
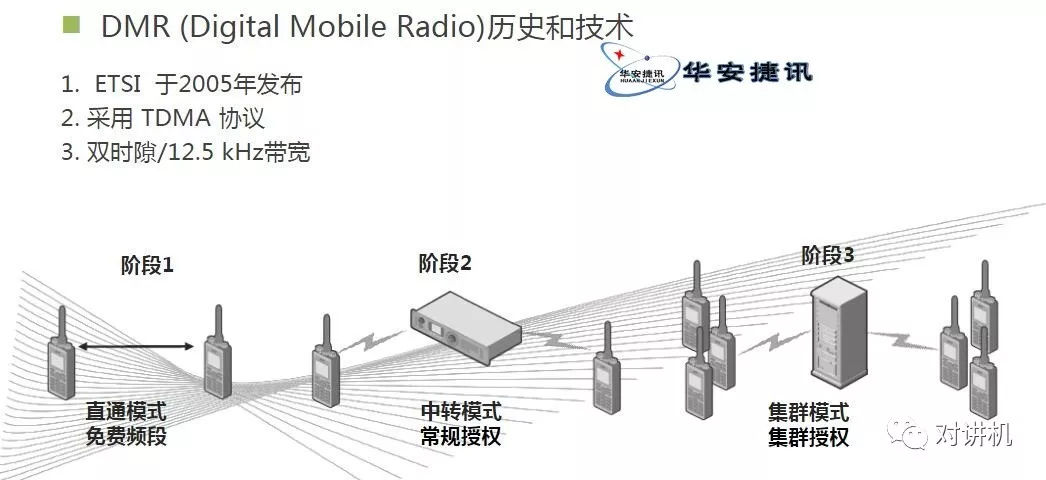

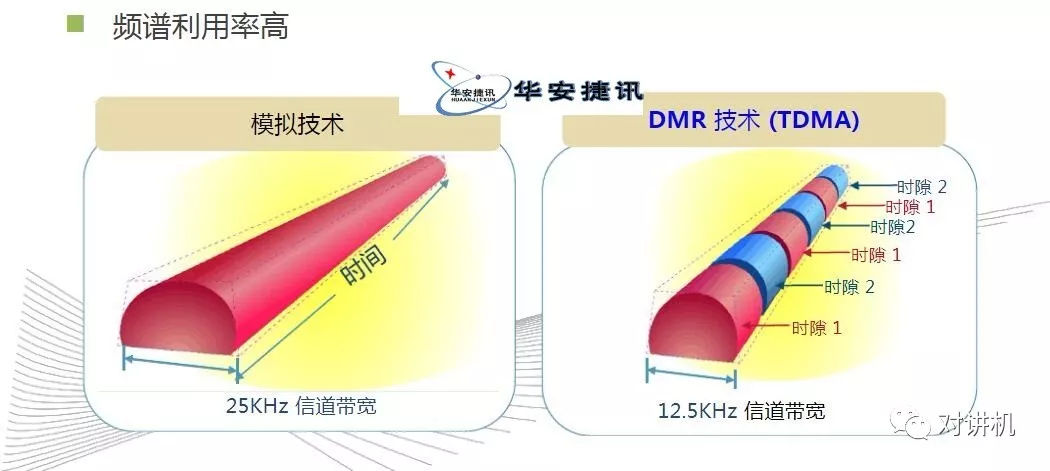
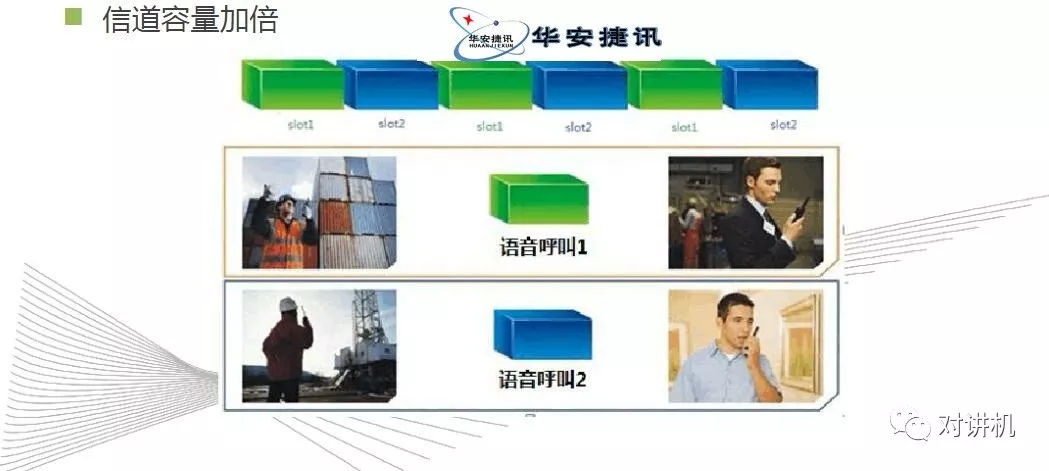
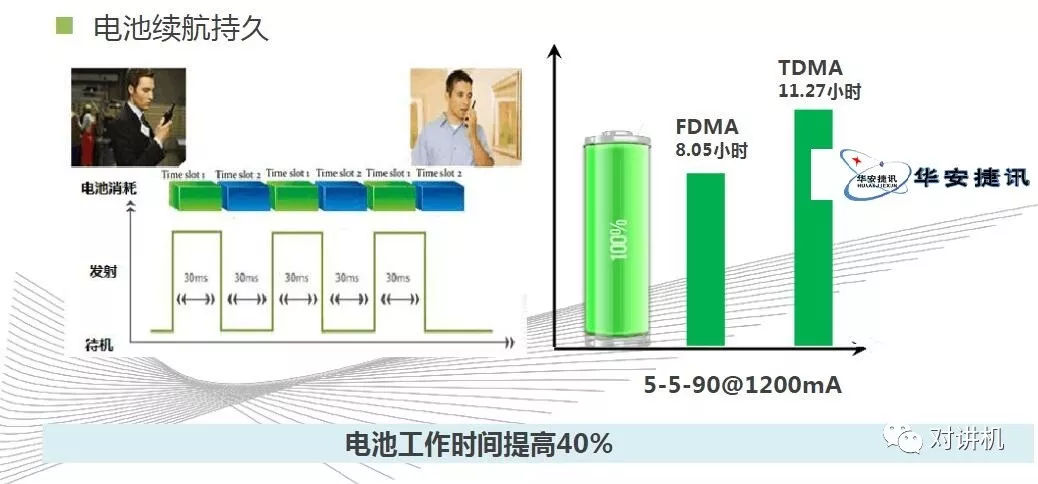



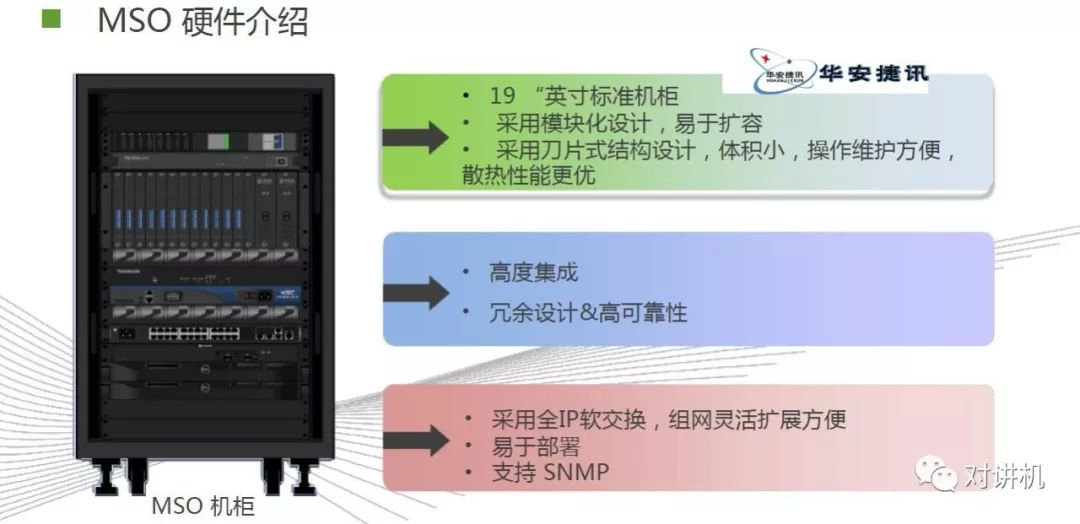

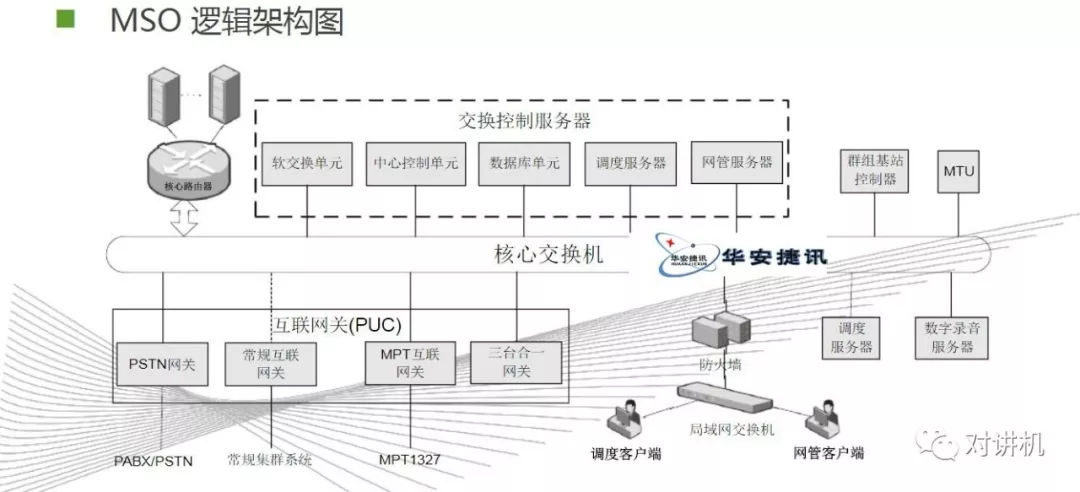

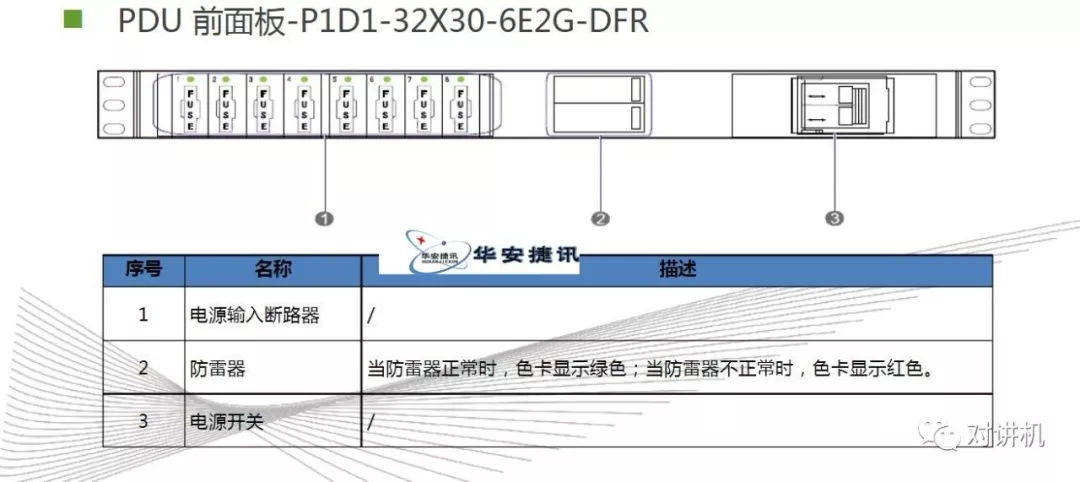
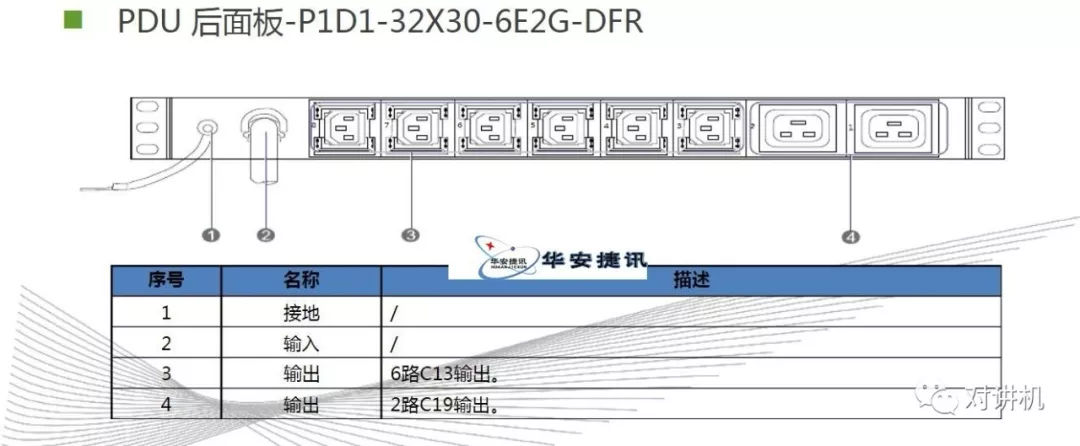
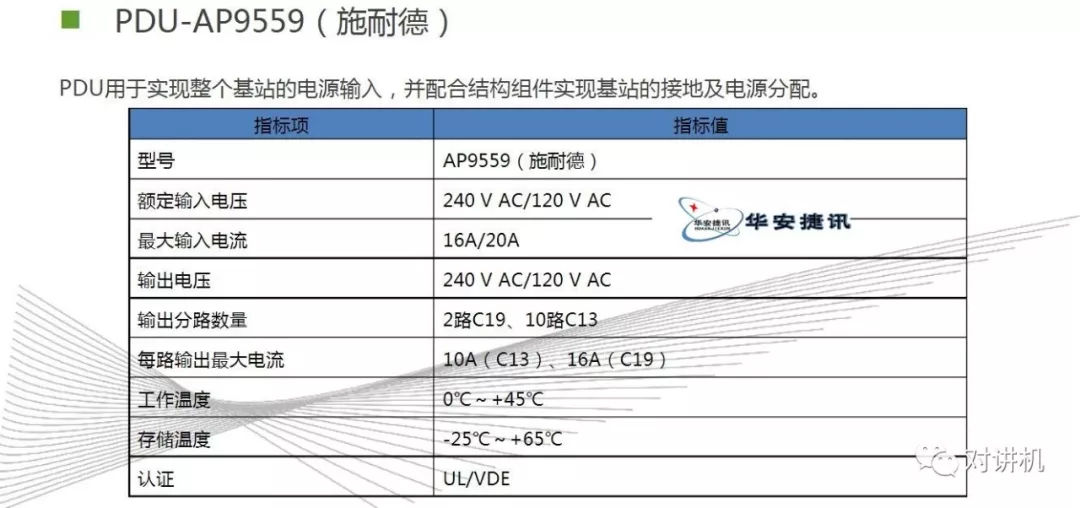
