在上文已介绍过,connector组件是service容器中的一部分。
它主要是接收,解析HTTP请求,然后调用本service下的相关Servlet
Tomcat从架构上采用的是一个分层结构,因此根据解析过的HTTP请求,定位到相应的Servlet也是一个相对比较复杂的过程
整个Connector实现了从接收
Socket到调用
Servlet的全部过程
先看
Connector的执行逻辑
- 接收socket
- 从socket获取数据包,并解析成
HttpServletRequest对象
- 从
engine容器开始走调用流程,经过各层valve,最后调用Servlet完成业务逻辑
- 返回response,关闭socket
可看出,整个Connector组件是Tomcat运行主干,之前介绍的各个模块都是Tomcat启动时,静态创建好的,通过Connector将这些模块串起
网络吞吐一直是整个服务的瓶颈所在,Connector的运行效率在一定程度上影响了Tomcat的整体性能。相对来说,Tomcat在处理静态页面方面一直有一些瓶颈,因此通常的服务架构都是前端类似Nginx的web服务器,后端挂上Tomcat作为应用服务器(当然还有些其他原因,例如负载均衡等)
Tomcat在Connector的优化上做了一些特殊的处理,这些都是可选的,通过部署,配置方便完成,例如APR(Apache Portable Runtime),BIO,NIO等
目前Connector支持的协议是HTTP和AJP。
- AJP是Apache与其他服务器之间的通信协议。通常在集群环境中,例如前端web服务器和后端应用服务器或servlet容器,使用AJP会比HTTP有更好的性能,这里引述apache官网上的一段话
本篇主要针对HTTP协议的Connector进行阐述
先来看一下Connector配置,在server.xml里
熟悉的80端口不必说了。protocol这里是指这个Connector支持的协议。
具体到HTTP协议,这个属性可以配置的值有
- HTTP/1.1
- org.apache.coyote.http11.Http11Protocol –BIO实现
- org.apache.coyote.http11.Http11NioProtocol –NIO实现
- 定制的接口
配置HTTP/1.1和org.apache.coyote.http11.Http11Protocol效果一样,因此Connector的HTTP协议实现默认支持BIO的
无论BIO/NIO都是实现一个org.apache.coyote.ProtocolHandler接口,因此如果需要定制,也必须实现这个接口
来看看默认状态下HTTP connector的架构及其消息流
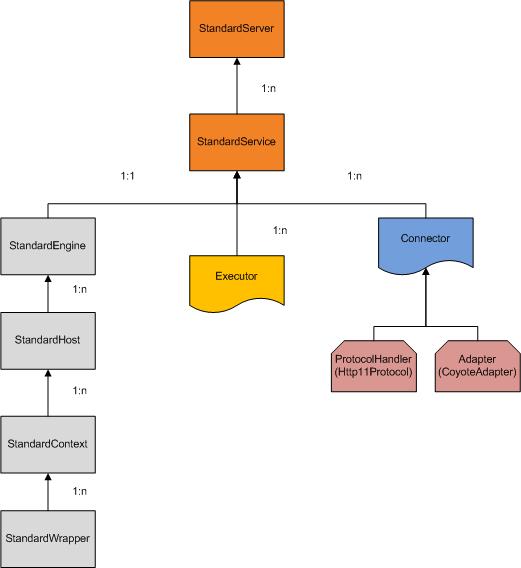
Connector的三大件
- HTTP11Protocol
- Mapper
- CoyoteAdapter
HTTP11Protocol
类全路径org.apache.coyote.http11.Http11Protocol,这是支持HTTP的BIO实现
包含了JIoEndpoint对象及Http11ConnectionHandler对象。
Http11ConnectionHandler对象维护了一个Http11Processor对象池,Http11Processor对象会调用CoyoteAdapter完成http request的解析和分派。
JIoEndpoint维护了两个线程池,Acceptor及Worker。Acceptor是接收socket,然后从Worker线程池中找出空闲的线程处理socket,如果worker线程池没有空闲线程,则Acceptor将阻塞。Worker是典型的线程池实现。Worker线程拿到socket后,就从Http11Processor对象池中获取Http11Processor对象,进一步处理。除了这个比较基础的Worker线程池,也可以通过基于java concurrent 系列的java.util.concurrent.ThreadPoolExecutor线程池实现,不过需要在server.xml中配置相应的节点,即在connector同级别配置<Executor>,配置完后,使用ThreadPoolExecutor与Worker在实现上没有什么大的区别,就不赘述了。
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="150" minSpareThreads="4"/>
图中的箭头代表了消息流。
Mapper
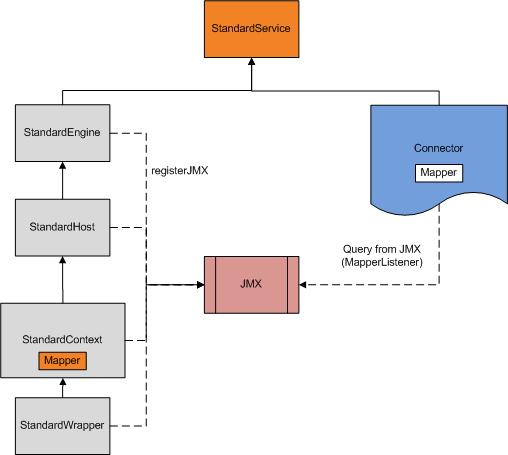
类全路径org.apache.tomcat.util.http.mapper.Mapper,此对象维护了一个从Host到Wrapper的各级容器的快照
它主要是为了,当HTTP request被解析后,能够将HTTP request绑定到相应的servlet进行业务处理。前面的文章中已经说明,在加载各层容器时,会将它们注册到JMX中。
所以当
Connector启动,会从JMX中查询出各层容器,然后再创建这个Mapper对象中的快照
CoyoteAdapter
全路径org.apache.catalina.connector.CoyoteAdapter,此对象负责将HTTP request解析成HttpServletRequest对象,之后绑定相应的容器,然后从engine开始逐层调用valve直至该servlet。
在Session管理中,已经说明,根据request中的jsessionid绑定服务器端的相应session。
这个jsessionid按照优先级或是从request url中获取,或是从cookie中获取,然后再session池中找到相应匹配的session对象,然后将其封装到HttpServletRequest对象。所有这些都是在CoyoteAdapter中完成的。
看一下将request解析为HttpServletRequest对象后,开始调用servlet的代码;
connector.getContainer().getPipeline().getFirst().invoke(request, response);
connector的容器就是StandardEngine,代码的可读性很强,获取StandardEngine的pipeline,然后从第一个valve开始调用逻辑,相应的过程请参照tomcat架构分析(valve机制)。