MEC的优势,就是可以把计算、存储资源分散在网络的各个部分,而应用可以从MEC中按需获取,而MEC的部署方式也是为了满足应用对低延迟的要求。
应用计算量重分配
那么什么应用需要到边缘云上进行计算?或者多少计算量和什么计算量需要到边缘云上计算。这个问题有三种选项:
1、本地处理,全部的计算都在终端进行处理;
2、所有流量都通过MEC处理;
3、一部分本地处理,一部分MEC处理;
而计算能力的重分配(offloading) 取决于很多因素。比如用户的喜好、回程链路的质量保证、终端设备的计算能力、MEC云的计算能力等。因此如何定义应用计算量offloading的策略也是学术界正在研究的方向。
目前来看,有研究价值的第三种,即应用的计算量一部分本地处理,一部分远端处理。由于一些部分应用数据不适合由远端处理(如相机处理图片、用户输入输出、位置数据),而且有些应用不能估计多少的数据量,也无法估计要传输多久(比如在线游戏)也不适合由MEC来进行处理。
比较适合由MEC处理的数据则是人脸识别、病毒扫描等,这些应用都是需要把数据传到后台庞大的数据库中,一般数据库由于其占有的存储资源比较大,因此适合部署在MEC中。
应用切片
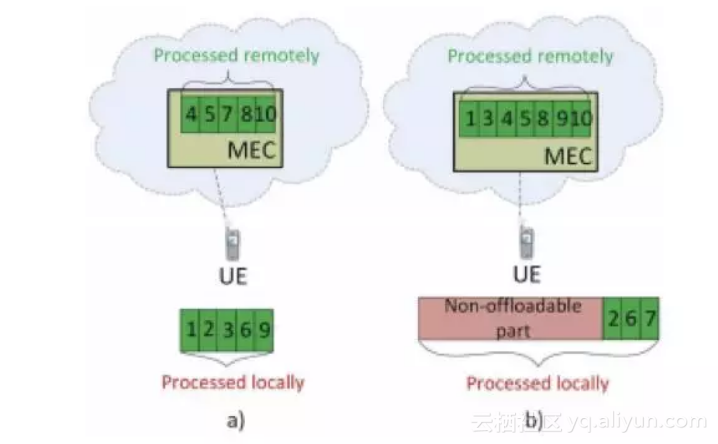
由于应用有一个完整的生命周期,其中产生的需要被处理的数据需要按照一定的规则进行切片,比如一个应用中需要被处理的数据切片成1-10份,设置为Optional,那么这10份数据在一定的策略下可以由本地处理,也可以全部由MEC进行处理。如何进行计算处理是基于一定的Policy,比如当前的网络状况和MEC的负载生成的Policy规定4,5,7,8,10由MEC进行处理,那么剩余的则有终端在本地进行处理。另外适合本地处理的数据量会被设置成为Non-offloading,那么这些数据量则由终端本地处理。如下图所示:
![f590f1ffe28caa6250af0a30ecdeb07c8bba0d81]()
数据依赖性
数据的依赖性在分布式系统中都是无法避免的问题,举个例子,在OpenStack的高可用部署的情况下,一般Stateless的组件都是三个active的状态(如RabbitMQ),在创建虚拟机时,都是需要先创建网络的,如果创建网络的消息被消息队列处理时,发生了网络延迟,而创建虚拟机的消息被另外的消息队列先处理了(网络延迟的情况下是可能发生的),要么在程序中就需要加锁,等待网络创建,要么就是在程序中直接报错,抛出虚拟机创建错误。
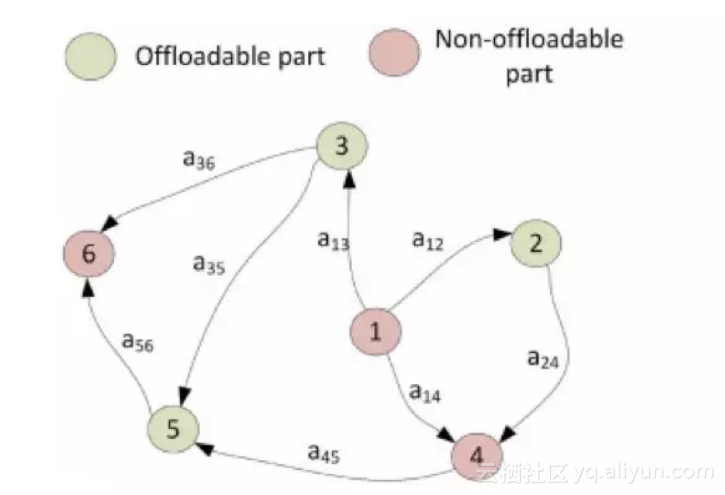
在边缘计算的场景下,由于边缘云和中心云以及终端程序的地域跨度更大,网络延迟更高,因此发生应用的数据依赖性的问题更加严重。因此从应用的角度出发,也需要应用来调整如何来满足边缘计算的新的基础设施架构。如下图所示,Offloadable part和Non-offloadable part的数据处理相互依赖,从而会引起了数据依赖性的问题。
![adef89a44098e180951840098bdbce2719e61672]()
目前学术界在定义一些组件,如何来满足应用计算量重分配(offloading)的困难:
1、 code profilter来确定哪些数据需要远端处理;
2、 system profilter来确定需要的带宽,字节数量,资源消耗等参数;
3、decision engine来确定哪些数据需要被远端处理;
计算是否远端处理的决定的算法需要满足减小终端计算资源的消耗和最小化延迟,并在这两个指标中达到平衡。在计算节点的选择上,如果计算量无法切片,那么只能到一个计算节点进行计算;一般处于延迟低的要求,会把offloadable的数据量放在就近的MEC中,如果就近的MEC资源不足,那么需要调度到远处去计算,需要同时满足耗电量小和延迟低。由于MEC可能有多个Cluster,那么如何充分利用每个Cluster的资源,也是需要被考虑进去的。
Vm migration
由于有些MEC上的虚拟机部署了合适它附近的终端进行数据的应用。如果终端在地理位置上进行转移,那么改MEC上的虚拟机也需要跟着迁移。需要考虑的是,即使虚拟机迁移只花费数秒钟的时间,也会使得实时的应用只能在终端处理,或者是到其他远处的虚拟机上进行处理。这其实也是需要权衡利弊的,因此将虚拟机迁移分成了可量化的三种变量:
1.VM migration cost(Cost M)迁移时间和迁移所需资源量;
2.VM migration gain(Gain M)延迟减少的时间,缩短路径所节约的资源;
3.目标服务器上本身的计算量;
根据上述这三种变量,需要研究一种算法,确定虚拟机是否需要迁移,另外,需要找到一个合适的MEC的节点进行迁移,满足到终端链路短,网络资源消耗少等需求。1如果终端设备到服务端的链路质量差,那么在本地计算。如果目标服务器本身计算量小,链路质量又好,应用又可以满足短暂的切换所带来的本地临时处理数据的情况,那么则可以迁移。
原文发布时间为:2018-09-18
本文作者:魔性小章鱼
本文来自云栖社区合作伙伴“Linux宝库”,了解相关信息可以关注“Linux宝库”。