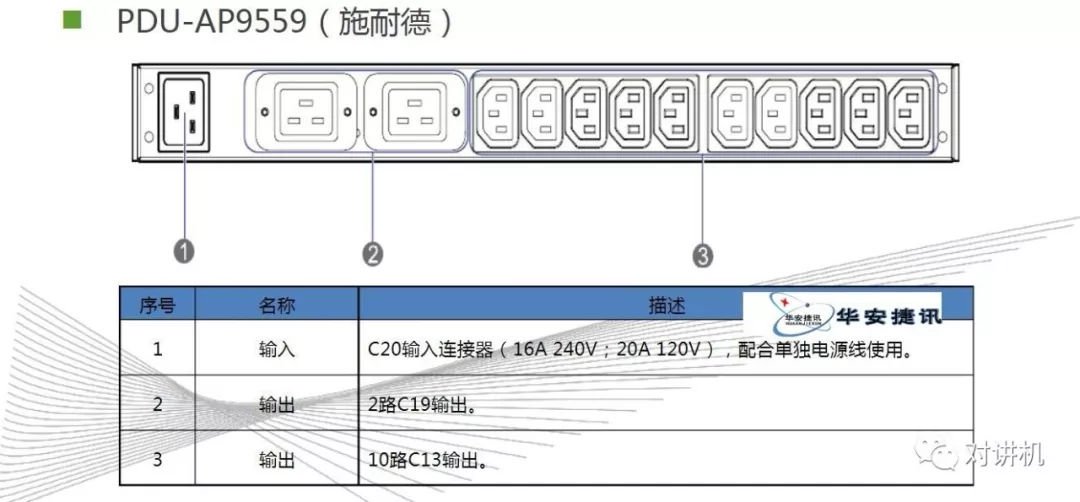

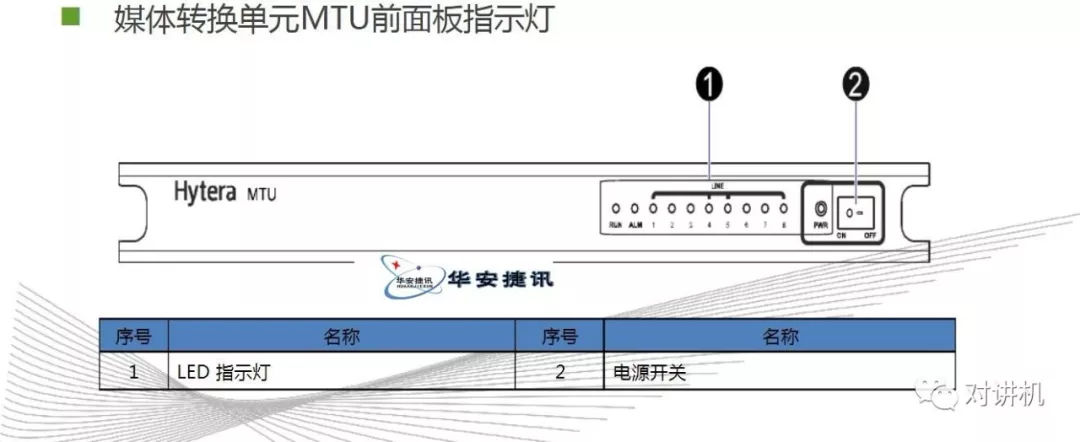
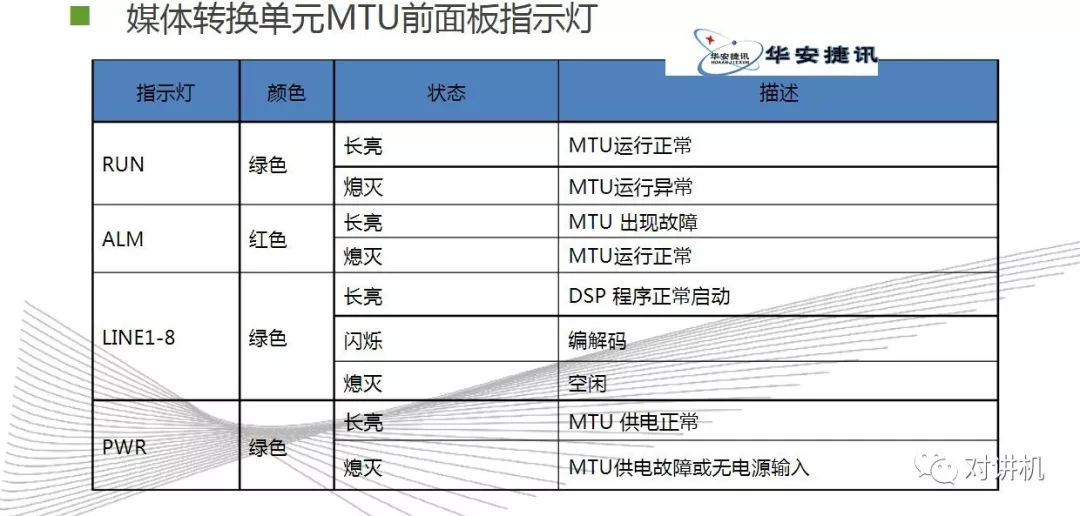



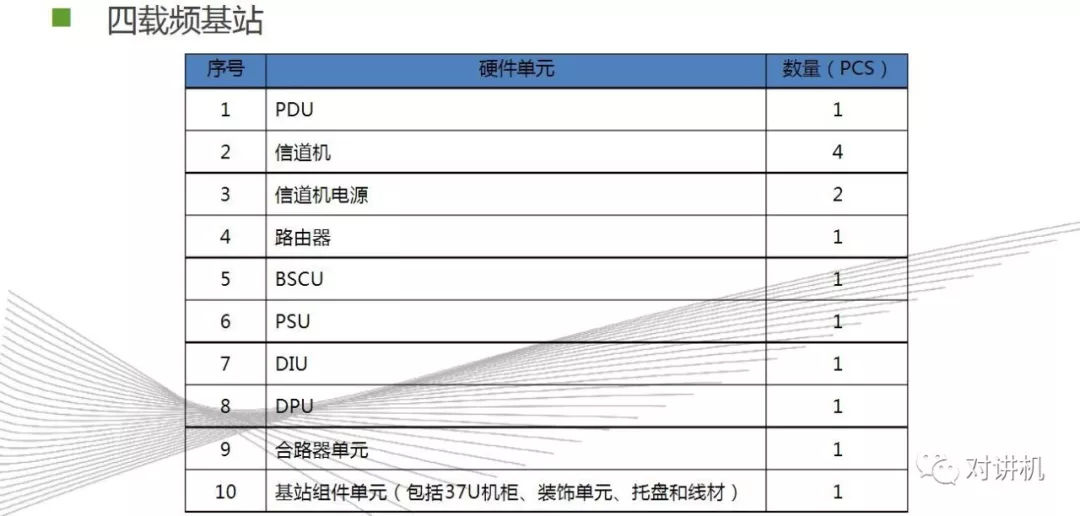

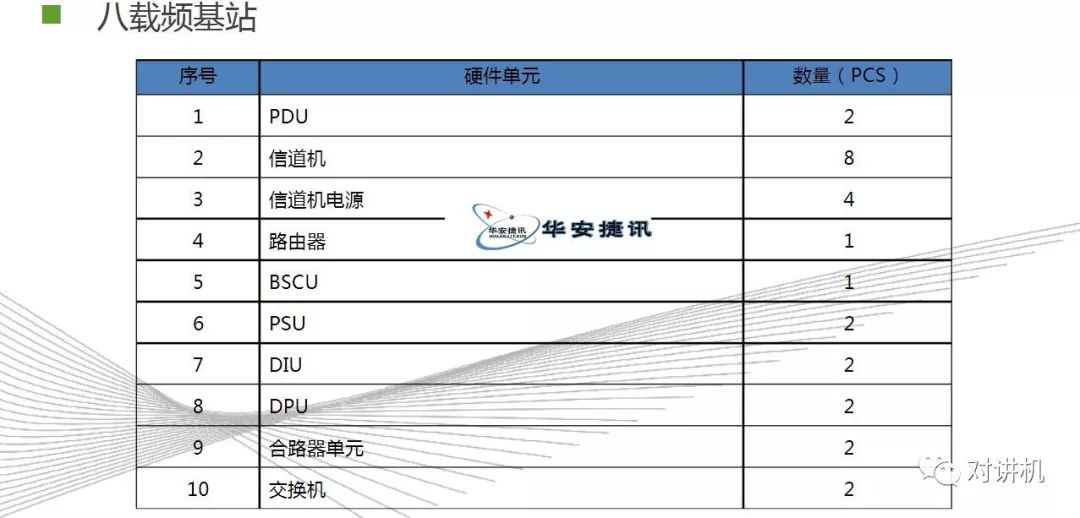
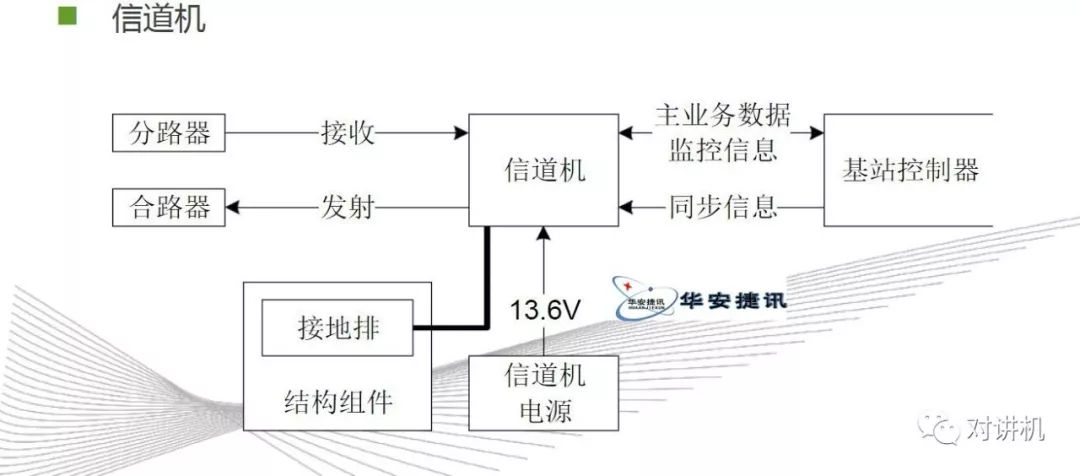
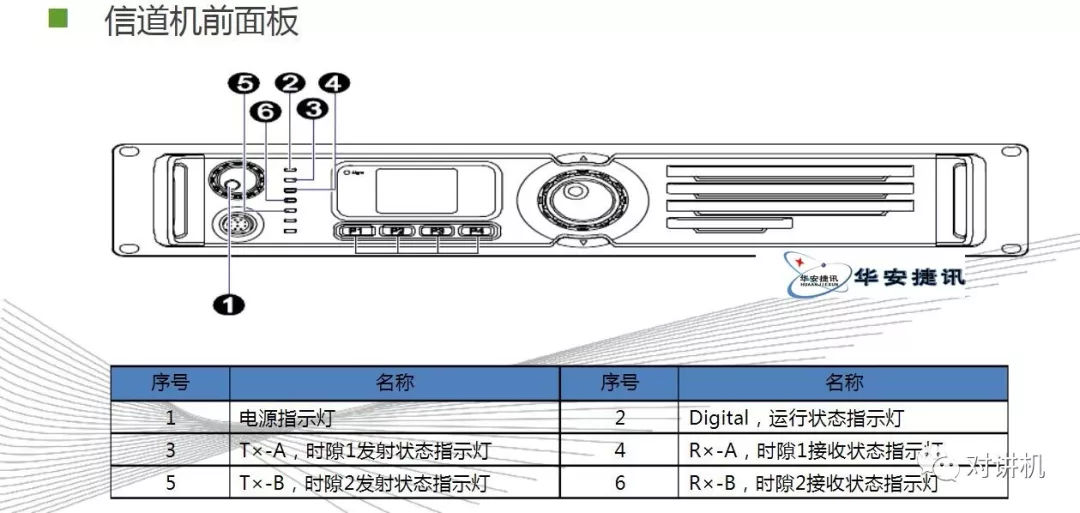
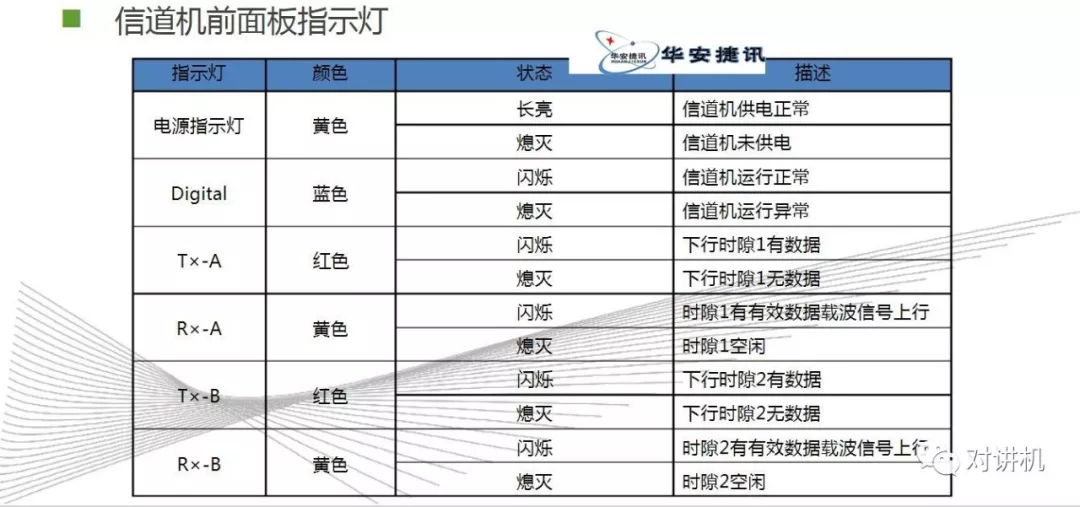
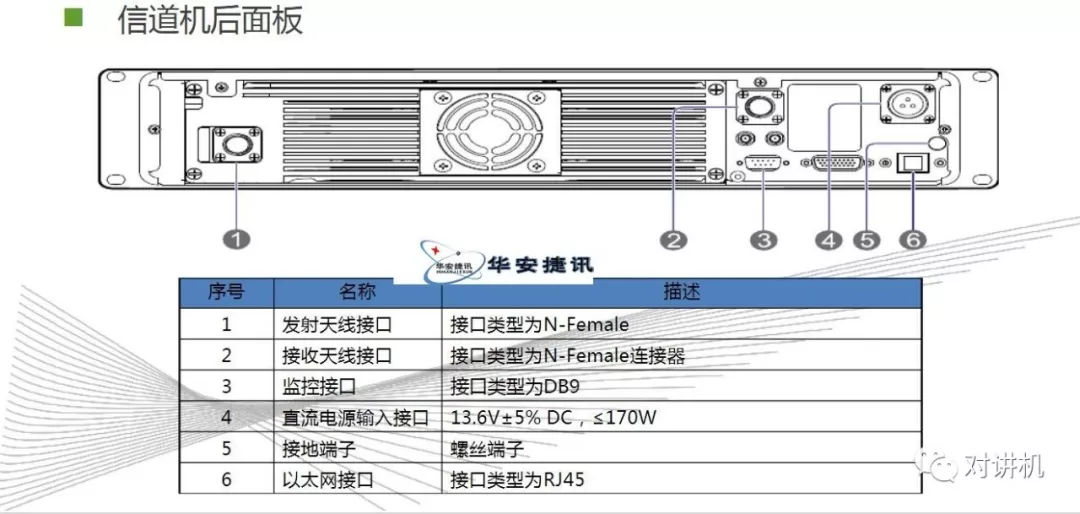
