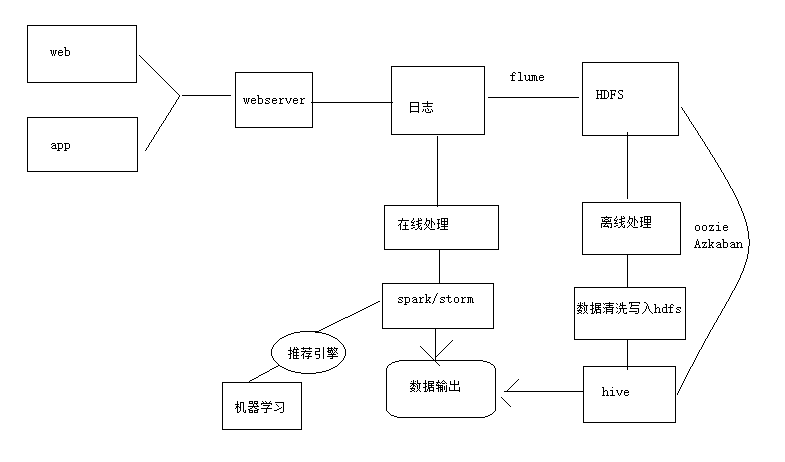

大数据查询——HBase读写设计与实践
背景介绍 本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。本项目将其置于下游数据处理 Hadoop 分布式平台来实现此需求。下面列一些具体的需求指标: 1、数据量:目前 check 表的累计数据量为 5000w+ 行,11GB;opinion 表的累计数据量为 3 亿 +,约 100GB。每日增量约为每张表 50 万 + 行,只做 insert,不做 update。 2、查询要求:check 表的主键为 id(Oracle 全局 id),查询键为 check_id,一个 check_id 对应多条记录,所以需返回对应记录的 list; opinion 表的主键也是 id,查询键是 bussiness_no 和 buss_type,同理返回 list。单笔查询返回 List 大小约 50 条以下,查询频率为 100 笔 / ...