虽说是转载的,但是其中,有很多我自己的评论,我会用红色的字标出来,参考的博文有:
TSF架构:http://blog.csdn.net/mspinyin/article/details/6137709
TSF代码实例:http://www.dotblogs.com.tw/code6421/archive/2010/09/27/17909.aspx
TSF的一个C# Wrapper库:http://social.technet.microsoft.com/Forums/office/zh-CN/002efcfc-8d21-4674-b93b-53c8424d448e/vista-api-immgetdescription?forum=2087
下面内容来自第一篇被引用的文章,TSF架构:
几个关于TSF的术语
TIP (Text Input Processor), a Text service in TSF
Cicero,TSF的开发代号,所以微软内部通常称呼TSF框架为Cicero
CUAS (Cicero Unaware Application Support),为所有应用程序和控件提供基本的TIP支持
AIMM(Active Input Method Manager),和CUAS一起工作
输入法框架
先讲一点点历史,Windows提供了两套输入法框架: Windows XP及之前,是IMM (Input Method Manager),基于纯函数API的。目前市面上非微软中文输入法基本上都是只实现IMM框架。
Windows XP开始及以后,Windows提供新的输入框架TSF,是基于COM的。实际上,到了Windows Vista,Windows 7,所有的应用程序和各种输入控件都是优先使用TSF的实现。但之所以Windows Vista,Windows 7用户还能使用各种基于IMM的输入法,是因为Windows提供了一个组件来将所有TSF的请求转为IMM的API。(PunCha:难道Win8开始就不提供了吗?!很有可能,因为Win8下很多Imm的函数都不能使用了)
按照微软的说法,TSF会最终取代IMM框架。而微软拼音基于兼容,功能和性能方面的原因,将这两个框架都实现了。(PunCha:Win8下,只有你们一家还能用Imm的API,很厚道!)
下面主要介绍TSF框架的输入法及与应用程序的交互。
TSF框架
Cicero它的目标是提供一套简单通用并易扩展的框架,用于高级文本输入和自然语言处理。一个TSF text service能够提供多语言支持和处理:键盘输入(我们通常讲的输入法),手写识别,语言识别等。
![]()
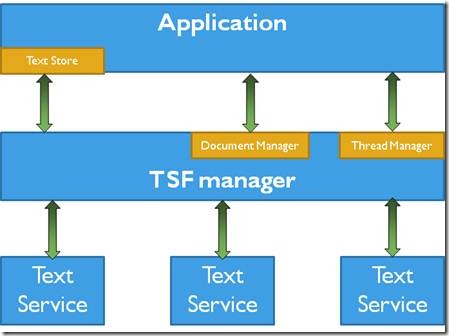
TSF的构架图
从上面构架图可以看到,TSF提供一个位于应用和输入法实现的间接层(一个Text service/TIP可以是一个输入法,或语音识别,PunCha:记住,TIP就是一个输入法提供的一个服务,比如百度输入法提供“语音、手写、键盘”输入,那就是3个Tip,但是一般我们都是用键盘输入,所以可以简单认为Tip是一种输入法。)。所以,TSF的优点在于,它是一个设备无关,语言中立,可扩展的系统;同时给用户提供一致的输入体验。任何TSF-enabled应用程序都能从任何text service接受文字输入,而不用考虑Text source的具体细节。同时,Text service也不用考虑各种不同应用的差别。譬如下面的应用场景:
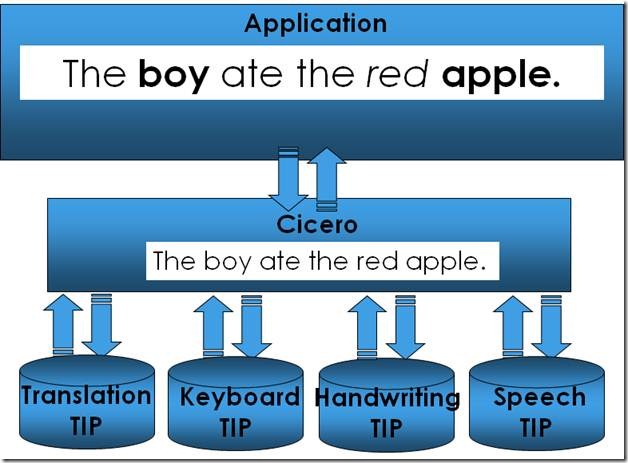
![]()
上图可以看出, 应用程序收到”The boy ate the red apple”这段文字, 但是它不知道这些字是哪个TIP输入的,有可能是”Keyboard TIP”, 或是”Speech TIP”等。
