0. 参考资料
对 CNN 的研究,目前集中在三个维度:channel, filter,和 residual。
目标是把模型做小、做强、做到移动端,精度差点,没关系,可以加数据,离线多跑几轮。
1. Channel
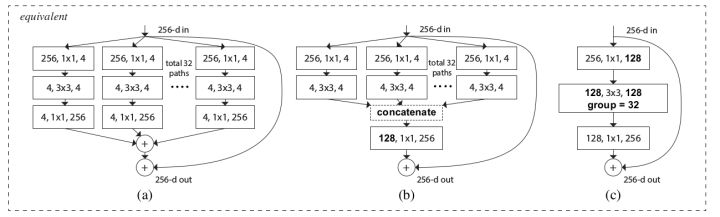
无论 Xception,还是 ResNeXt,还有面向移动端的 ShuffleNet 和 MobileNet。都是基于 Group Convolution思想在 channel 维度进行“网络工程”,搭建新的模型。
Xception 的核心思想是:Depth-wise Separable Convolution
1.1 Group Convolution
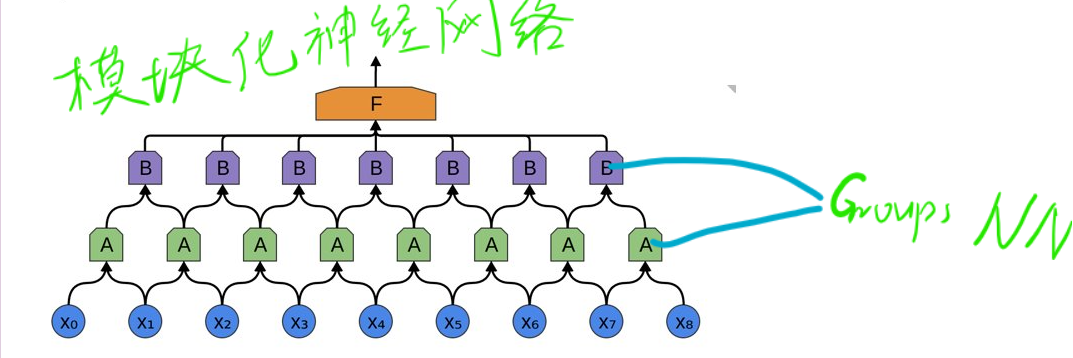
