进行了解析.知道dubbo会对zookeeper的信息进行一个本地的文件缓存.如果你只是简单的回答出这个本地的文件缓存,可能面试官会点到为止,但是如果你按照我那样从源码角度分析,甚至连缓存到哪个磁盘文件都一清二楚,那么面试官必然会根据这个问题深入问下去.既然要深入问下去,那他会从哪个角度问呢?
比如公司新来了妹子,老司机们在下班的时候总会套路一下,问她们你男朋友怎么不接你下班啊.这个时候妹子的回答往往也就两个,一个是我没有男朋友啊,另一个是他忙啊(这说明她有男朋友).从这里例子就可以很容易看出,你的发言,对对方的回答我们是能一定程度预判的.再比如,我一直自称肥朝,假如你发现我其实没有你想的那么肥,按照正常的思维你就会问我,既然你没这么肥为什么要叫肥朝.这再次说明了,对方的提问,我们是可预判的.
同理可得,你回答了会缓存本地文件,并且连目录都一清二楚,那他如果照着这个问题深入问下去,他可能会问什么呢?可能会问,既然是缓存,那么自然会存在和实时数据不同步,那么他是什么时候去更新这个缓存?鉴于你前面回答得这么透彻,可能还会加上一句,他这个更新的过程是怎么样的?能画图给我讲一下吗?
当然看到这里你可能会反驳,万一他不按套路出牌,或者我回答了这个问题他又继续深入问下去,那可咋整?其实坦白说,虽然我源码解析以面试题为切入,但是我在dubbo源码解析-zookeeper创建节点中也提到了,看源码并不是以面试为最终目的.因此,简书上关注肥朝,每周一篇dubbo源码解析,互相交流进步,提升自己的层次,而不是在低层次努力,这才是应对"不按套路出牌"和"深入问下去"的不二法宝.
插播面试题
在dubbo中,什么时候更新本地的zookeeper信息缓存文件?订阅zookeeper信息的整体过程是怎么样的?
前戏铺垫
用中文来剧透接下来源码的一些羞嗒嗒的剧情
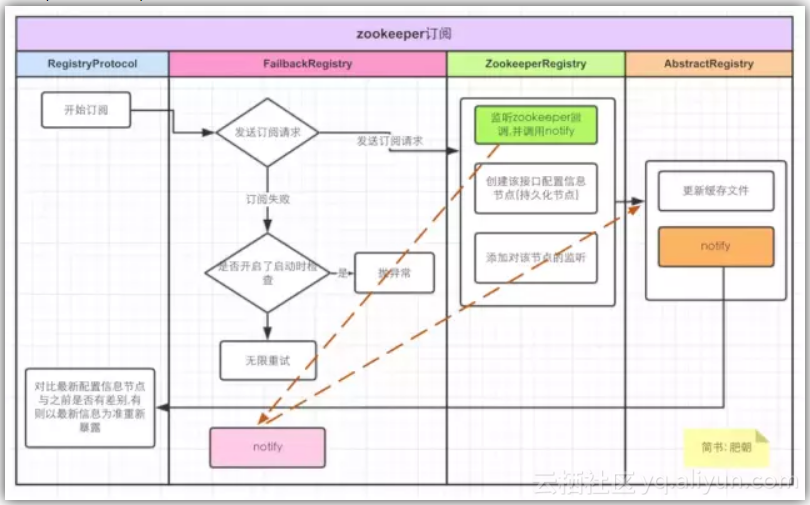
![fd177ac34917e6bf5c3a6863ec2d3e3479850650]()
只需将这幅图记在心中,用小学六年苦练的看图写作文功力即可概括出面试题答案.