与应用程序的交互
那么,这个框架是如何工作的?看看下面的组件交互图
在windows XP下,默认是CUAS关闭的,其交互如下
![]()
从上图可见,所有“edit control”(包括Notepad)都是直接调用IMM的API,最后调用IMM输入法,而4.1版本后的“RichEdit control”(包括WordPad等)是直接用TSF实现的输入法)
(PunCha:注意,是TSF依赖于Imm)
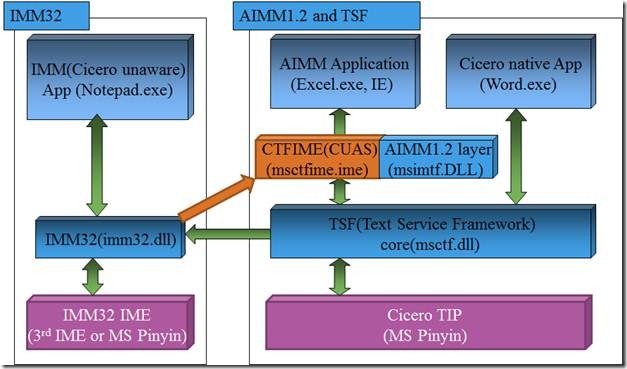
在Windows XP下如果打开CUAS,或者在Windows Vista和Windows 7下,则如下交互:
![]()
可以看到,IMM32和CUAS中多了一条交互,这意味着如果一个输入法实现了TIP,在Windows Vista和Windows 7,或CUAS打开的Windows XP下,应用程序的所有输入由TIP实现完成。
(PunCha:注意,Imm依赖于CUAS了!即可以使用用TSF实现的输入法了,应该就是高级输入)
下面内容来自第二篇被引用的文章的一条注释,使用TSF COM API获得输入法信息:
#include <windows.h>
#include <msctf.h>
int _tmain(int argc, TCHAR* argv[])
{
CoInitialize(0);
HRESULT hr = S_OK;
//PunCha:创建Profiles接口被
ITfInputProcessorProfiles *pProfiles;
hr = CoCreateInstance( CLSID_TF_InputProcessorProfiles,
NULL,
CLSCTX_INPROC_SERVER,
IID_ITfInputProcessorProfiles,
(LPVOID*)&pProfiles);
if(SUCCEEDED(hr))
{
IEnumTfLanguageProfiles* pEnumProf = 0;
//PunCha:枚举所有输入法咯
hr = pProfiles->EnumLanguageProfiles(0x804, &pEnumProf);
if (SUCCEEDED(hr) && pEnumProf)
{
TF_LANGUAGEPROFILE proArr[2];
ULONG feOut = 0;
//PunCha:其实proArr这里应该写成 &proArr[0],因为里面只需要一个TF_LANGUAGEPROFILE变量!而且,proArr[1]都没用到过!
while (S_OK == pEnumProf->Next(1, proArr, &feOut))
{
//PunCha:获取他的名字
BSTR bstrDest;
hr = pProfiles->GetLanguageProfileDescription(proArr[0].clsid, 0x804, proArr[0].guidProfile, &bstrDest);
OutputDebugString(bstrDest);
wprintf(bstrDest); printf("\n");
BOOL bEnable = false;
hr = pProfiles->IsEnabledLanguageProfile(proArr[0].clsid, 0x804, proArr[0].guidProfile, &bEnable);
if (SUCCEEDED(hr))
{
printf("Enabled %d\n", bEnable);
}
SysFreeString(bstrDest);
}
}
pProfiles->Release();
}
CoUninitialize();
return 0;
}