![image_1ceilmthn9nmbd4vpg1kpet6011.png-203.4kB]()
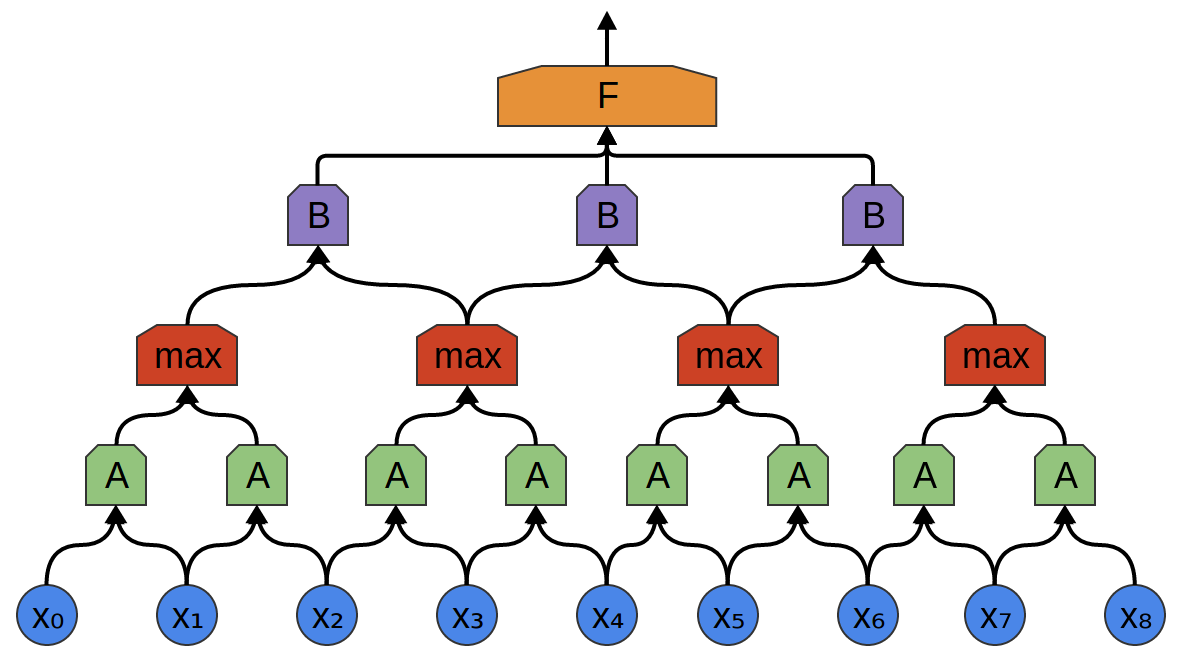
![http://colah.github.io/posts/2014-07-Conv-Nets-Modular/img/Conv-9-Conv2Max2Conv2.png]()
推荐阅读:
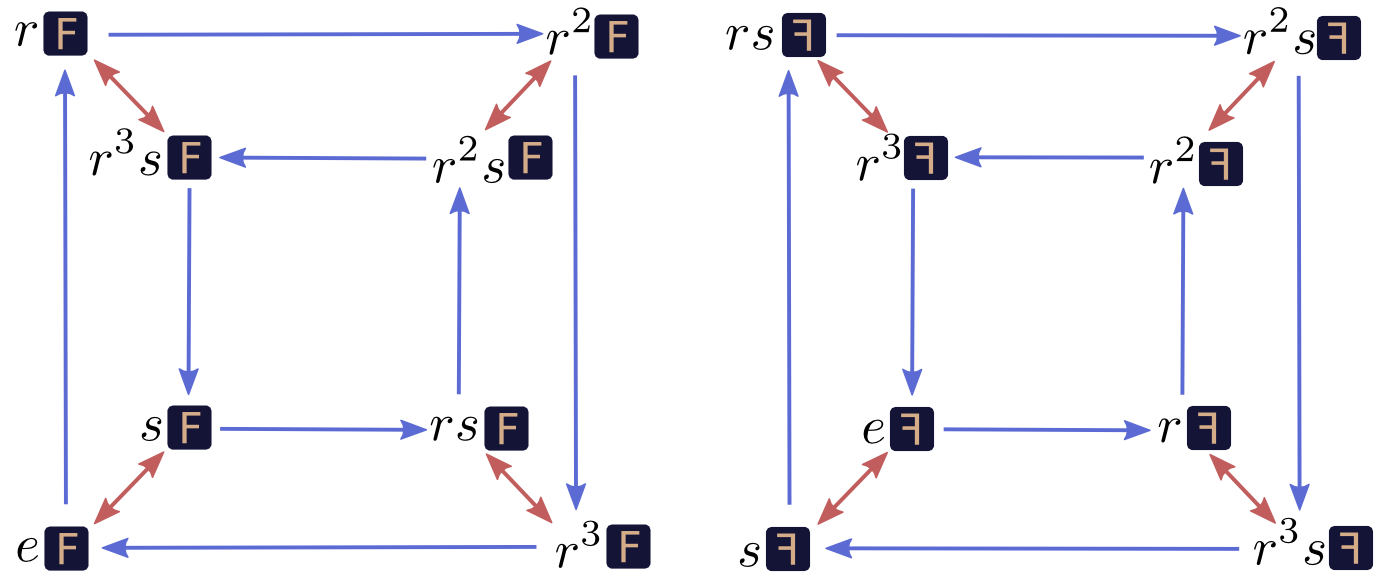
Mathematicians call these abstract patterns groups. There is an entire field of math dedicated to them. Connections between a group and an object like the square are called group actions.
