斯坦福大学计算机系助理教授、斯坦福人工智能实验室成员 Percy Liang 主要研究方向为自然语言处理(对话系统,语义分析等方向)及机器学习理论,他与他的学生合作的论文刚刚获得 ACL 2018 短论文奖,其本人亦是 2016 年 IJCAI 计算机和思想奖(Computers and Thought Award)得主。
Percy 的团队推出的 SQuAD 阅读理解挑战赛是行业内公认的机器阅读理解标准水平测试,也是该领域的顶级赛事,被誉为机器阅读理解界的 ImageNet(图像识别领域的顶级赛事)。参赛者来自全球学术界和产业界的研究团队,包括微软亚洲研究院、艾伦研究院、IBM、Salesforce、Facebook、谷歌以及卡内基·梅隆大学、斯坦福大学等知名企业研究机构和高校,赛事对自然语言理解的进步有重要的推动作用。
香侬科技:SQuaD (The Stanford Question Answering Dataset) 在推进机器阅读理解和问答领域非常成功。然而,除了可以被 NLP 研究者用来开发更好的阅读理解系统,你认为这个数据集是否潜藏着其他机会?
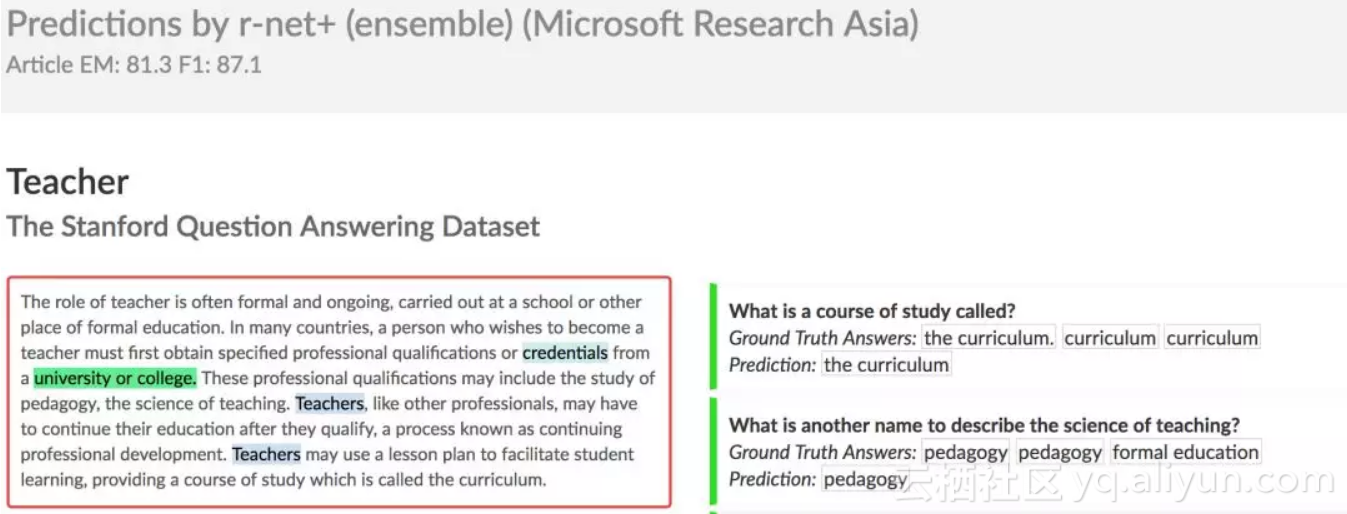
![9599e30f696cc0da7ed8eb2c60b77121864c5582]()
▲ 图1. SQuaD中的样本举例
Percy:虽然 SQuaD(实际上,任何阅读理解数据集)名义上都是关于阅读理解的,但我认为它们可以有两个方面更广泛的影响:第一,数据集鼓励人们开发新的通用模型。例如,神经机器翻译产生了基于注意力的模型,这在机器学习领域里如今已成为最常见的模型之一。第二,在一个数据集上训练的模型对其他任务是有价值的。例如,在 ImageNet 上训练卷积神经网络,模型会学习到可用于各种视觉问题的通用图像特征。
SQuaD 所带来的影响与上面列出的两个例子类似(尽管可能不及它们那么大)。SQuaD 已经达到了极限,因为多个系统已经超过了这个数据集上的人类水平。
但是,正如 Robin Jia 和我在 EMNLP 2017 的一篇论文中所展示的那样,这样的系统可以很容易地被对抗样本所愚弄,在即将到来的 ACL 2018 中,我们有一篇论文将发布 SQuaD 2.0,它包含 5 万个额外的问题,它们看起来像是有答案的问题,但实际上没有答案。希望这样一个新的数据集,与最新层出不穷的其他数据集(例如,RACE、TriviaQA 等)的出现,将有助于推动该领域的进步。
香侬科技:过去您和您的学生已经做了许多非常有影响力的关于人工智能安全的工作(Raghunathan et al. ICLR 2018,Steinhardt et al. NIPS 2017)。同时,您还对神经网络的可解释性进行了研究,包括 Koh et al., ICML 2017 最佳论文。您认为提高深度神经网络的解释性有助于解决人工智能的安全问题吗?为什么?