直入主题
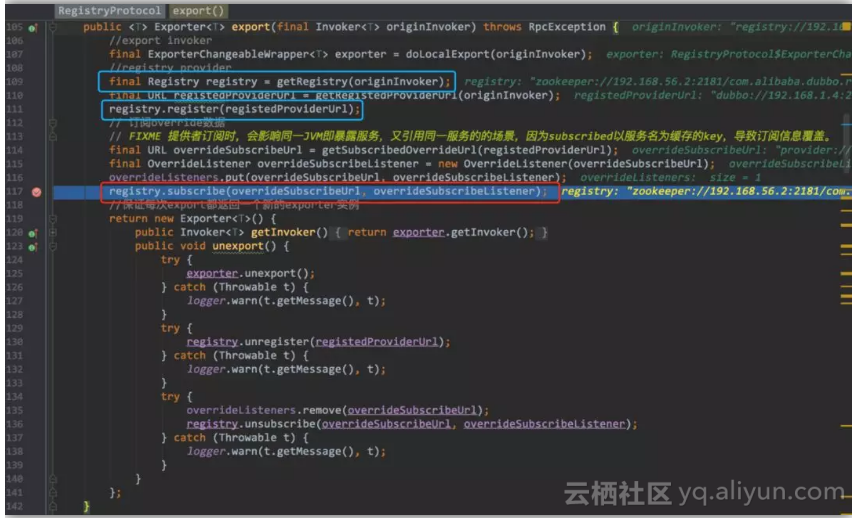
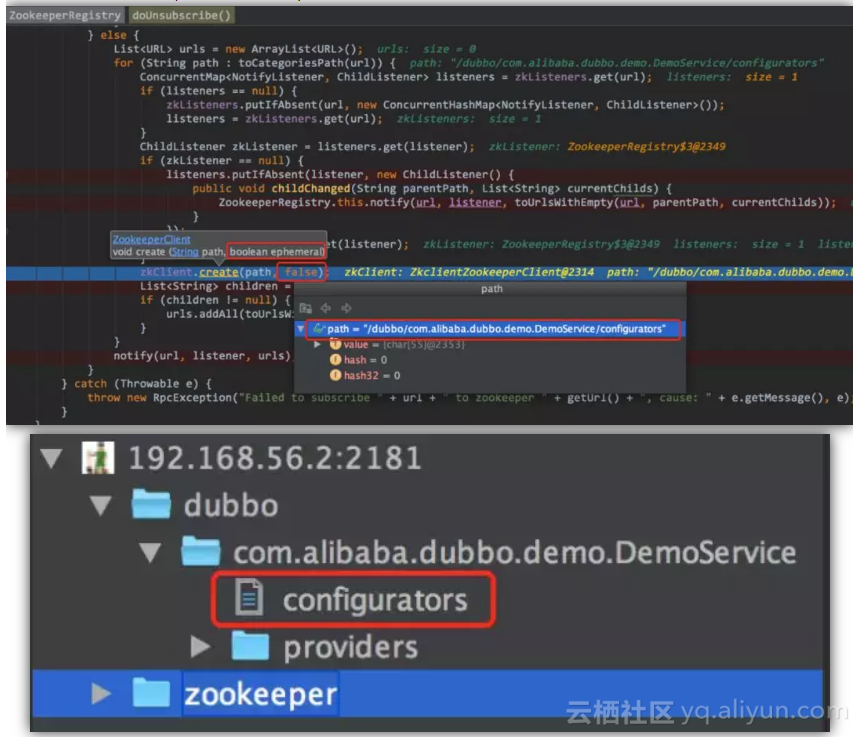
这个方法是我们的老朋友了,我们在前面的zookeeper连接和zookeeper创建节点的时候都已经见过(图中蓝色标注的),这次我们还是讲一行代码(红色标注的)
![837b23434c00a0a15a09116ade0e7f27191fb380]()
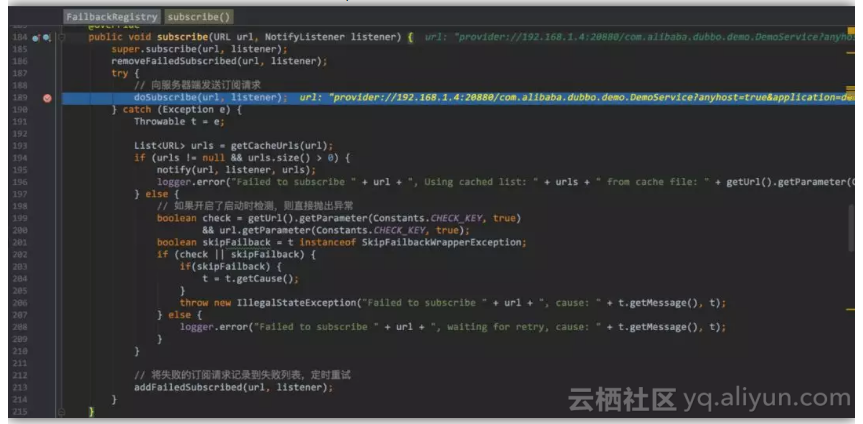