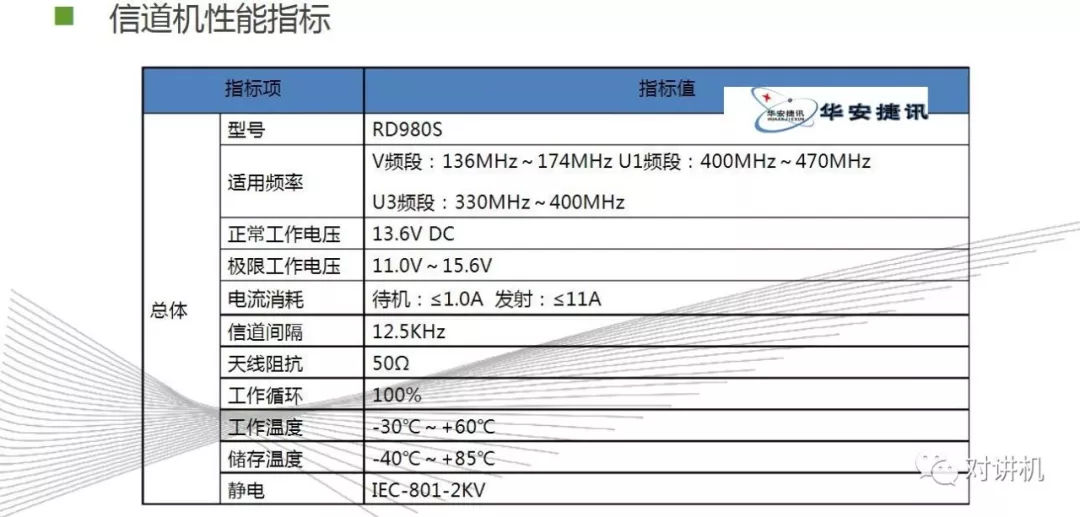
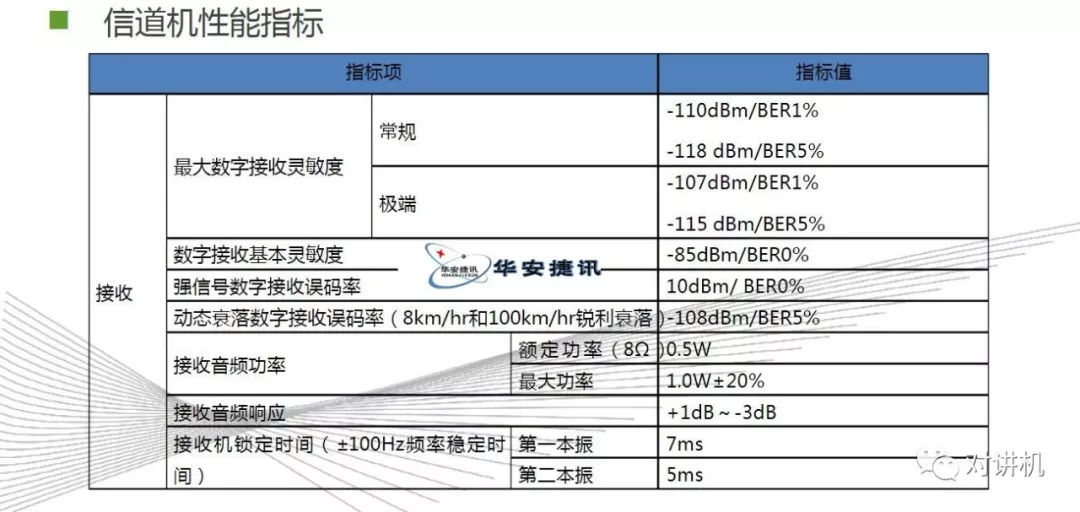
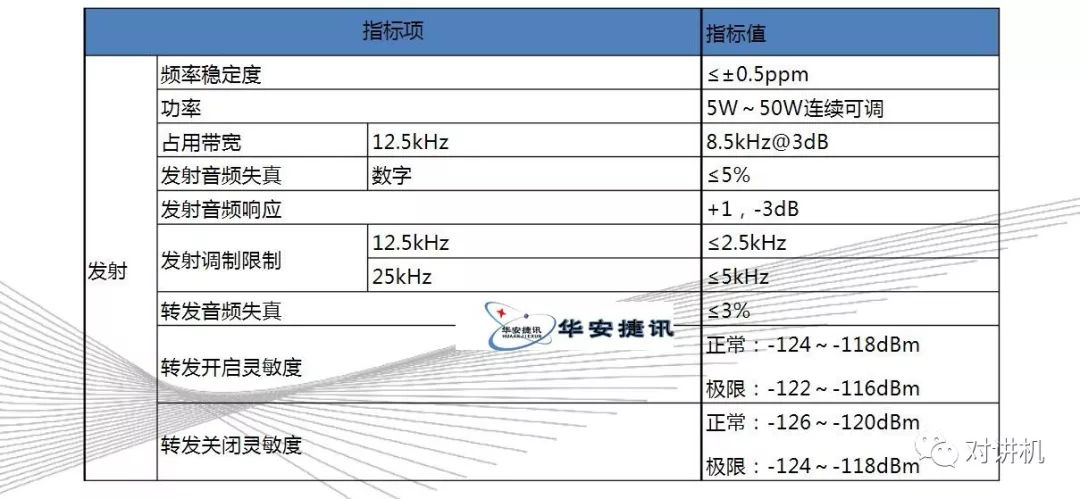
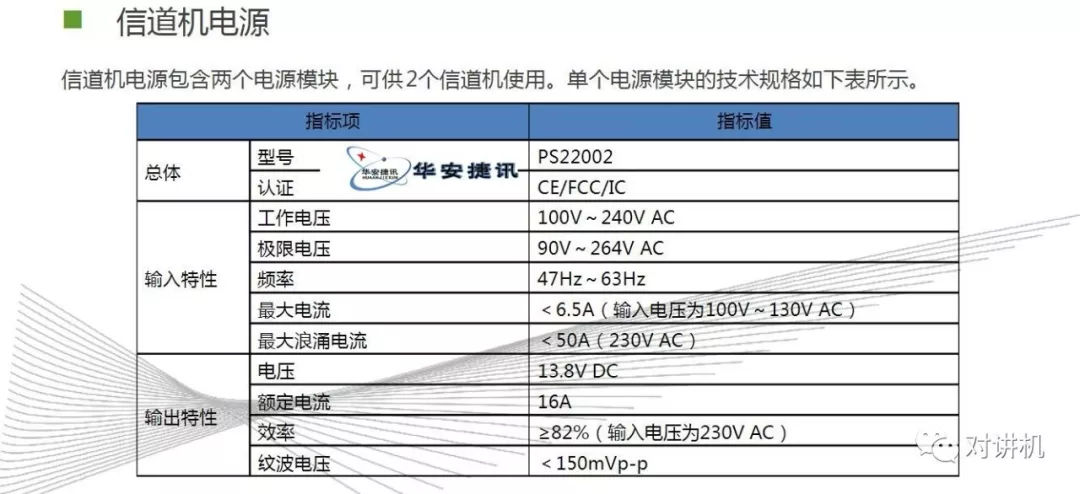
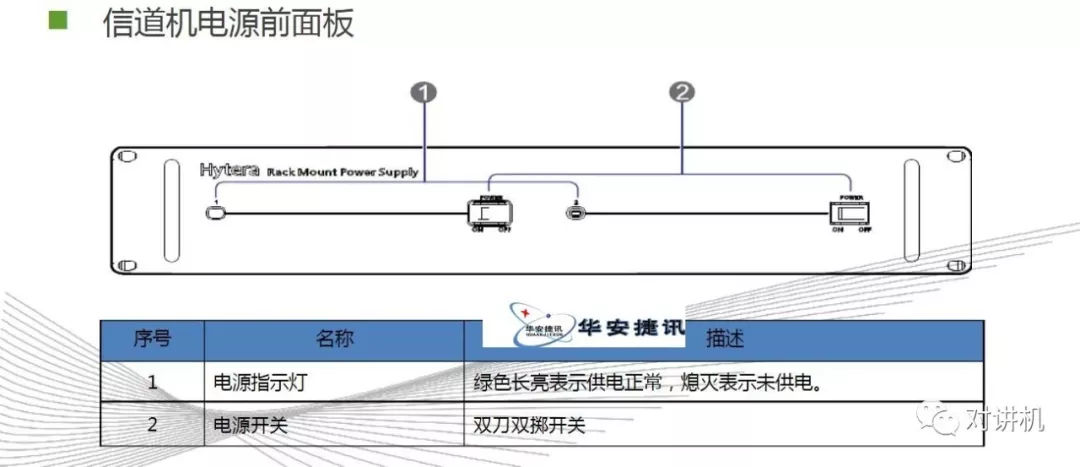
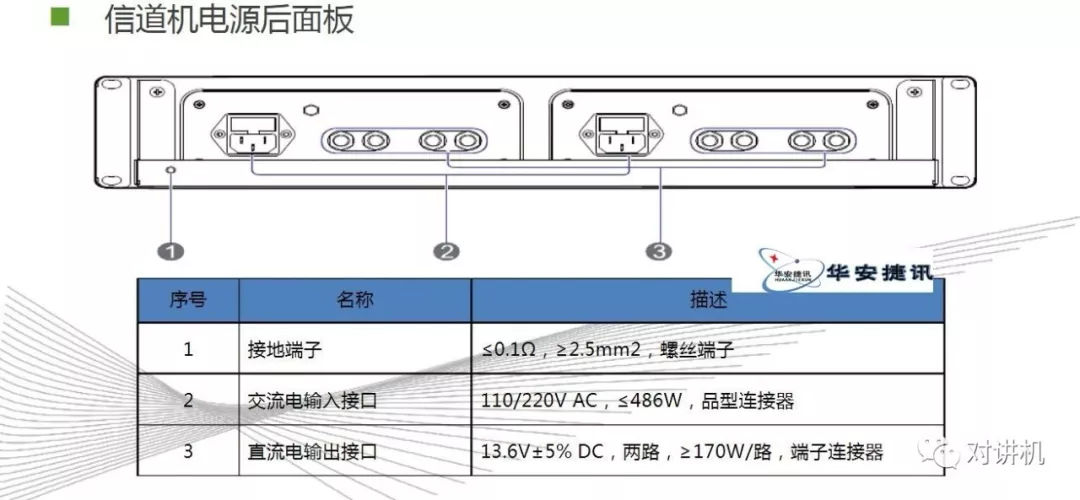
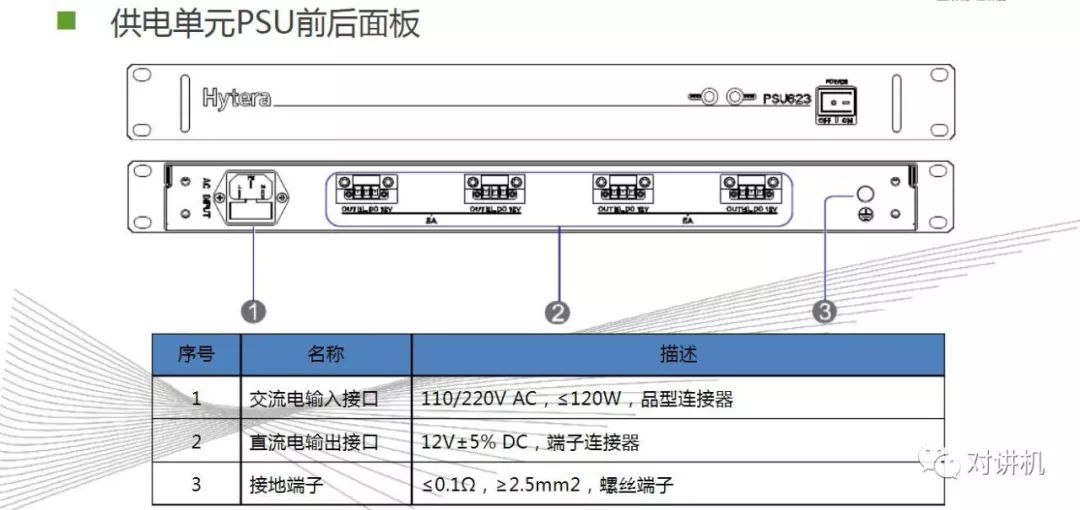
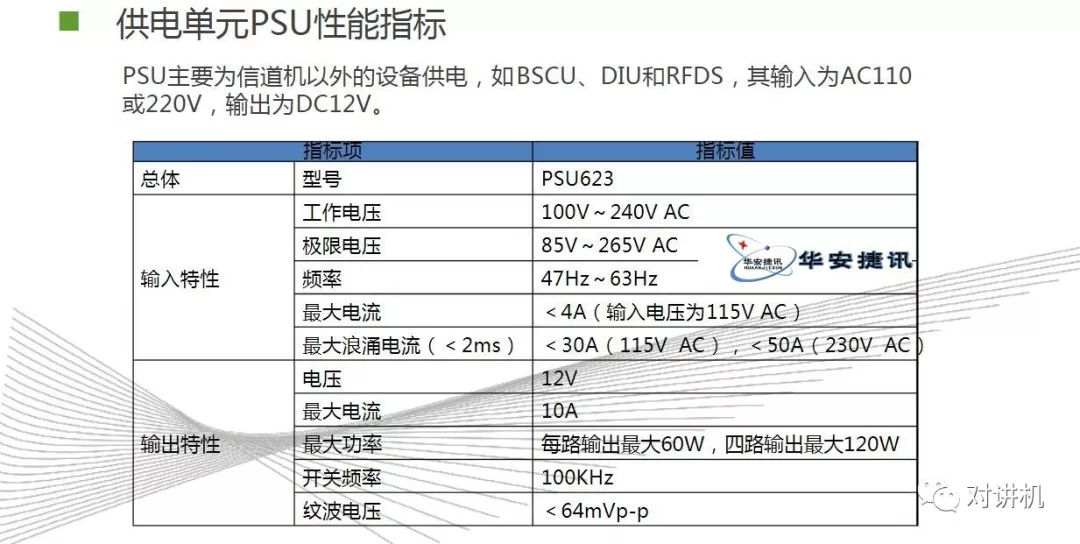
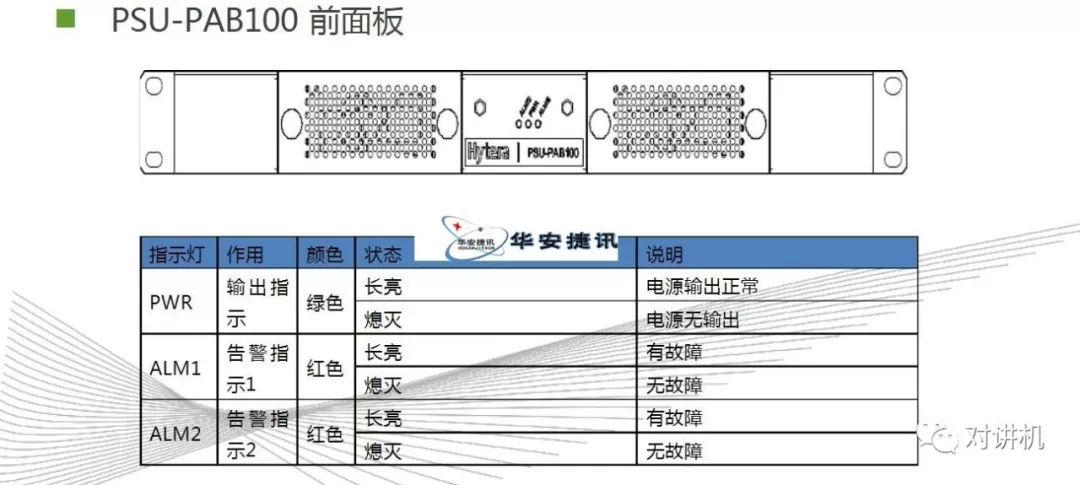
