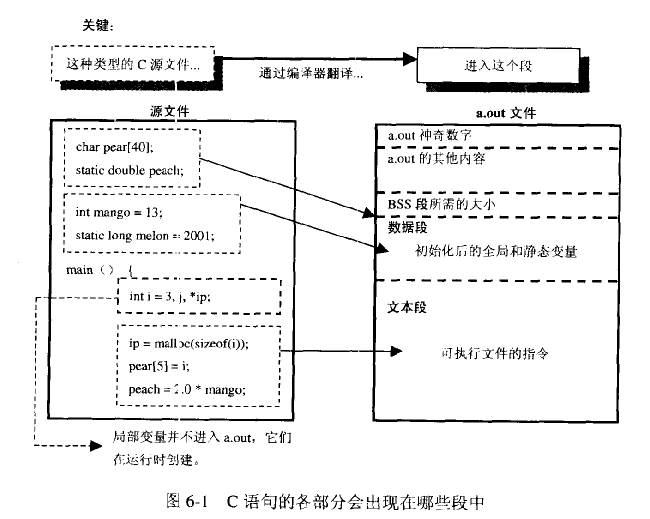
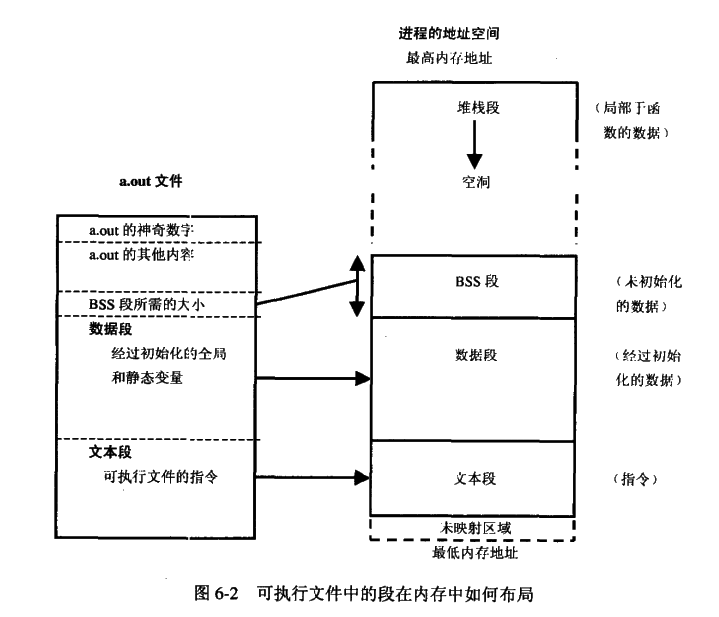
一个程序本质上都是由 BSS 段、data段、text段三个组成的。这样的概念在当前的计算机程序设计中是很重要的一个基本概念,而且在嵌入式系统的设计中也非常重要,牵涉到嵌入式系统运行时的内存大小分配,存储单元占用空间大小的问题。
- BSS段:在采用段式内存管理的架构中,BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
- 数据段:在采用段式内存管理的架构中,数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
- 代码段:在采用段式内存管理的架构中,代码段(text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域属于只读。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
程序编译后生成的目标文件至少含有这三个段,这三个段的大致结构图如下所示:
其中.text即为代码段,为只读。.bss段包含程序中未初始化的全局变量和static变量。data段包含三个部分:heap(堆)、stack(栈)和静态数据区。
- 堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
- 栈 (stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变 量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以 栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
当程序在执行时动态分配空间(C中的malloc函数),所分配的空间就属于heap。其概念与数据结构中“堆”的概念不同。
stack段存放函数内部的变量、参数和返回地址,其在函数被调用时自动分配,访问方式就是标准栈中的LIFO方式。(因为函数的局部变量存放在此,因此其访问方式应该是栈指针加偏移的方式,否则若通过push、pop操作来访问相当麻烦)
data段中的静态数据区存放的是程序中已初始化的全局变量、静态变量和常量。
在采用段式内存管理的架构中(比如intel的80x86系统),BSS 段(Block Started by Symbol segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时 BSS 段部分将会清零。BSS 段属于静态内存分配,即程序一开始就将其清零了。
比如,在C语言之类的程序编译完成之后,已初始化的全局变量保存在.data 段中,未初始化的全局变量保存在.bss 段中。
text和data段都在可执行文件中(在嵌入式系统里一般是固化在镜像文件中),由系统从可执行文件中加载;而BSS段不在可执行文件中,由系统初始化。
图引自《C专家编程》
BSS段只保存没有值的变量,所以事实上它并不需要保存这些变量的映像。运行时所需要的BSS段大小记录在目标文件中,但BSS段并不占据目标文件的任何空间。
-
- int a = 0;
- char *p1;
-
- main()
- {
- static int c =0;
- int b;
- char s[] = "abc";
- char *p2;
- char *p3 = "123456";
- p1 = (char *)malloc(10);
- p2 = (char *)malloc(20);
- }
![]()
(图出自:http://www.tenouk.com/Bufferoverflowc/Bufferoverflow1c.html)
![]()
(图出自:APUE-2e, http://infohost.nmt.edu/~eweiss/222_book/222_book.html)
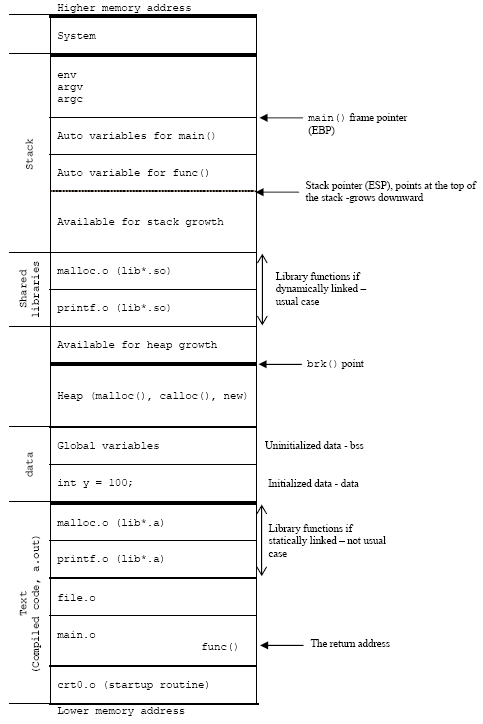
The computer program memory is organized into the following:
Code segment(text segment)
Data Segment
-- Data (rodata + rwdata)
-- BSS
-- Heap
Stack Segment
Data
The data area contains global and staticvariables used by the program that are initialized. This segment can be furtherclassified into initialized read-only (rodata) area and initialized read-writearea (rwdata).
BSS