这里就开始发起订阅请求和订阅失败重试,可以对照前期铺垫中的图
![893bdd7ee5cd2f9144cae709224c04ba92d7bd55]()
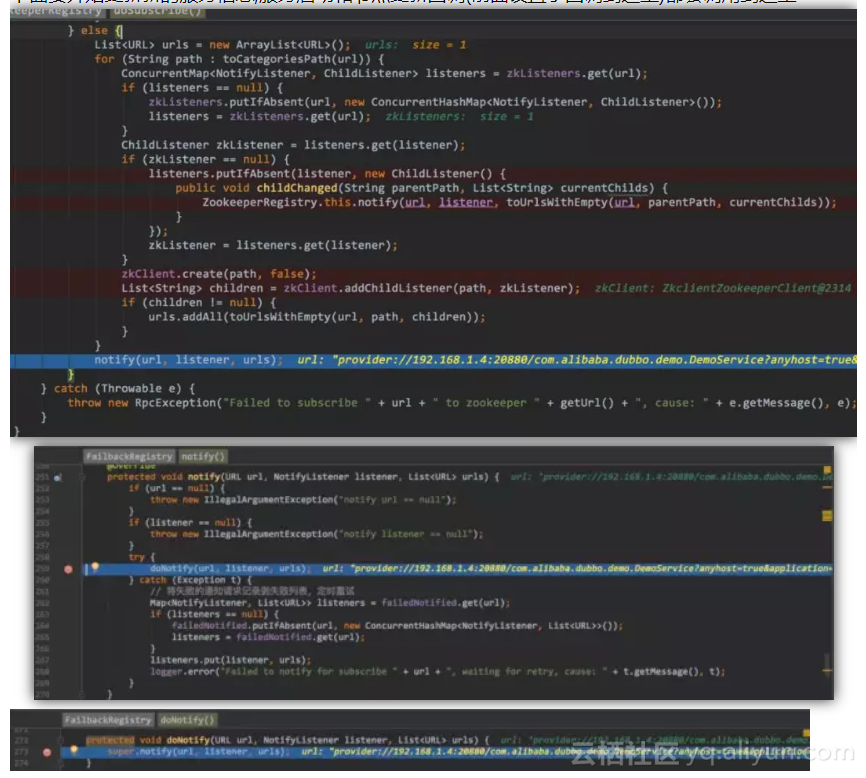
这里设置了监听回调的地址,即回调给FailbackRegistry中的notify
![96fbc82ca157737c320817e12e5adcf484f7d599]()
从这里我们可以看到,创建的是持久节点
![a9091c299c0c8a736bbd4818b327380bc0bdb36d]()