下图是一个变换群:
![http://colah.github.io/posts/2014-12-Groups-Convolution/img/sqF-cayley-alt.png]()
group 是相对于上一层的 channel 来说的。
假如 \(group_{size} = N\), 上一层的 \(\frac{Channel}{FeatureMap \times Filter}\) 的数目为 \(M\)
简单的讲就是把 channel 做 \(N\) 等分,然后每一份(一个 group)分别与上一层的输出的\(\frac{M}{N}\) 个 channel 独立连接,之后将每个 group 的输出叠在一起(concatenate),作为这一层的输出 channel。
Group Convolution 是指将 channels 细分成多个 group,然后再分组进行 Convolution。这种思想始于 2012 年 AlexNet 的双 GPU 架构设计,相当于把 channels 均分到两个 GPU,分组卷积:
![https://pic3.zhimg.com/80/v2-3afd323b9b3ac24ac4f0bdf781ee7c62_hd.jpg]()
如果对每个通道进行卷积,就是 Depthwise Convolution。
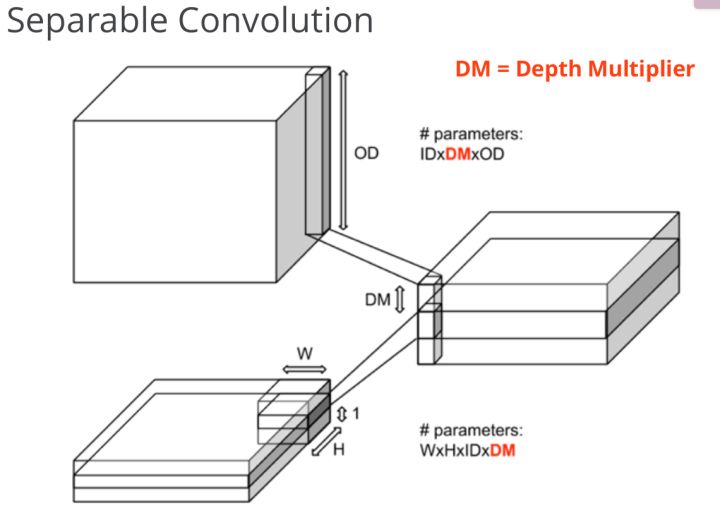
1.2 Separable Convolution
在卷积层中间插入 \(1 \times 1\) 卷积,即 pointwise convolution。举个例子,对经典的卷积操作,如果 OD 是 \(256\),ID 是 \(128\),卷积核大小 \(3\times3\),需要的参数为 \(128 \times 3 \times 3 \times 256=294912\) 个参数,而 Spearable 卷积方法,假如 \(DM=4\),这样中间层的 channel 数为
\(128 \times 4=512\),再经过 \(1 \times 1\) 卷积降维到 \(256\) 个 channel,需要的总参数为:\(128 \times 3 \times 3 \times 4 + 128 \times 4 \times 1 \times 1 \times 256=135680\),参数量相当于普通卷积的 \(46\%\),还增加了通道数(\(128 \times 4=512\))增强了特征表达能力。
