- 背景
- confirmCallback 确认模式
- returnCallback 未投递到 queue 退回模式
- shovel-plugin 跨机房可靠投递
背景
在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两个选项用来控制消息的投递可靠性模式。
rabbitmq 整个消息投递的路径为:
producer->rabbitmq broker cluster->exchange->queue->consumer
message 从 producer 到 rabbitmq broker cluster 则会返回一个 confirmCallback 。
message 从 exchange->queue 投递失败则会返回一个 returnCallback 。我们将利用这两个 callback 控制消息的最终一致性和部分纠错能力。
confirmCallback 确认模式
在创建 connectionFactory 的时候设置 PublisherConfirms(true) 选项,开启 confirmcallback 。
CachingConnectionFactory factory = new CachingConnectionFactory();
factory.setPublisherConfirms(true);//开启confirm模式
RabbitTemplate rabbitTemplate = new RabbitTemplate(factory);
rabbitTemplate.setConfirmCallback((data, ack, cause) -> {
if (!ack) {
log.error("消息发送失败!" + cause + data.toString());
} else {
log.info("消息发送成功,消息ID:" + (data != null ? data.getId() : null));
}
});
我们来看下 ConfirmCallback 接口。
public interface ConfirmCallback {
/**
* Confirmation callback.
* @param correlationData correlation data for the callback.
* @param ack true for ack, false for nack
* @param cause An optional cause, for nack, when available, otherwise null.
*/
void confirm(CorrelationData correlationData, boolean ack, String cause);
}
重点是 CorrelationData 对象,每个发送的消息都需要配备一个 CorrelationData 相关数据对象,CorrelationData 对象内部只有一个 id 属性,用来表示当前消息唯一性。
发送的时候创建一个 CorrelationData 对象。
User user = new User();
user.setID(1010101L);
user.setUserName("plen");
rabbitTemplate.convertAndSend(exchange, routing, user,
message -> {
message.getMessageProperties().setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);
return message;
},
new CorrelationData(user.getID().toString()));
这里将 user ID 设置为当前消息 CorrelationData id 。当然这里是纯粹 demo,真实场景是需要做业务无关消息 ID 生成,同时要记录下这个 id 用来纠错和对账。
消息只要被 rabbitmq broker 接收到就会执行 confirmCallback,如果是 cluster 模式,需要所有 broker 接收到才会调用 confirmCallback。
被 broker 接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的 returnCallback 。
returnCallback 未投递到queue退回模式
confrim 模式只能保证消息到达 broker,不能保证消息准确投递到目标 queue 里。在有些业务场景下,我们需要保证消息一定要投递到目标 queue 里,此时就需要用到 return 退回模式。