Percy:到目前为止,人工智能研究的主要驱动力一直是获得预测更准确的模型。但是,最近可解释性和鲁棒性/安全性的问题得到了更多的关注,我认为这是特别重要的,因为机器学习现在的很多应用往往涉及生命安全,非同儿戏。如自主驾驶、医疗保健等。
然而,可解释性和鲁棒性是模糊的术语,人们对它们并没有统一的定义。在这一点上,我认为仍然有许多概念性工作要做,使这些术语形式化,这样人们才可以做出可量化的进步。我们已经通过使用影响函数(influence functions, Koh et al. ICML 2017)和半定松弛(Raghunathan et al. ICLR 2018)在形式化这些术语方面取得了一些初步的进展,而这两种方法都是统计和优化的经典工具。我认为机器学习仍然是一种“雏形”阶段;它距离成为一个成熟的工程学科还有一段路程要走。
香侬科技:您的许多自然语言处理研究与人类语言处理有着密切的联系(例如,Wang et al., ACL 2016 杰出论文奖:通过人机交互使机器从零开始学习语言,He et al. ACL 2017: 通过学习动态知识图谱嵌入来构建对称合作型聊天机器人)。您认为理解人类语言处理在何种程度上会帮助我们建立更好的机器语言处理系统?
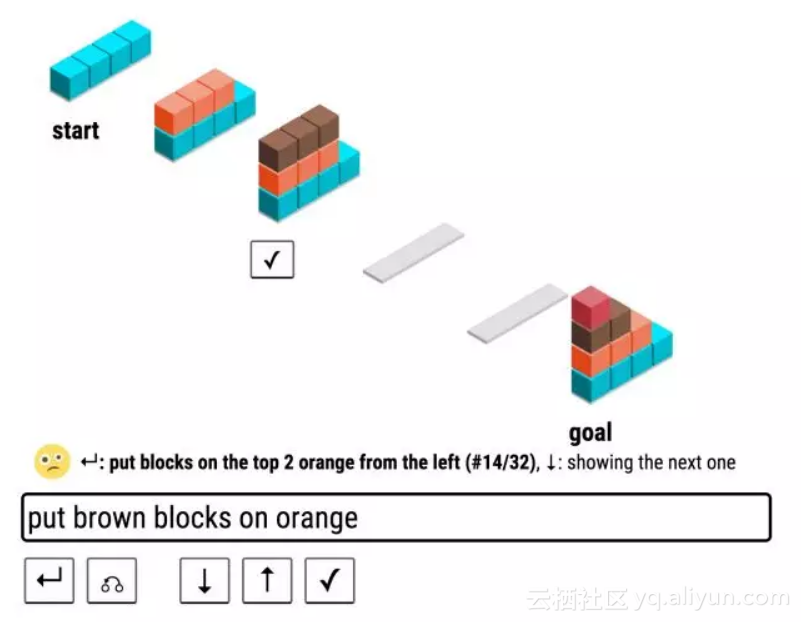
![3f02ee5c2a07643d4f084e24dd41f84b80773e7e]()
▲ 图2. Wang et al. ACL 2016 中的 SHRDLURN 语言游戏:机器需通过与人交互从零开始学习语言。
Percy:的确,我们有很多情况下利用众包或直接让模型与人类交互来学习语言,这是因为从根本上讲,语言是关于与人的交流的。有时候,我觉得这一点在 NLP 社区中是缺失的。现在大部分的工作都是基于大数据的任务——机器翻译、问答、信息提取。这与人类如何通过语言来学习新的知识能力,和完成任务有很大的不同。
我认为,理解语言的目的不是简简单单地模仿人类。而是,如果我们想要建立可以与人类互动的系统,这些系统从根本上需要理解人类是如何思考和行动的,至少是在行为层面上。沟通和语言并不仅仅是关于词语,而是关于词语背后的个体和他们的目标。
香侬科技:正如您在您的网站上提到的,您是一个强烈支持高效和可重复性研究的人。您一直在致力于开发 CodaLab Worksheets,这是可以使研究人员完整记录一个实验从原始数据到最终结果的全过程的平台。您认为在机器学习中可重复性研究的最大障碍是什么?我们应该怎么突破它们?