所以说,理想的卷积 Block 应该是先用 \(1 \times 1\) 卷积核降 channel,然后再进行 \(3 \times 3\) 卷积提取特征,最后再用 \(1 \times 1\) 卷积核降 channel。
![v2-854177e100d7d48dc5dda40306f5b311_hd1.jpg-29.3kB]()
1.3 Xception
利用上述结构重新设计 Inception model block,就是 Xception;重新设计 Resnet,就是 ResNeXt 架构。以达到在减少参数量的情况下增加模型的层数,既减少了存储空间,还增强了模型的表达能力。
![https://pic4.zhimg.com/80/v2-c6021144955230538e79a60beb3637eb_hd.jpg]()
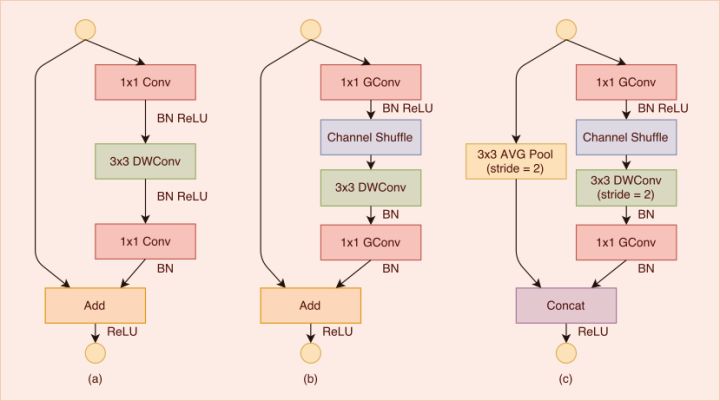
通常来讲,如果对 channel 进行分组卷积,各小组就分头行动,互相没有交流,这样显然没有充分利用 channel 的信息。ShuffleNet 在分组之前,先将 channel 随记打乱,这样对信息的利用更充分,因此可以通过设计降低模型参数量而不影响模型的表达能力。
![v2-85fc52ac1442d14095b1d316f993b220_hd1.jpg-27.1kB]()
2. Filter
2.1 Wavenet
经典 CNN 的 Filter 是在邻域内采样卷积,如 \(3 \times 3\) 卷积核是在 \(8\) 邻域采样。
![v2-f1d70820666dbc728a83374548843479_hd1.jpg-41.5kB]()
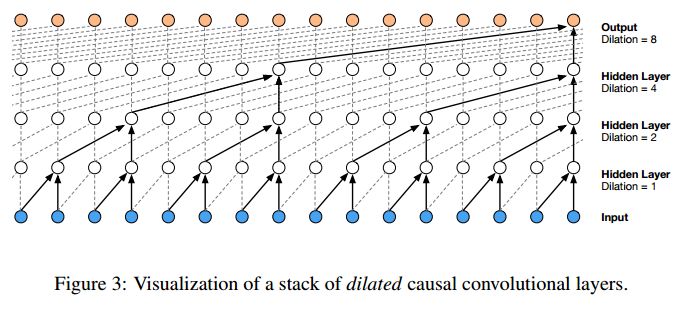
但是,Filter 可以跨点采样进行卷积,从而可以利用更大范围内的信息,即 Dilated CNN,最早应用于图像语义分割,去年谷歌提出的 Wavenet 模型将 CNN 拓展到语音识别和语音合成。
![https://pic1.zhimg.com/80/v2-c4be30d360a55ec3773d741dda5c8a8e_hd.jpg]()
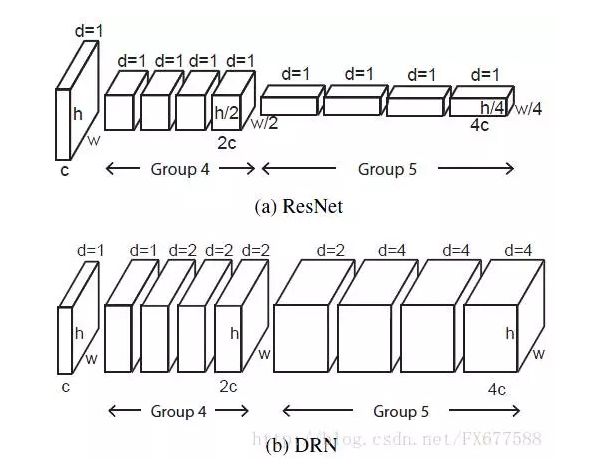
2.2 Dilated Resnet
将 Dilated CNN 的思想应用到 Resnet 架构中,就是 CVPR 2017 的 “Dilated Residual Networks”
![v2-a97cd99361c3e165e804b2e21f35dc71_hd1.jpg-35.5kB]()
