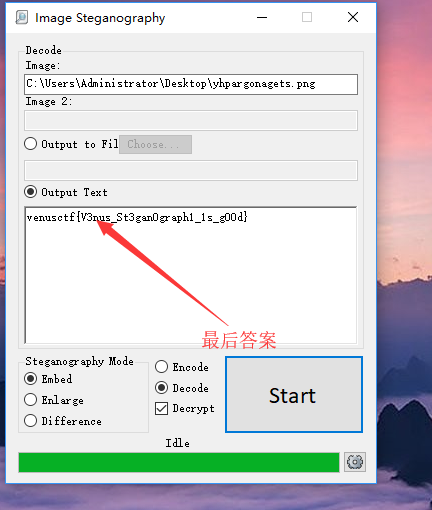
最终得到一串字符wqiywfcugghgttfnkcg,以此当密码输入,就会得到:
![img_3ba0c4cdc6caf800dd7108dafb2b1e44.png]()
最后得到答案:venusctf{V3nus_St3gan0graph1_1s_g00d}
参考资料:
Image Steganography: https://download.csdn.net/download/qq_41187256/10682803
CTF Wiki: https://ctf-wiki.github.io/ctf-wiki/misc/introduction/
您可以考虑给博主来个小小的打赏以资鼓励,您的肯定将是我最大的动力。
关于作者:潜心于网络安全学习。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!