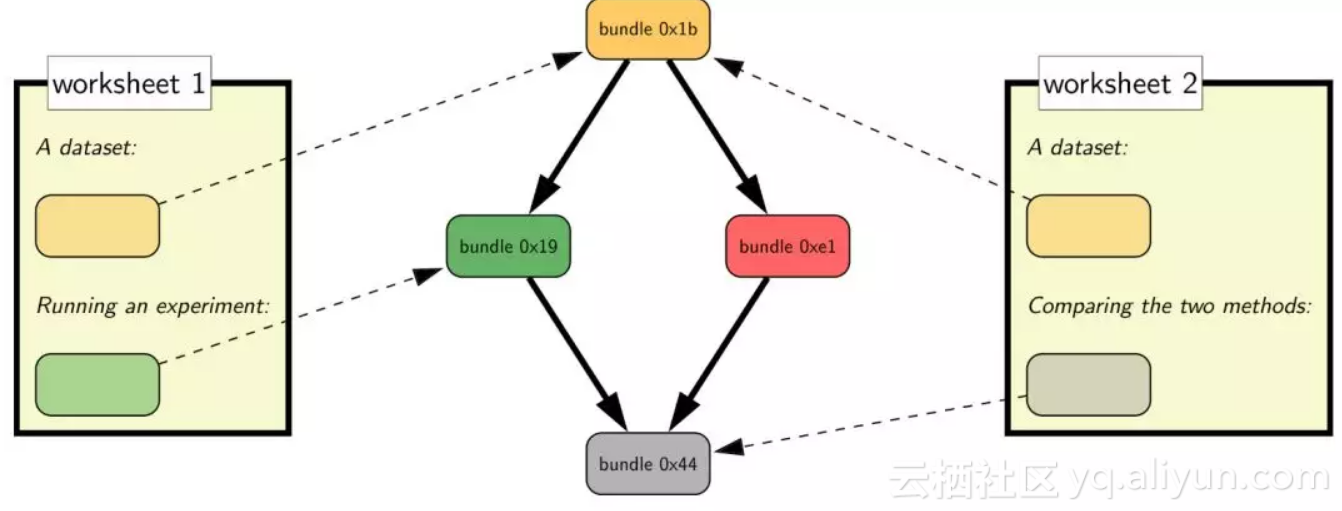
![3ed13093d5a666a48ce8a8f979bd731b9e7c4266]()
▲ 图3. CodaLab工作原理,详见CodaLab官方网站:https://worksheets.codalab.org/
Percy:可重复性在所有科学领域都是一个巨大的问题,人工智能也不例外,虽然我认为作为人工智能研究者,我们真的没有任何借口——这一切只是在数据上跑代码。这个领域确实在开放代码和数据上有了很大的进步,但是往往代码和数据是不足以再现一篇论文的结果的,因为代码是如何运行的可能没有被记录下来。
CodaLab 通过跟踪代码实际执行的整个过程,可以保证最终结果是由该代码和数据产生的。我们试图使 CodaLab 尽可能方便易用——人们可以使用任何编程语言、数据格式等。
然而,挑战仍然存在:人们还没有足够的动力去达到这种程度的可重复性。即使大家都知道,这样其实是更好的,因为存在网络效应——如果每个人都是用 CodaLab 来达到更高的可重复性,那么在别人的工作基础上开发自己的模型就会容易得多,而且研究的速度也会大大加快。我认为这一切只是时间的问题。
香侬科技:在加入斯坦福大学之前,您从加州大学伯克利分校获得博士学位,并在谷歌做过一段时间博士后。作为一个机器学习的研究者,您的思维方式是如何随着时间的推移而改变的?