3. Connection
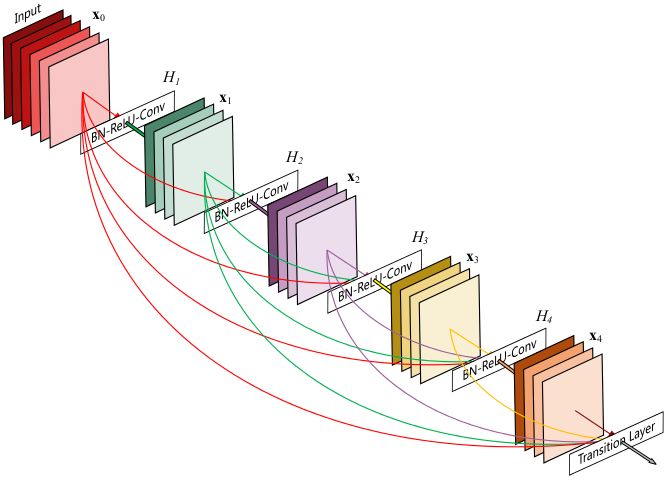
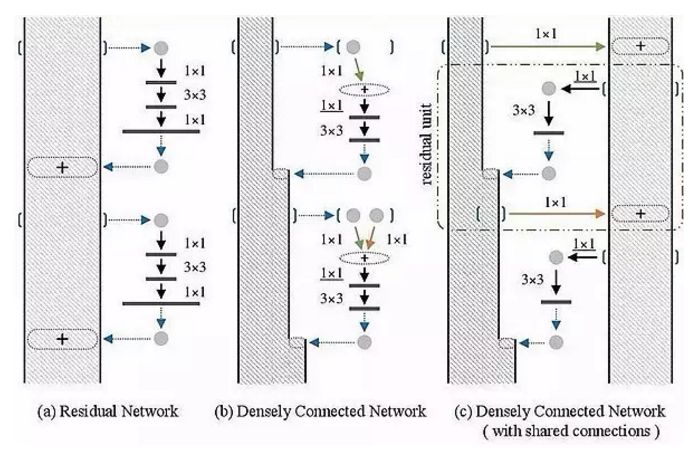
ResNet 的 Connection 方式是将输入和输出相加,形成一个残差 Block。DenseNet 则更进一步,在每个 Block 内,将输入和输出直接拼接,而且在每一层都和之前所有层的输出拼接,这样可以减少中间层的通道数。
![https://pic1.zhimg.com/80/v2-f03cee2b0ff0c4f90c901f88cc93d58f_hd.jpg]()
而最新的 Dual Path Networks 模型,则是融合了 ResNet 和 DenseNet 的优点:特征重利用和特征重提取。采用了双通道架构:
![https://pic1.zhimg.com/80/v2-34228eb695edbd5bad49013671b1153d_hd.jpg]()
可以预想,接下来,将会有模型融合以上三点的集大成者?
启发与思考
现在越来越多的 CNN 模型从巨型网络到轻量化网络一步步演变,模型准确率也越来越高。现在工业界追求的重点已经不是准确率的提升(因为都已经很高了),都聚焦于速度与准确率的 trade off,都希望模型又快又准。因此从原来 AlexNet、VGGnet,到体积小一点的 Inception、Resnet 系列,到目前能移植到移动端的 mobilenet、ShuffleNet(体积能降低到 \(0.5\) mb!),我们可以看到这样一些趋势:
卷积核方面:
- 大卷积核用多个小卷积核代替;
- 单一尺寸卷积核用多尺寸卷积核代替;
- 固定形状卷积核趋于使用可变形卷积核;
- 使用 \(1 \times 1\) 卷积核(bottleneck 结构)。
卷积层通道方面:
- 标准卷积用 depthwise 卷积代替;
- 使用分组卷积;
- 分组卷积前使用 channel shuffle;
- 通道加权计算。
卷积层连接方面:
- 使用 skip connection,让模型更深;
- densely connection,使每一层都融合上其它层的特征输出(DenseNet)
启发
类比到通道加权操作,卷积层跨层连接能否也进行加权处理?bottleneck + Group conv + channel shuffle + depthwise 的结合会不会成为以后降低参数量的标准配置?
探寻有趣之事!