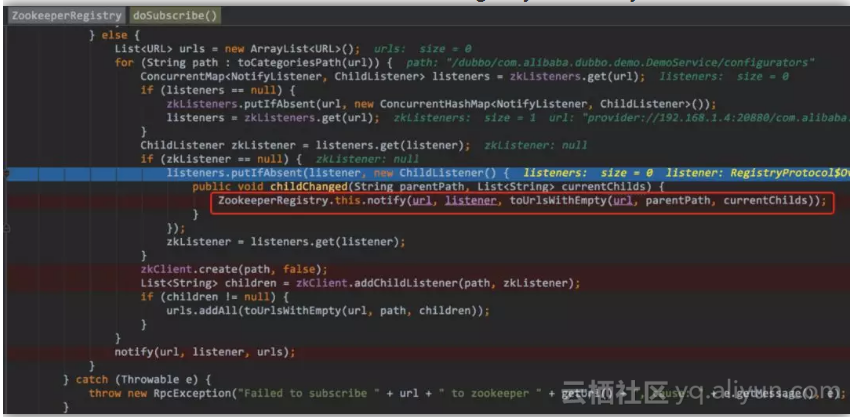
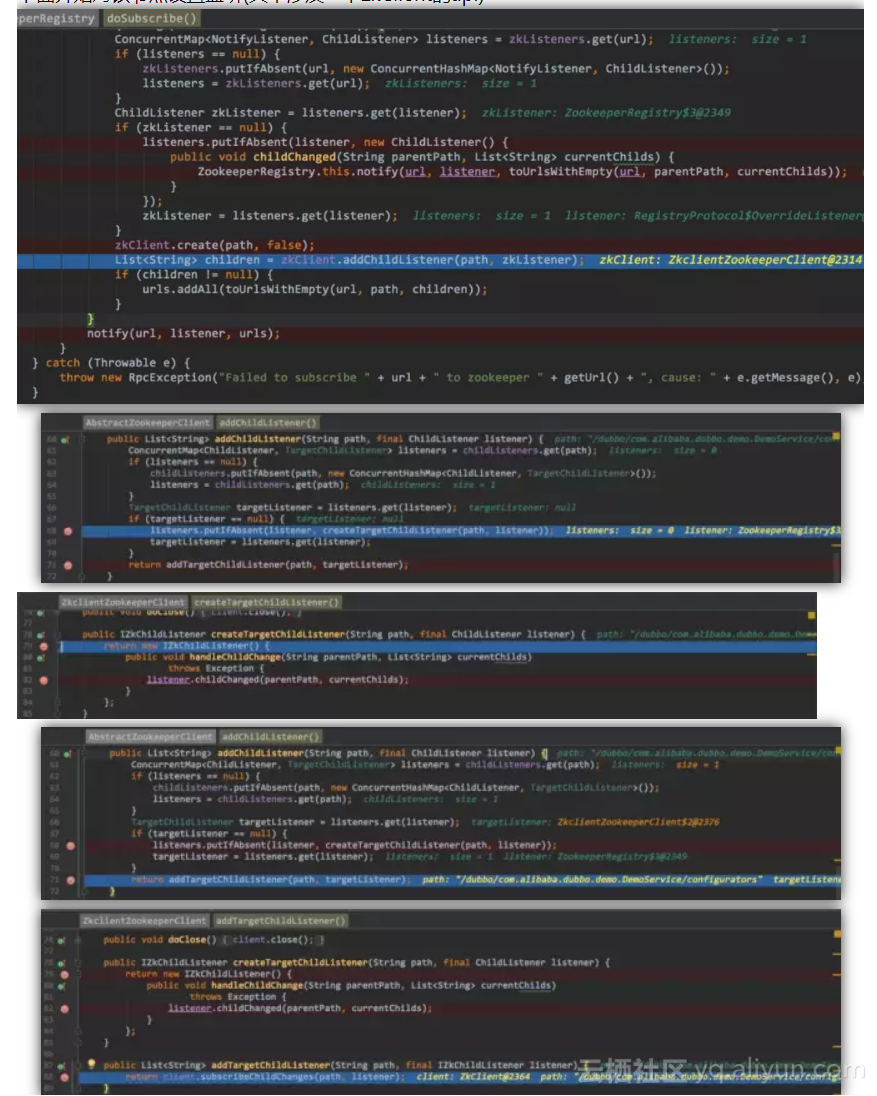
下面开始对该节点设置监听(其中涉及一下zkClient的api)
![23b920e8a4d8b62c266903df431e5f39402ca2ba]()
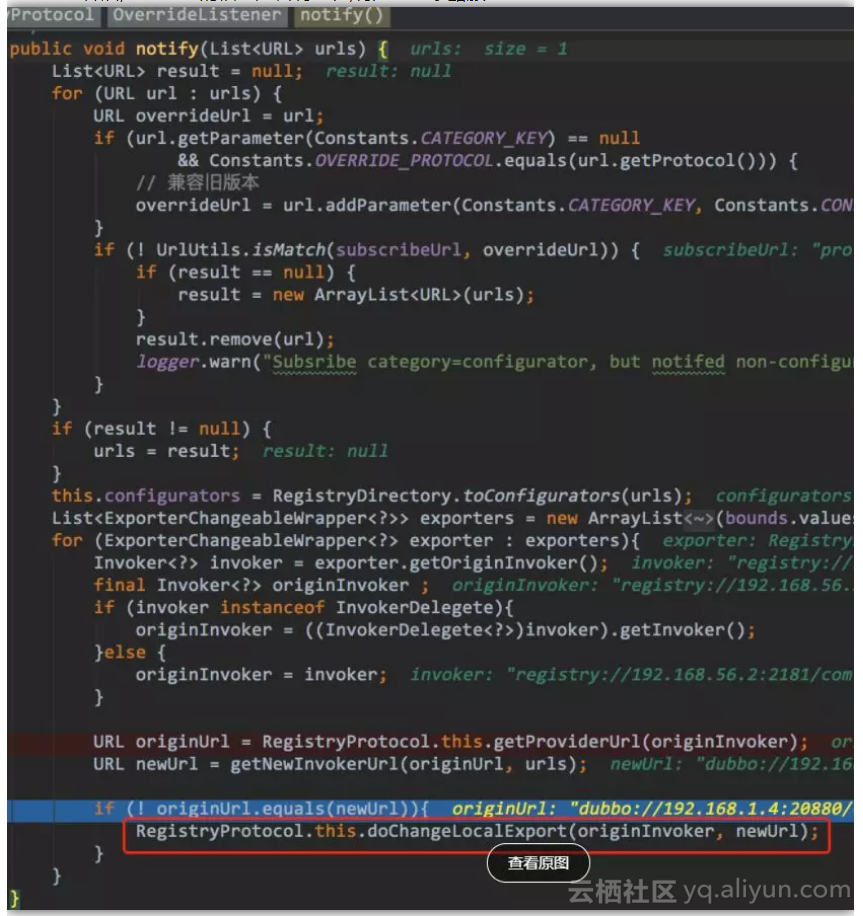
下面要开始更新新的服务信息,服务启动和节点更新回调(前面设置了回调到这里)都会调用到这里
![7473467d0d6935a735866fd67934471ef665374a]()