Percy:当我读博士的时候,我非常喜欢机器学习的建模、算法和分析。但是我意识到即使是很强的算法也是有局限性的:你会看到系统所犯的错误,然后你意识到如果只有一个固定的数据集你可能就是做不出来最完善的算法。后来我在斯坦福大学的时候(也是部分源于我在谷歌的时间的影响),我开始将数据-建模两件事放在一起思考。尽管人们可能认为不存在数据短缺的问题(毕竟,这不是大数据时代吗),事实上,拥有大量的好用的数据仍是一个挑战。
我们已经提出了许多能够改变这一问题的方法(例如,在 Wang et al., ACL 2015 中,我们有一篇论文研究了如何通过让人们改述句子而不是注释逻辑形式的方式来构建语义分析器)。把数据和建模放在一起思考可以拓宽解决方案的各种可能,让你更有创造力。
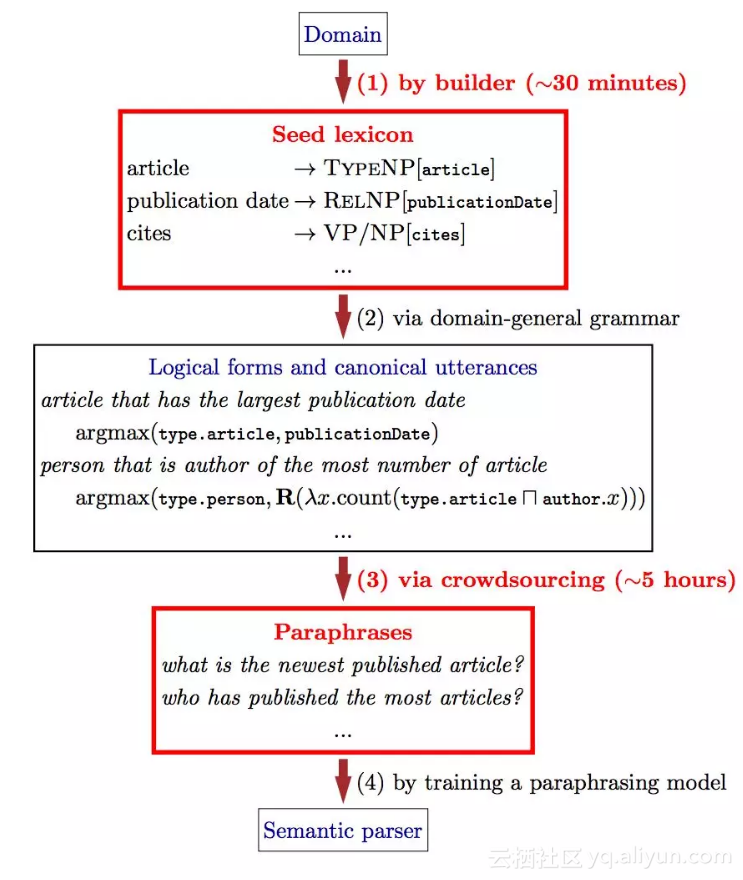
![bf6bc84b824d134bc82023c874c5191190cb3b5c]()
▲ 图4. 通过让人们改述句子而不是注释逻辑形式的方式来快速构建语义分析器 (图片来源于Wang et al., ACL 2015)
香侬科技:作为一个机器学习的研究者,您认为最令人兴奋的是什么事情?
Percy:研究机器学习使你既能思考潜在的数学原理,又能思考如何对社会产生真正的积极影响。
香侬科技:作为一个机器学习的研究者,您认为最令人沮丧的是什么事情?
Percy:有时你只是在黑暗中探险。你看到一个系统的错误,你会做一些试图修复它们的事情,然而并没有什么改进。在某种意义上,当你不理解一个东西的内在机制时,你才会使用机器学习,因为这个东西的机制太复杂了(不然的话你就直接写一个程序了)。
香侬科技:刚进入 NLP 领域的学生来说,该如何培养对于科研项目的品味?
Percy:学习基本原理并广泛阅读,尤其是在 NLP 和 AI 之外,你永远不知道从编程语言、语言学、认知科学、优化、统计学中得到的想法是否与你正在做的事情有关。
人总是很容易被那些很酷炫的模型带偏,会在自己的研究中加入各种华丽复杂的算法——你应该试图做相反的事情:用简单的方法解决问题比用复杂的方法解决问题更令人叹服。
选择一个你心怀信仰的问题,并满怀激情去探索它。你会知道是它,因为它会让你夜不能寐,一直想一直想。把这个问题变成一个属于你的问题,你的私人珍藏。
原文发布时间为:2018-06-12
本文作者:香侬科技
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”。