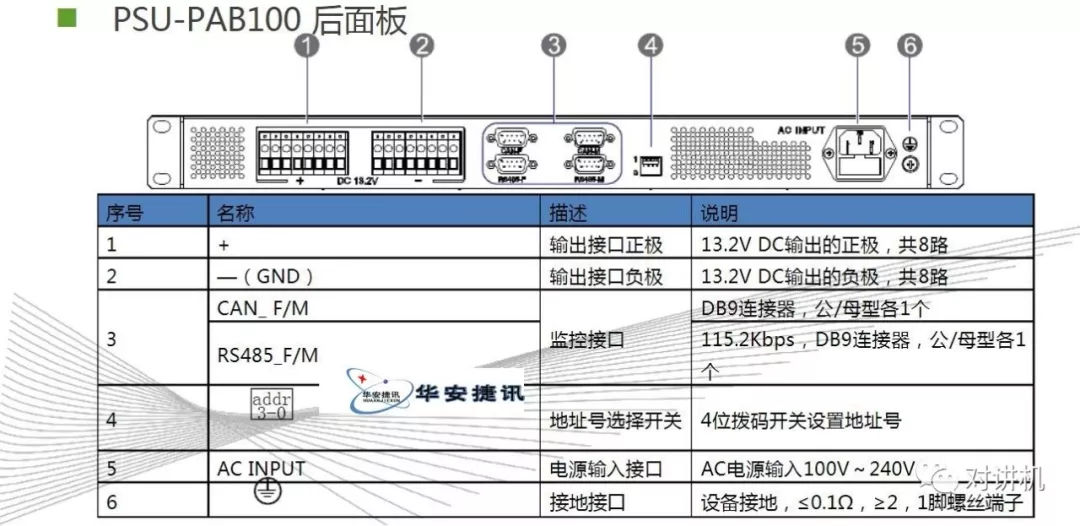

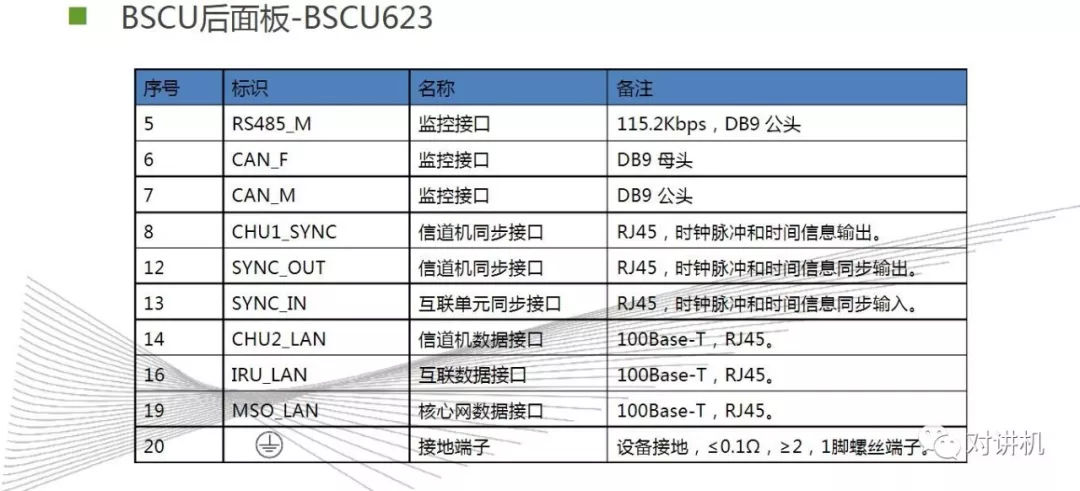
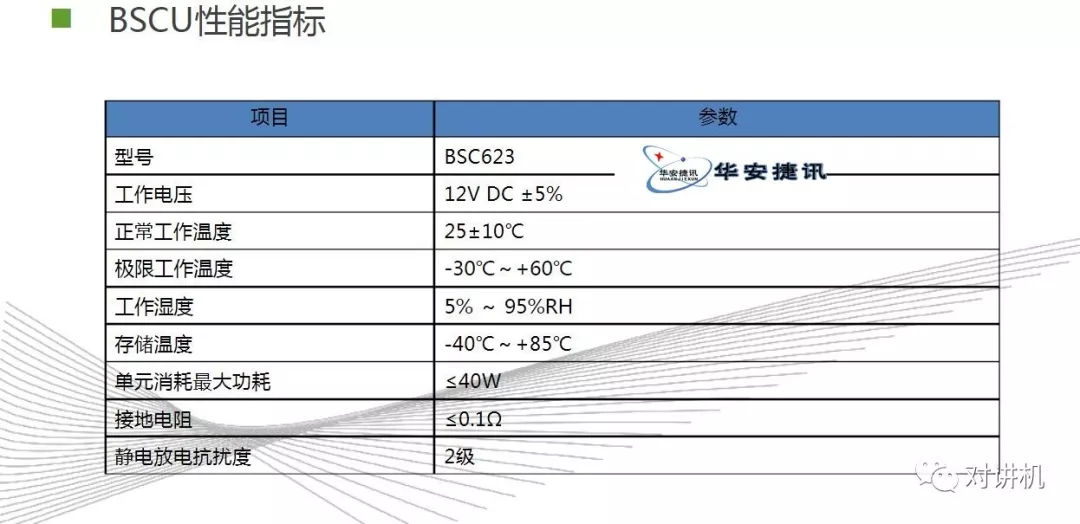
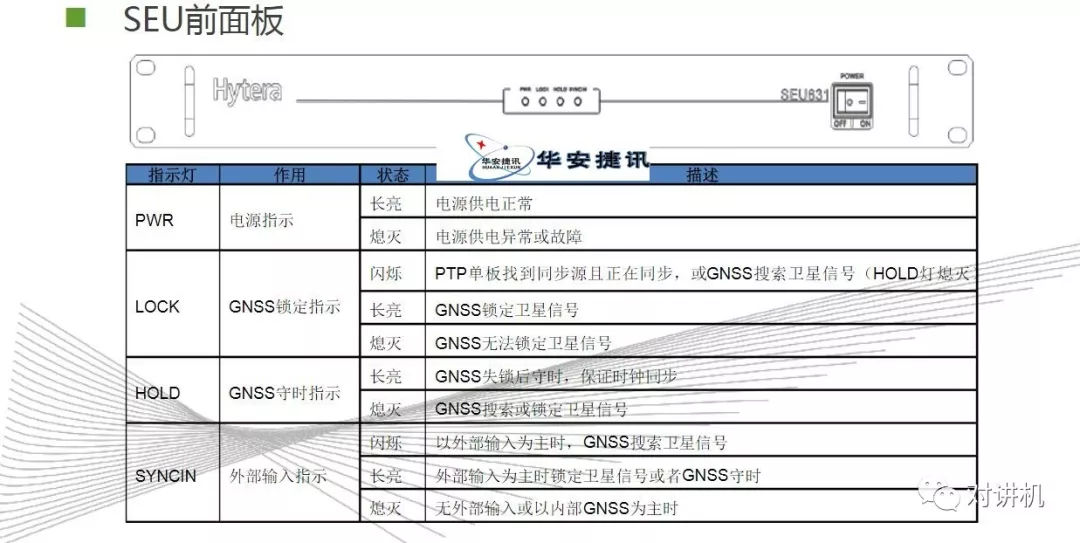
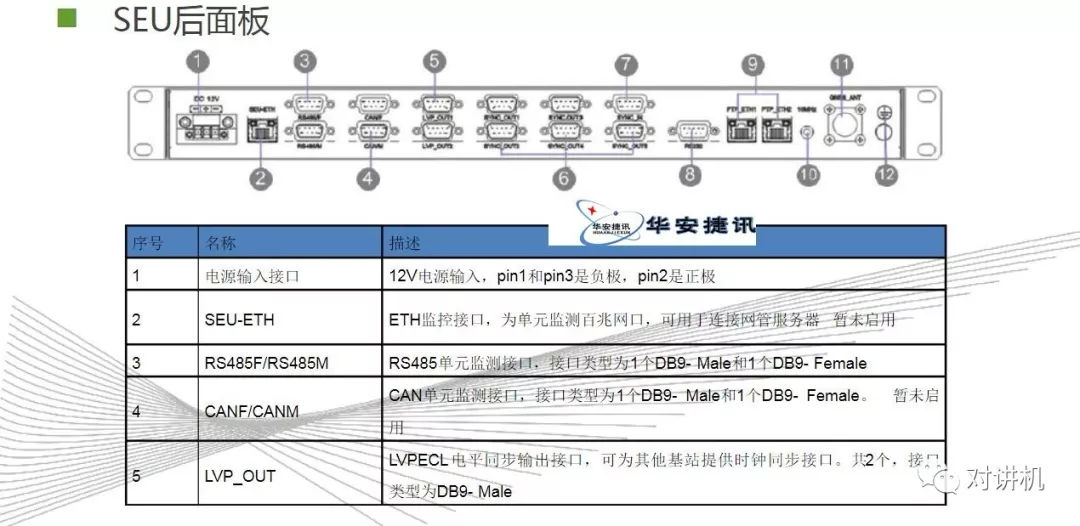
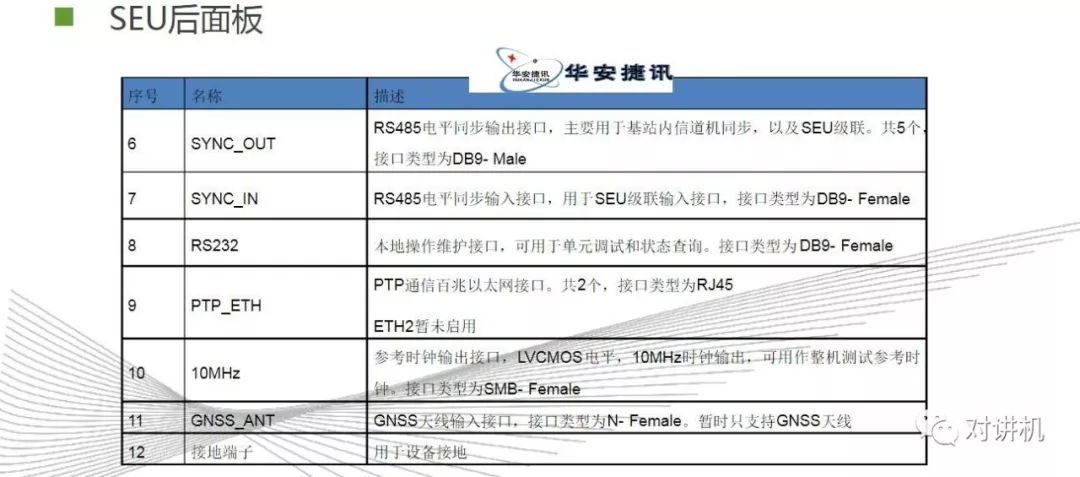
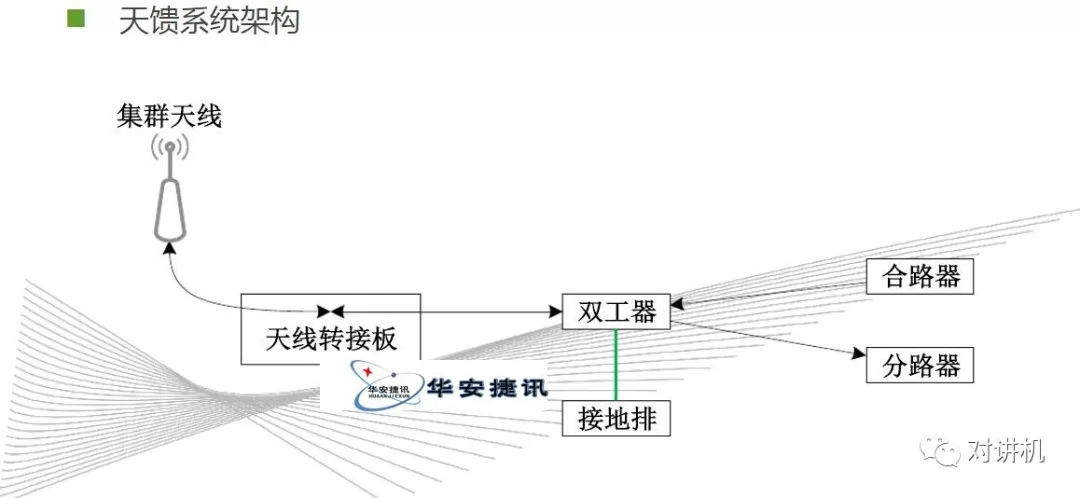
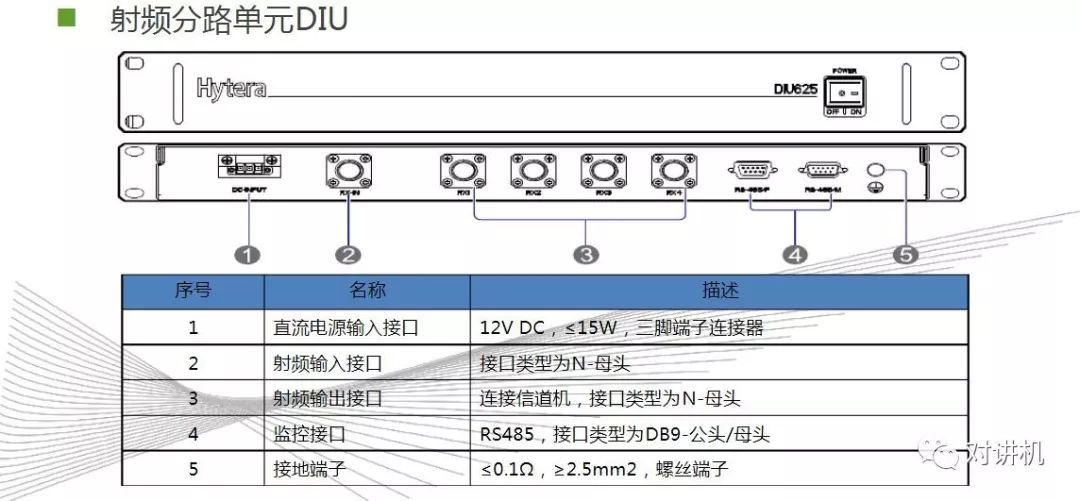
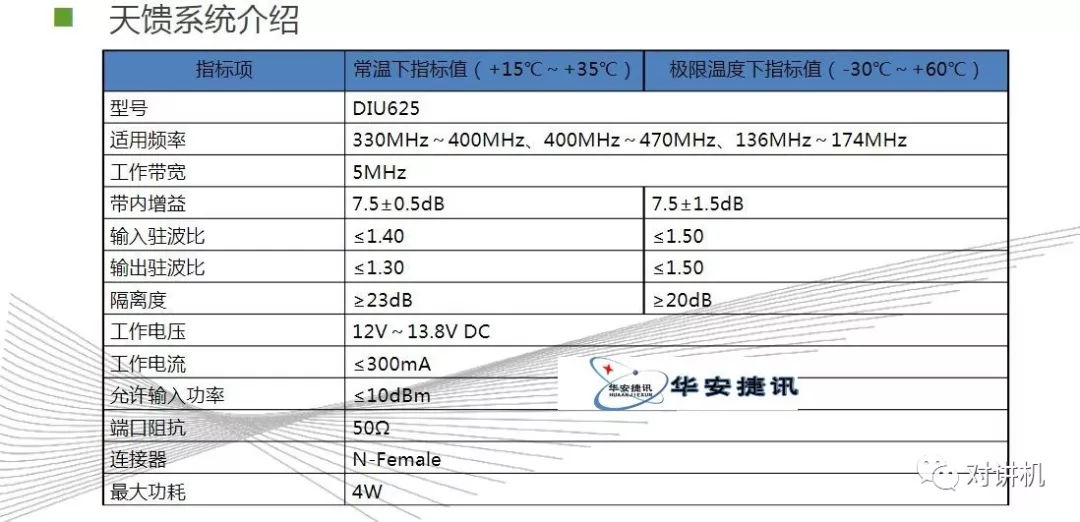