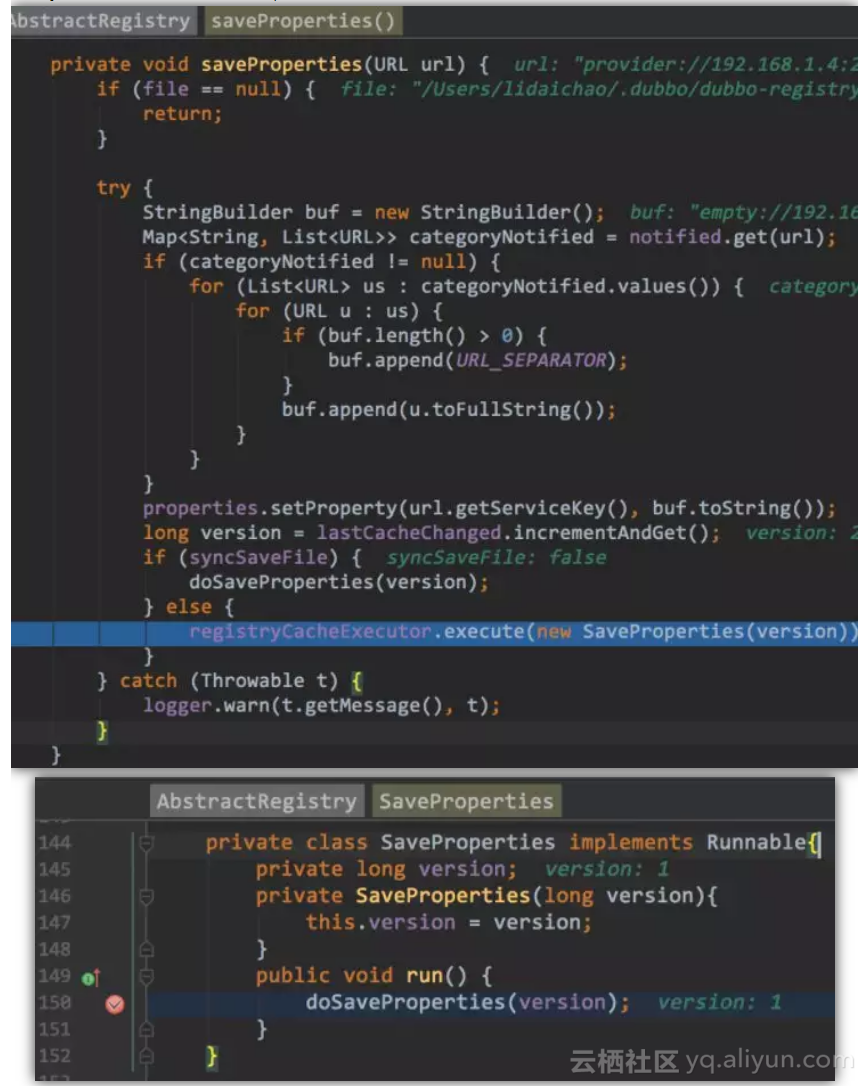
那么下面就要敲黑板划重点了,由前期铺垫我们就知道这里要开始更新本地缓存文件的信息
![73c61b59f1760892b6e811b5aefa1210cca47c97]()
这里采用了线程池来更新,dubbo里面到处都是并发编程,所以面试喜欢问多线程这个真的不是在装逼,线程的意识还是很重要的,同时如果关注肥朝每周一篇dubbo源码解析(真不是套路),面试问到项目哪里用到了多线程例子再也不用担心了,把dubbo里面的例子套一下妥妥的.