The BSS segment also known as uninitialized datastarts at the end of the data segment and contains all uninitialized globalvariables and static variables that are initialized to zero by default.
Heap
The heap area begins at the end of the BSSsegment and grows to larger addresses from there. The heap area is managed bymalloc/calloc/realloc/new and free/delete, which may use the brk and sbrk system calls to adjust its size. The heaparea is shared by all shared libraries and dynamically loaded modules in aprocess.
Stack
The stack is a LIFO structure, typically locatedin the higher parts of memory. It usually "grows down" with everyregister, immediate value or stack frame being added to it. A stack frameconsists at minimum of a return address
例子程序
-
-
-
-
-
-
-
-
-
-
-
p1 = (
char *)malloc(10);
-
p2 = (
char *)malloc(20);
-
-
-
堆和栈的区别
管理方式:对于栈来讲,是由编译器自动管理;对于堆来说,释放工作由程序员控制,容易产生 memory leak。
空间大小:一般来讲在 32 位系统下,堆内存可以达到接近 4G 的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在 VC6 下面,默认的栈空间大小大约是 1M。
碎片问题:对于堆来讲,频繁的new/delete 势必会造成内存空间的不连续,从而造成大量碎片,使程序效率降低;对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,永远都不可能有一个内存块从栈中间弹出。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆;栈有 2 种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配,动态分配由 alloca 函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,不需要我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高; 堆则是 C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,然后进行返回。显然,堆的效率比栈要低得多。
无论是堆还是栈,都要防止越界现象的发生。
关于 Global 和 Static 类型的一点讨论
1. static 全局变量与普通的全局变量有什么区别 ?
全局变量(外部变量)的定义之前再冠以 static 就构成了静态的全局变量。
全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。 这两者在存储方式上并无不同。
这两者的区别在于非静态全局变量的作用域是整个源程序, 当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。 而静态全局变量则限制了其作用域, 即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。
由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
static 全局变量只初使化一次,防止在其他文件单元中被引用。
2. static 局部变量和普通局部变量有什么区别 ?
把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。
static 局部变量只被初始化一次,下一次依据上一次结果值。
3. static 函数与普通函数有什么区别?
static 函数与普通函数作用域不同,仅在本文件。只在当前源文件中使用的函数应该说明为内部函数(static),内部函数应该在当前源文件中说明和定义。对于可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件.static 函数在内存中只有一份(.data),普通函数在每个被调用中维持一份拷贝。