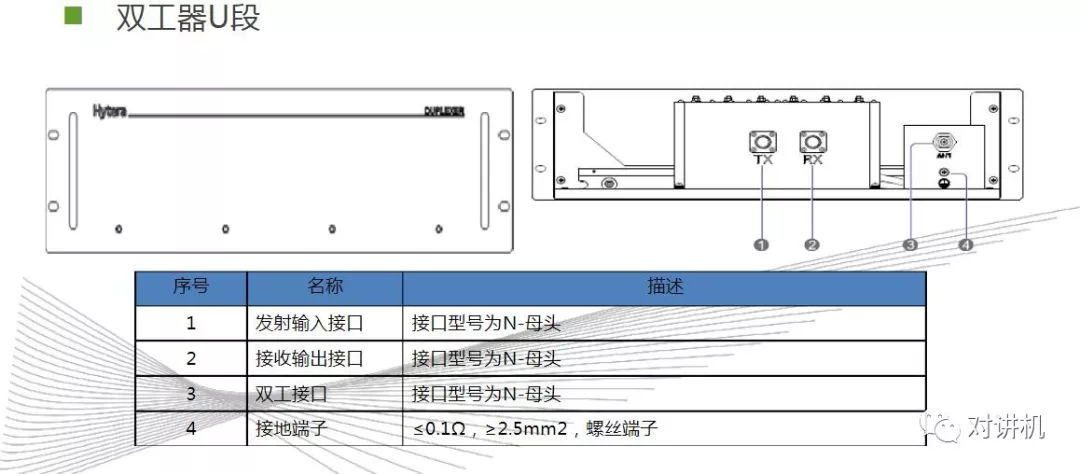
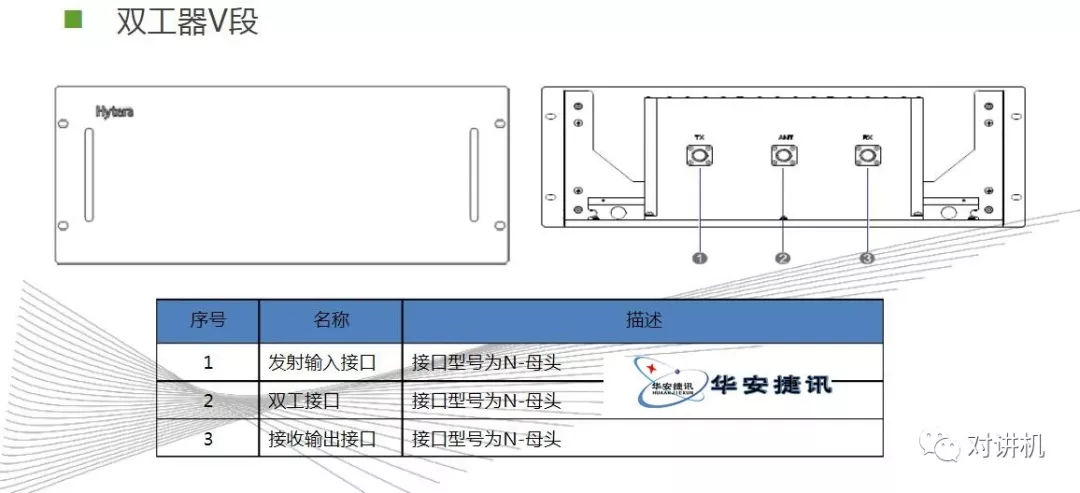
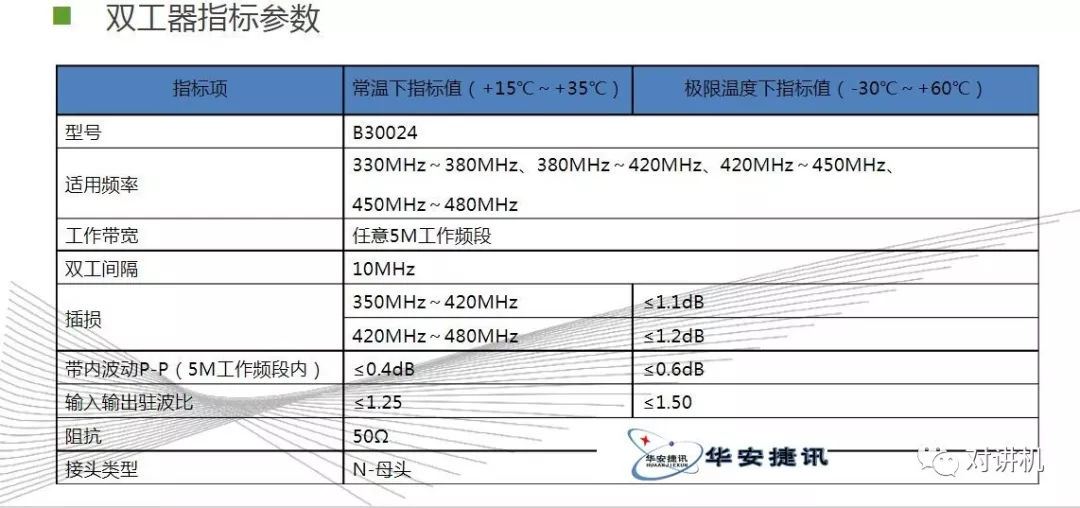
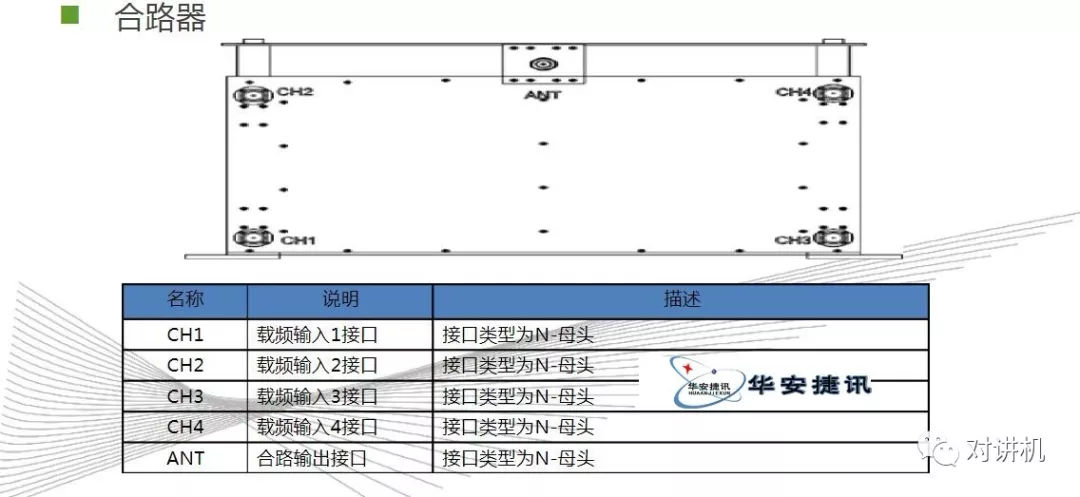
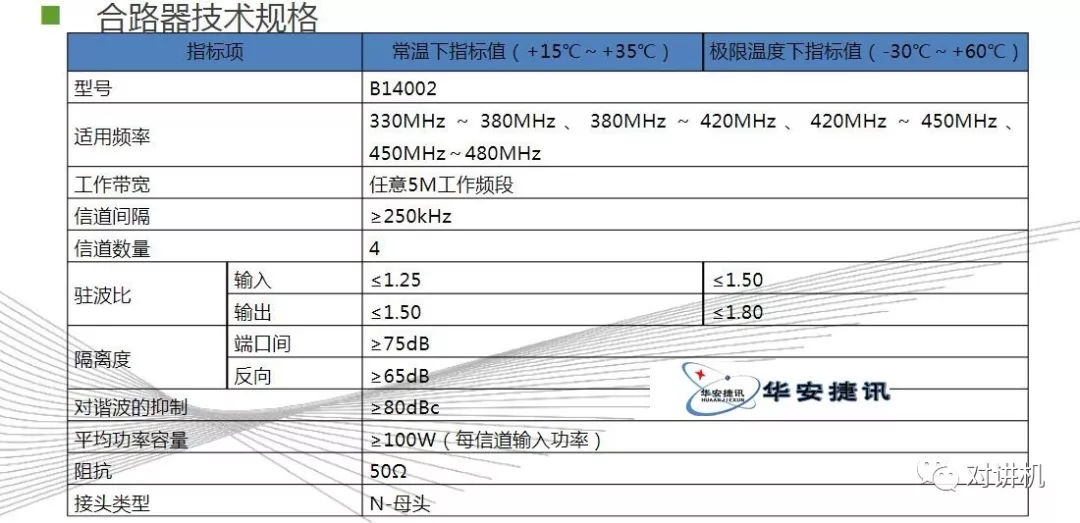
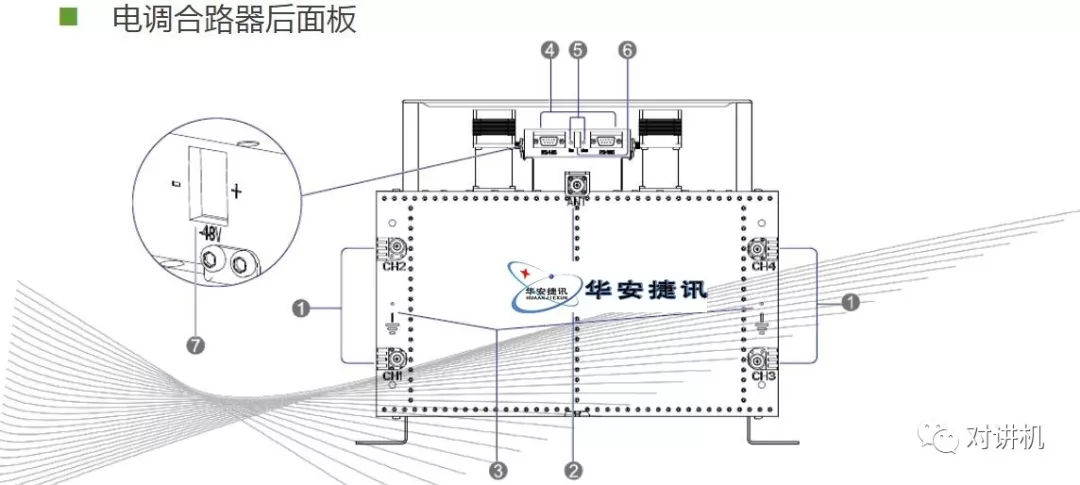
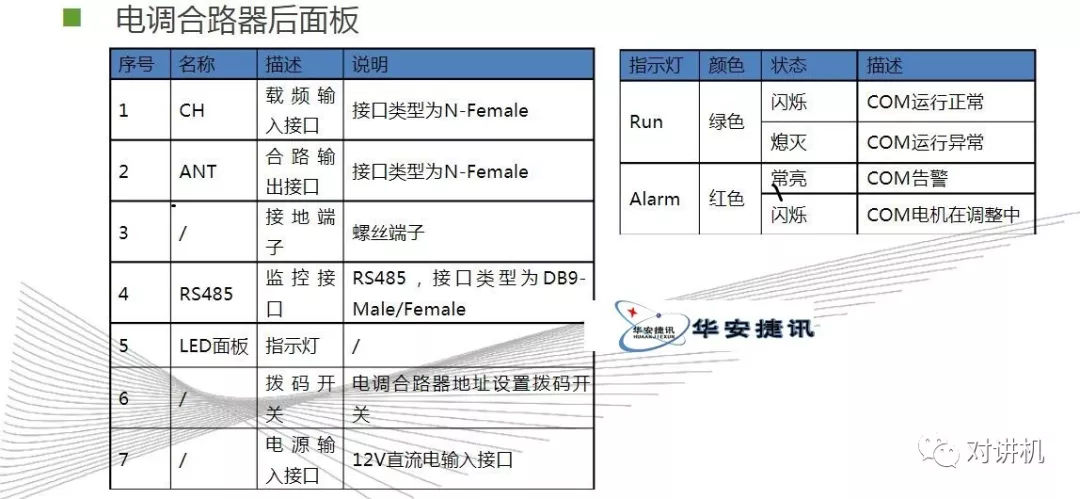
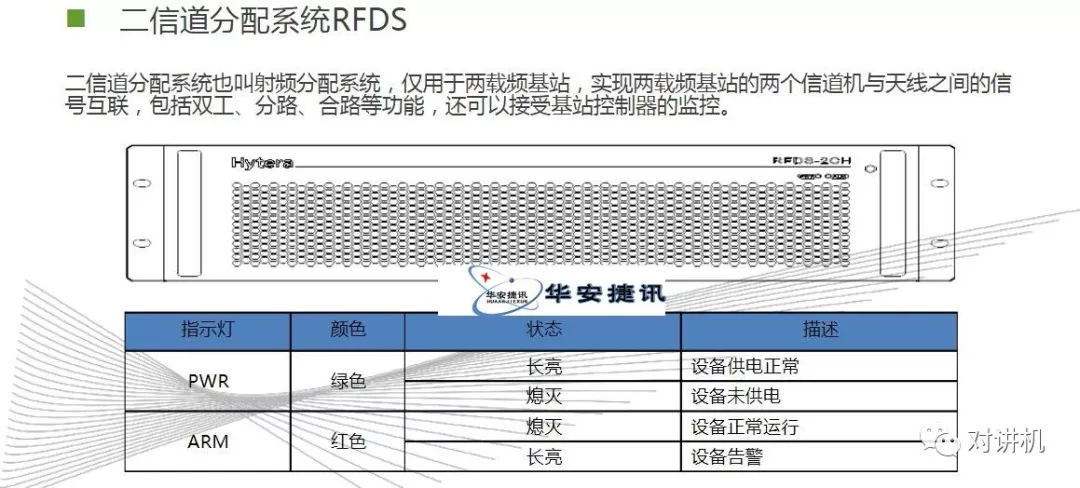
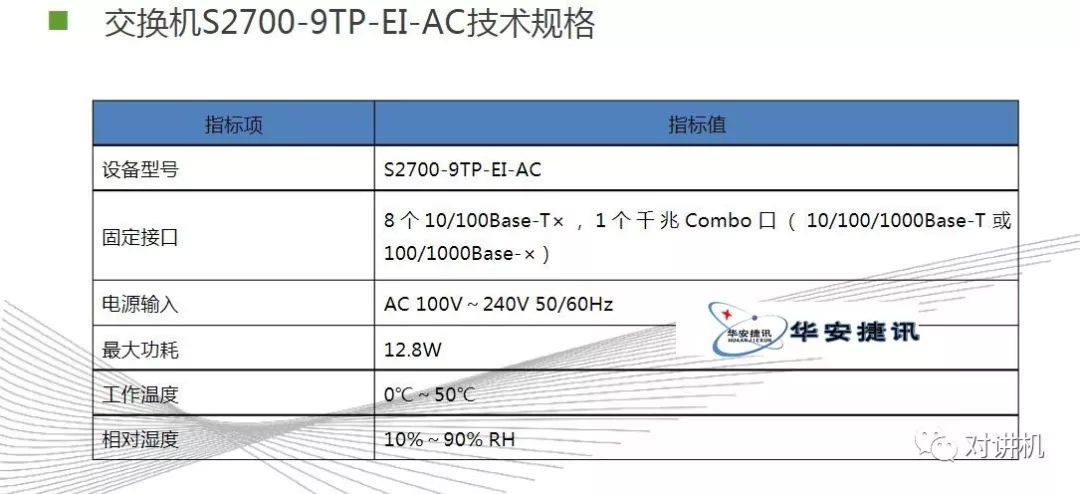