![11269b2ab0717ae15f8c73a6601e26a7c9e650d7]()
dubbo在操作文件的时候还会对文件进行加锁,看源码要特别留心这些异常信息,方便出问题时快速定位(其实也是在粗暴式点题怎么看源码)
![86952e489cf1bf78719e21d8f8aa82c1f46f7904]()
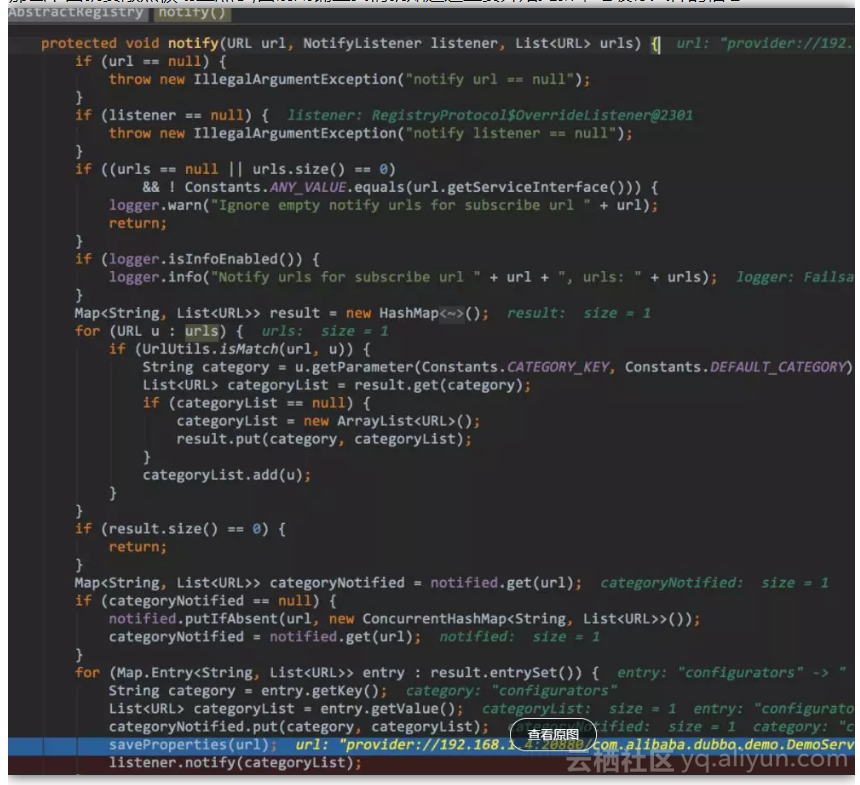
更新完文件后,对比新旧的信息是否有变化,有则重新暴露服务
![c3c0e44d476cce5310c4b9d7dcde3a6e93075d90]()
写在最后
欢乐的时间总是短暂的,又到了说再见的时间,因为最近都是996,写到这里的时候已经是周日的凌晨两点半.期待下周与你相遇.鉴于本人才疏学浅,不对的地方还望斧正。
原文发布时间为:2018-10-24
本文作者:肥朝
本文来自云栖社区合作伙伴“java进阶架构师”,了解相关信息可以关注“java进阶架构师”。