同样创建 ConnectionFactory 到时候需要设置 PublisherReturns(true) 选项。
CachingConnectionFactory factory = new CachingConnectionFactory();
factory.setPublisherReturns(true);//开启return模式
rabbitTemplate.setMandatory(true);//开启强制委托模式
rabbitTemplate.setReturnCallback((message, replyCode, replyText,
exchange, routingKey) ->
log.info(MessageFormat.format("消息发送ReturnCallback:{0},{1},{2},{3},{4},{5}", message, replyCode, replyText, exchange, routingKey)));
这样如果未能投递到目标 queue 里将调用 returnCallback ,可以记录下详细到投递数据,定期的巡检或者自动纠错都需要这些数据。
shovel-plugin 跨机房可靠投递
RabbitMQ 在跨机房集成提供了一个不错的插件 shovel 。使用 shovel-plugin 插件非常方便,shovel 可以接受机房之间的网络断开、机器下线等不稳定因素。
这里有两个 broker :
10.211.55.3 rabbit_node1
10.211.55.4 rabbit_node2
我们希望将发送给 rabbit_node1 plen.queue 的消息传输到 rabbit_node2 plen.queue 中。我们先开启 __rabbit_node1 的 shovel-plugin__。
先看下当前 RabbitMQ 版本是否安装了 shovel-plugin,如果有的话直接开启。
rabbitmq-plugins list
rabbitmq-plugins enable rabbitmq_shovel
rabbitmq-plugins enable rabbitmq_shovel_management
然后就可以在 Admin 面板里看到这个设置选项,怎么设置这里就不介绍了。主要就是配置下 amqp 协议地址,amqp://user:password@server-name/my-vhost 。
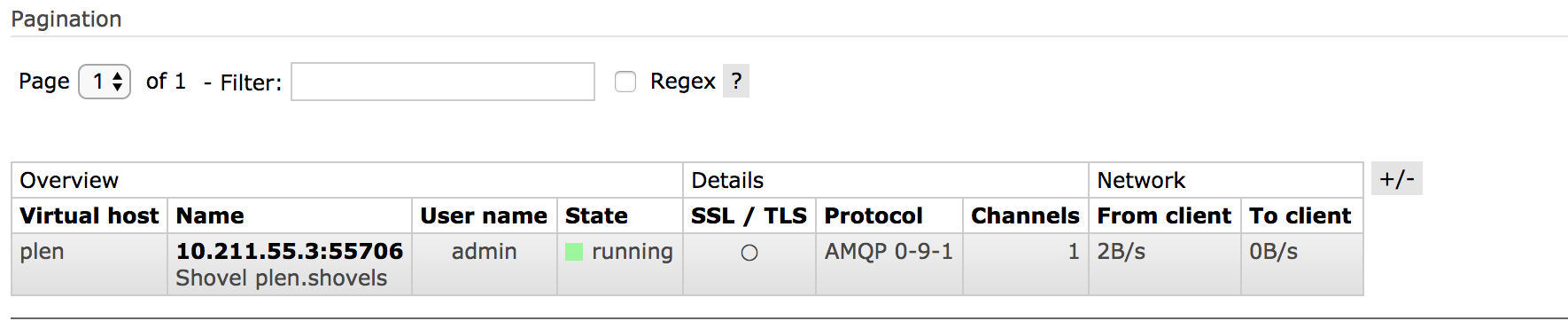
如果配置没有问题的话,应该是这样的一个状态,说明已经顺利连接到 __rabbit_node2 broker__ 。
![RabbitMQ 可靠投递]()
![RabbitMQ 可靠投递]()
我们来看下 rabbit_node1 和 rabbit_node2 的 Connections 面板。
__rabbit_node1(10.211.55.3):__
![RabbitMQ 可靠投递]()
__rabbit_node2(10.211.55.4):__
![RabbitMQ 可靠投递]()
RabbitMQ shovel-plugin 插件在 rabbit_node1 broker 创建了两个 tcp 连接,端口 39544 连接是用来消费 plen.queue 里的消息,端口 55706 连接是用来推送消息给 rabbit_node2 。
我们来看下 __rabbit_node1 tcp__ 连接状态:
tcp6 0 0 10.211.55.3:5672 10.211.55.3:39544 ESTABLISHED
tcp 0 0 10.211.55.3:55706 10.211.55.4:5672 ESTABLISHED
__rabbit_node2 tcp__ 连接状态:
tcp6 0 0 10.211.55.4:5672 10.211.55.3:55706 ESTABLISHED
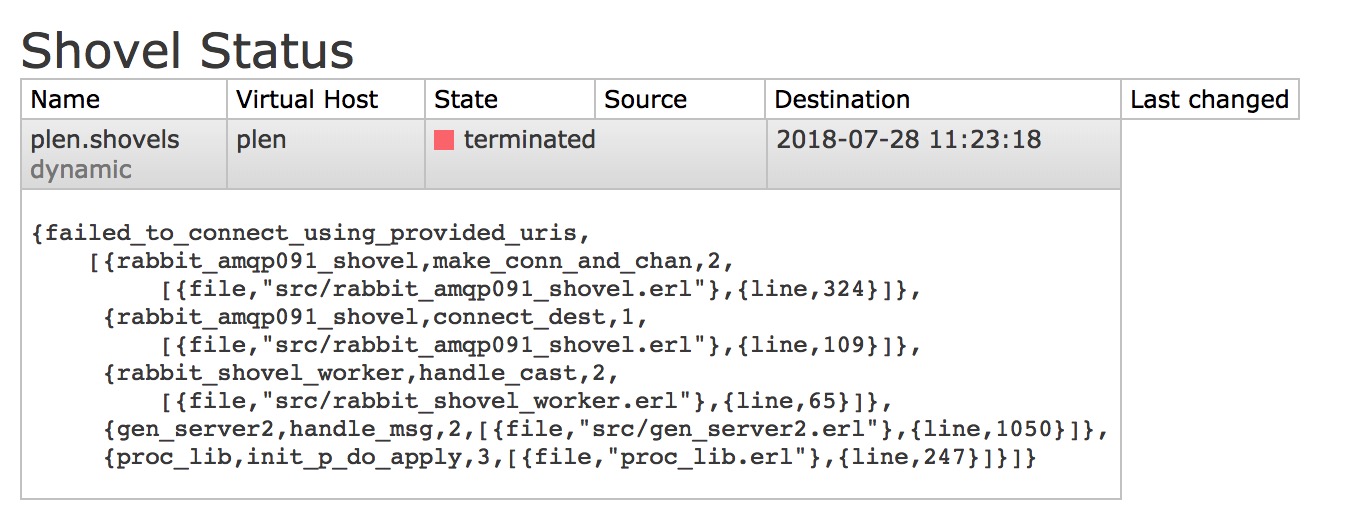
为了验证 shovel-plugin 稳定性,我们将 __rabbit_node2__ 下线。
![RabbitMQ 可靠投递]()
然后再发送消息,发现消息会现在 rabbit_node1 plen.queue 里待着,一旦 shovel-plugin 连接恢复将消费 rabbit_node1 plen.queue 消息,然后投递给 __rabbit_node2 plen.queue__ 。
作者:王清培 (沪江集团资深JAVA架构师)