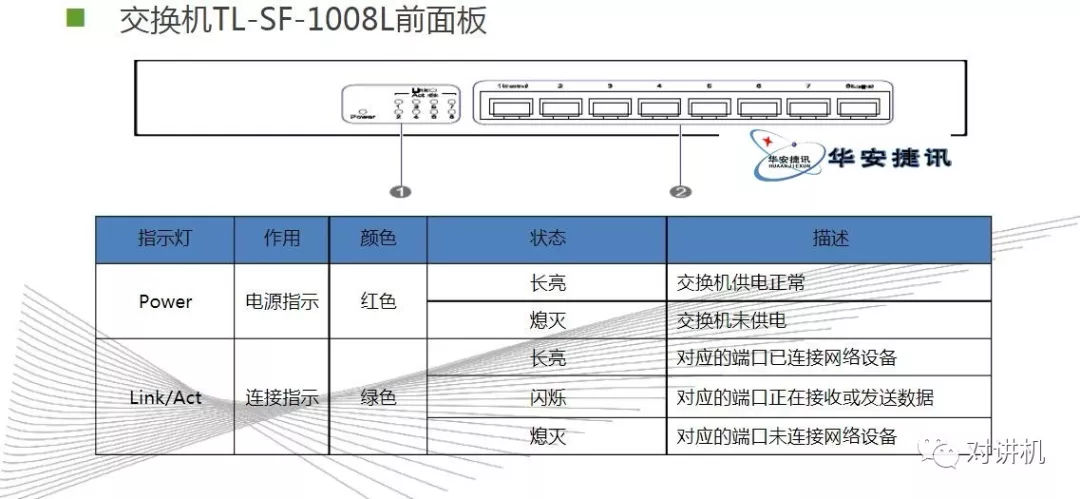
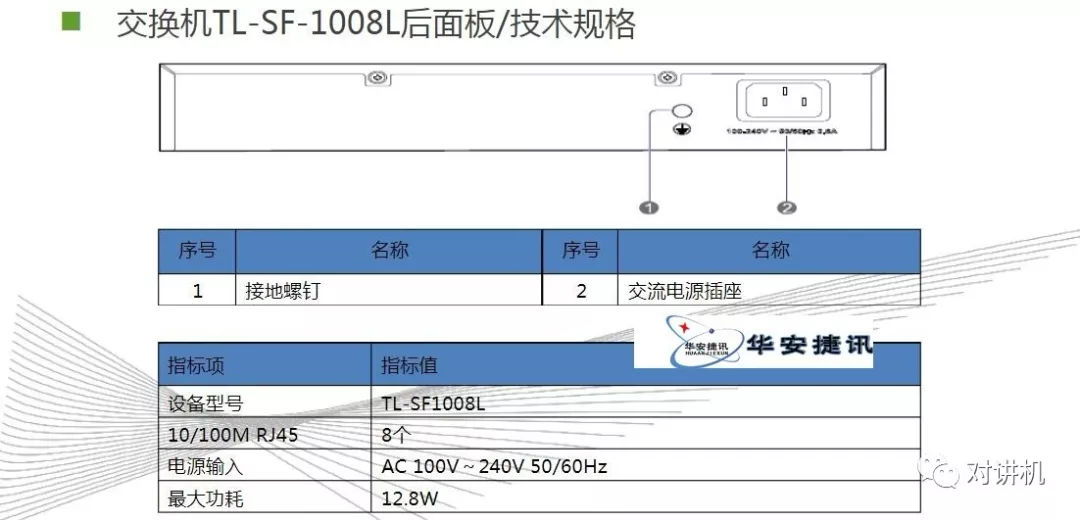
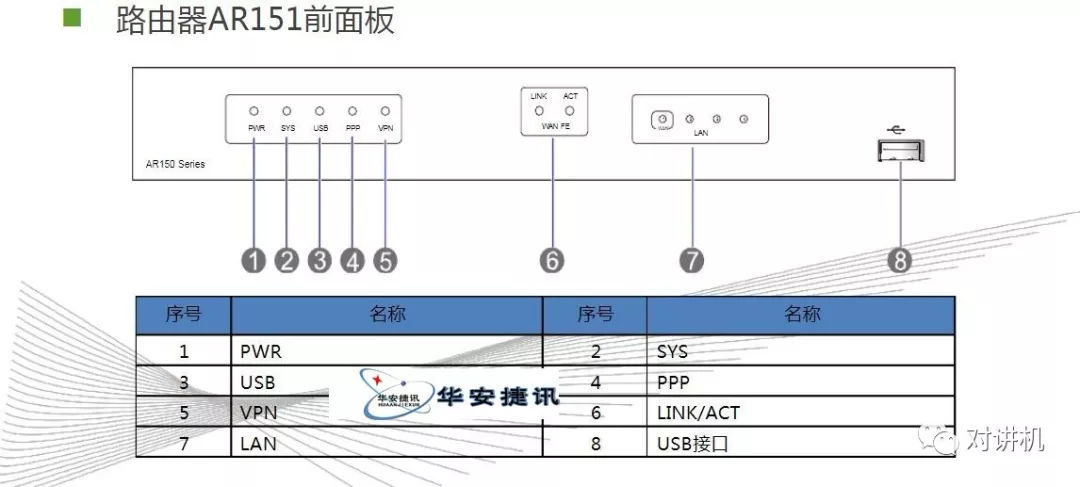


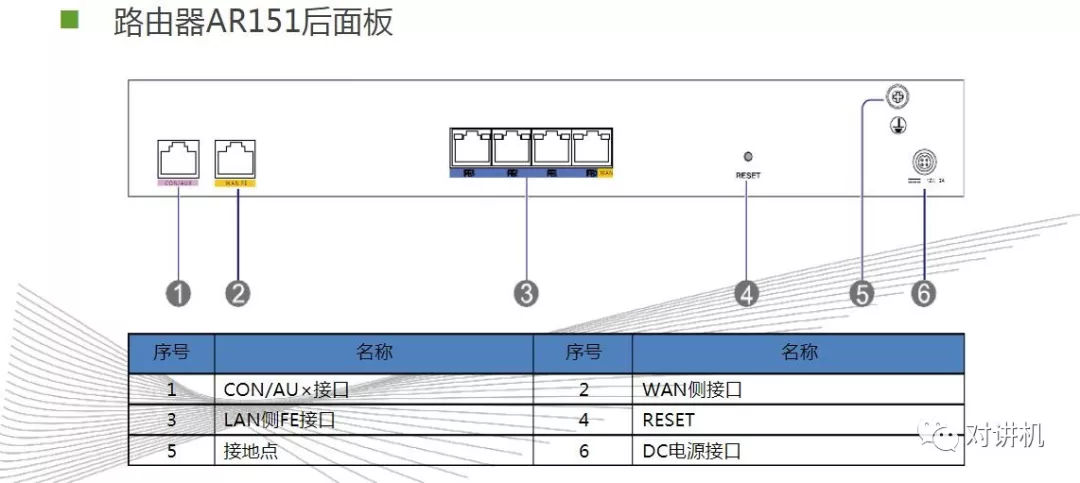
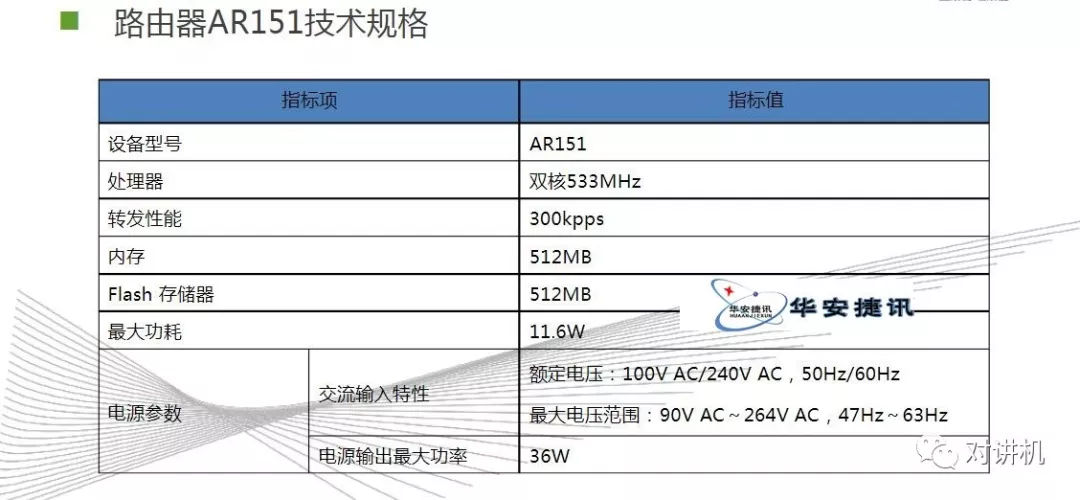
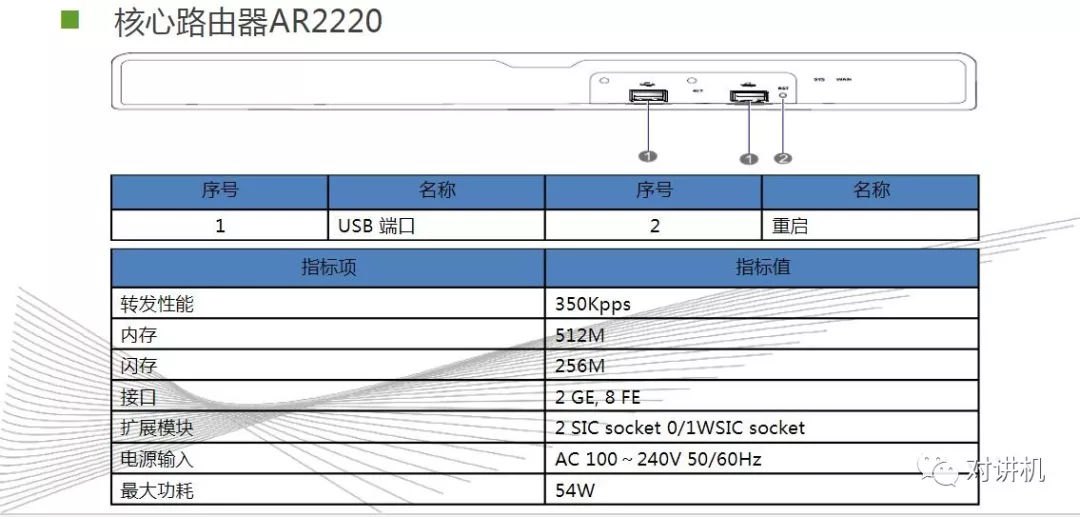
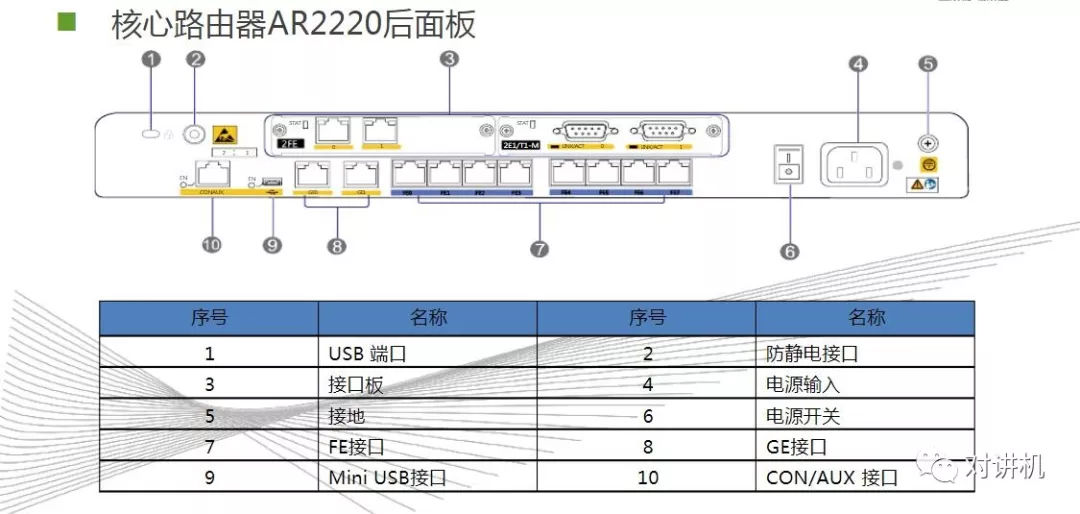
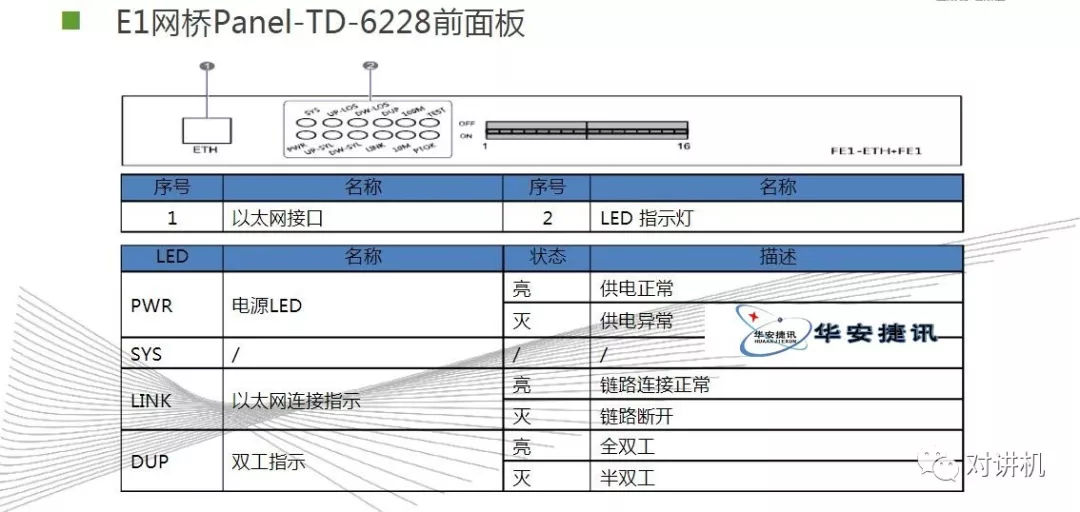
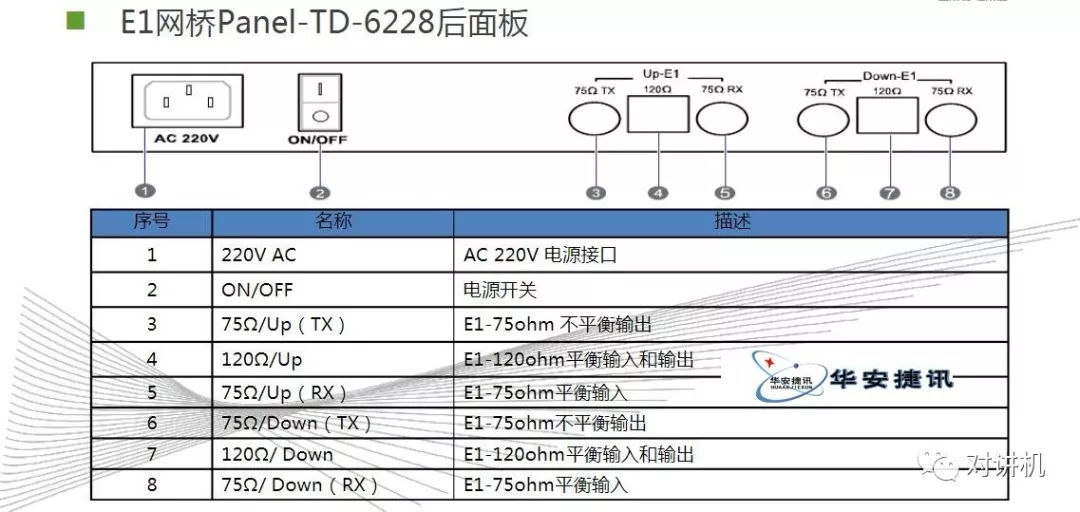
