【51CTO.com快译】随着全球数据总量的爆炸式增长,我们必须改变对相关信息的保护方式。
过去五年以来,应用程序的规范已经迎来彻底转变。如今,我们需要在应用当中实现更多敏捷性、可扩展性与可用性要求。在如今这个时代,应用的主要趋势开始转向社交平台、移动设备与软件即服务(简称SaaS)。另外,其需要有能力从各种来源处获取批量数据,同时实时处理以提供背景信息或者业务洞穴能力,借此建立竞争优势。为了满足这些新型需求,企业无法再单纯依赖于传统关系型数据库。有鉴于此,一系列新型数据库系统应运而生,其本质上具备分布式与横向扩展特性,能够被部署在商用硬件之上,同时提供可协调的统一性与性能调整机制。更重要的是,为了满足敏捷性需求,云端数据库即服务模式亦得到广泛采用。
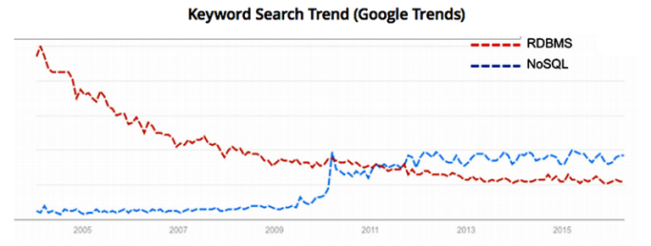
为了帮助大家理解这场分布式数据库变革的规模之大,我们整理出了以下图表,可以看到NoSQL类搜索数量正呈现出急剧上升之势。
![]()
这意味着数据保护要求已经彻底改变,且受到数据至上时代的大力推动(包括Web规模应用以及分布式数据库)。企业需要收集大量数据并从中获取有价值信息,用以带来更为可观的商业价值以及更为迅捷的决策制定能力。大部分分布式与云数据库已经提供复制功能,用于满足数据保护及可用性要求。然而,我们仍然需要解决可扩展时间点备份与恢复这一重大难题。如果没有时间点备份的支持,企业将时刻面临着因人为错误、逻辑损坏或者其它运营故障造成的数据丢失风险。
传统备份解决方案主要面向关系型数据库设计,即面向共享式存储并采用ACID事务模型。遗憾的是,这类设计无法满足分布式场景下的时间点备份要求(包括本地存储、最终一致性以及基础设施的弹性特质)。
考虑到数据库架构已经发生本质性转变,数据保护举措亦需要进行重新定义与重新设计。以下为数据保护在大数据时代下面临的新挑战:
·获取最终一致性数据库的一套持久性时间点备份副本,我们将其称为当前全新分布式时代下数据保护的“版本控制”新规范:备份到快照到复制到复制数据管理再到版本控制。
·***程度降低故障恢复时间(即低RTO)。
·随应用程序的实际需求进行规模扩展。
·允许轻松更新测试/开发环境以实现持续开发。
·在发生故障时提供运营弹性。
·提供立足于公有云或者内部数据中心的部署灵活性。
大多数企业正在积极投资企业级时间点备份与恢复产品,从而确保自身能够安心在分布式数据库之上部署并扩展下一代应用程序。在未来五年内,各企业将重新定义数据保护技术,从而切实满足下一代应用的实际需要。
原文题目:The Evolution of Backup and Recovery: The Big Data Era,作者:Jeannie Liou
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
【责任编辑:
云中子 TEL:(010)68476606】
点赞 0