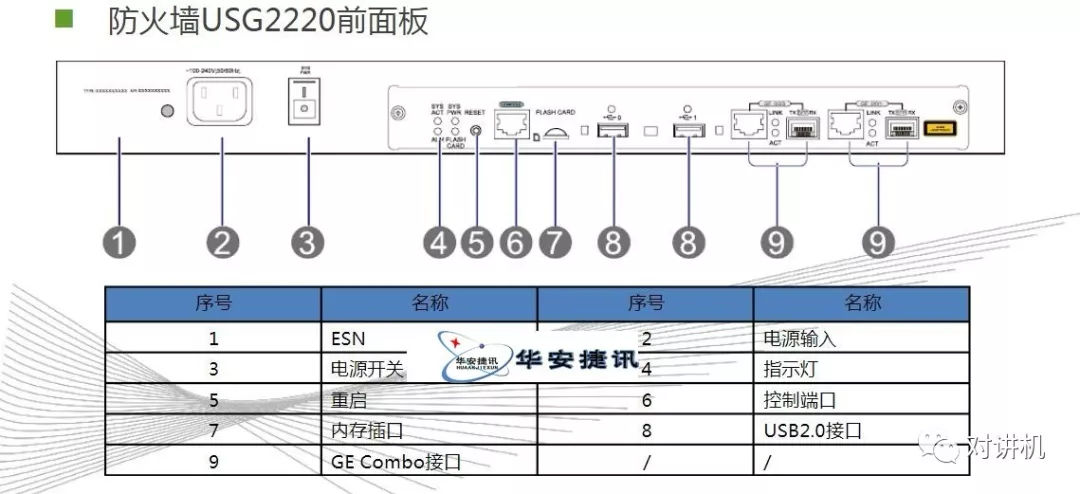
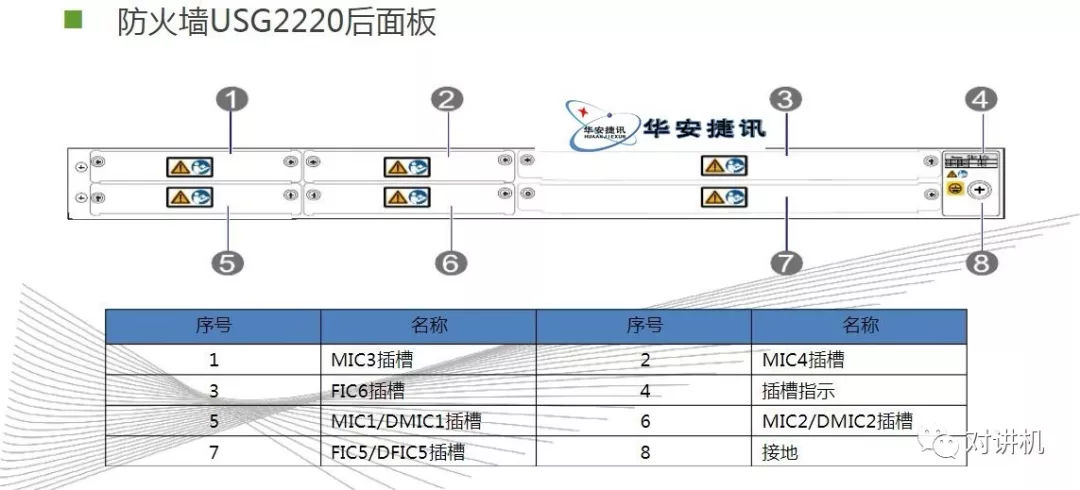

CUDA学习(三)
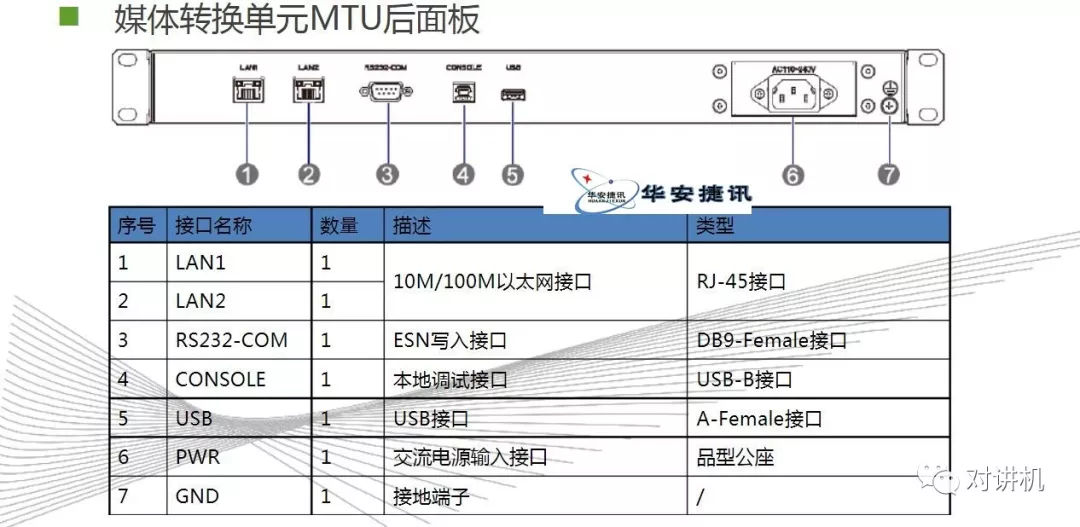
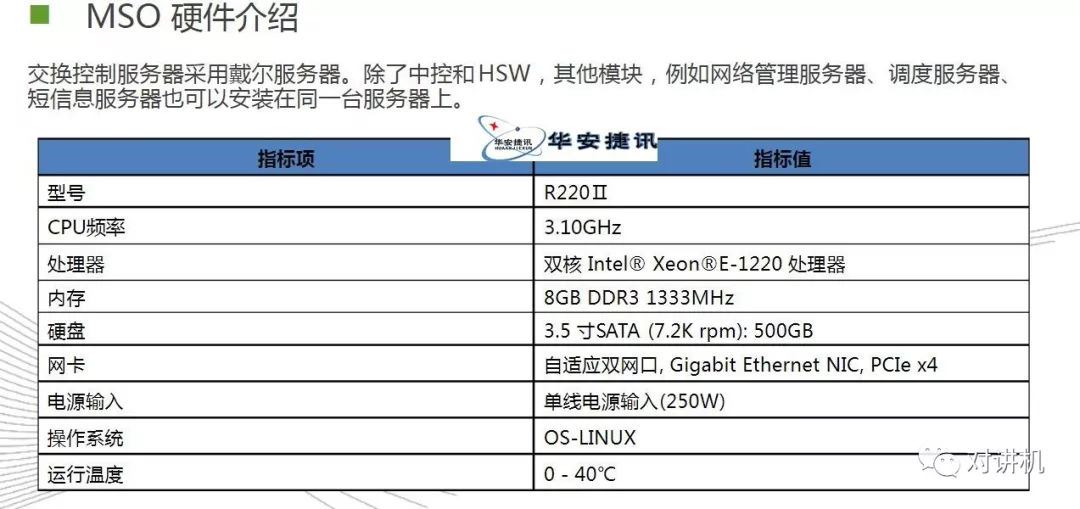
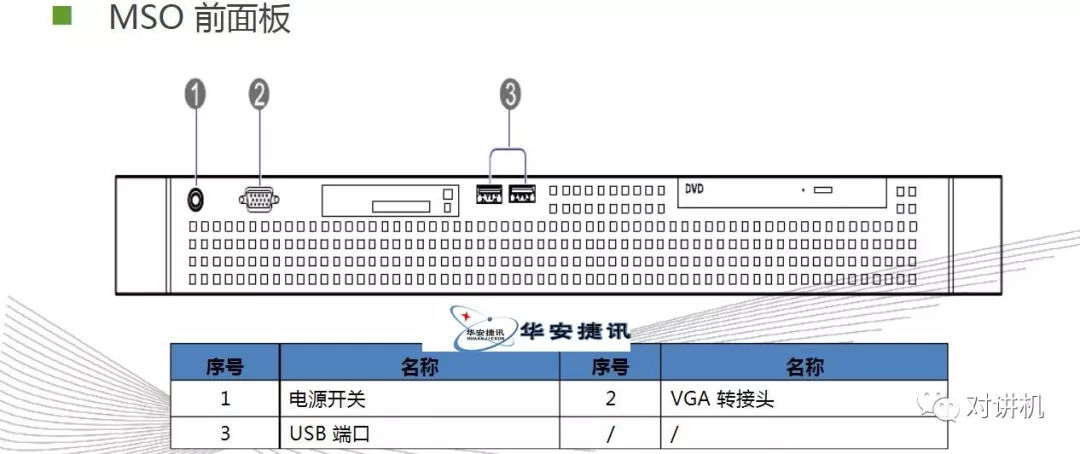
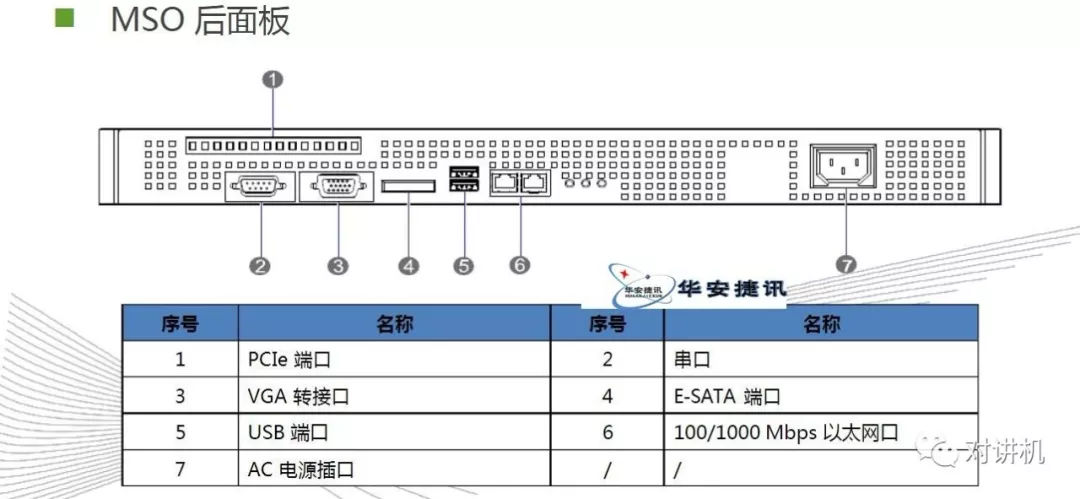
内存层次结构:CUDA线程可能会在执行期间从多个内存空间访问数据,如图所示。每个线程都有专用本地内存(local menory)。 每个线程块都具有共享内存(shared memory),该块的所有线程都可见,并且具有与该块相同的生命周期。 所有线程都可以访问相同的全局内存(global memory)。所有线程还有两个额外的只读内存空间:常量和纹理内存空间。 全局,常量和纹理内存空间针对不同的内存使用进行了优化。 对于某些特定的数据格式,纹理内存也提供了不同的寻址模式以及数据过滤功能。全局,常量和纹理内存空间在同一应用程序的内核启动时保持不变异构编程(Heterogeneous Programming):这里设GPU设备为Device,CPU设备为Host,如图所示,kernel函数在Device上运行,其余C语言程序依然上CPU上运行。CUDA编程模型还假定主机和设备都在DRAM中分别维护它们自己的独立存储空间,分别称为主机存储器和设备存储器。 因此,程序通过调用CUDA运行库来管理内核可见的全局,常量和纹理内存空间(在编程接口中描述)。 这包括设备内存分配和重新分配以及主机和设备...