编者按:本文作者阿里巴巴机器智能技术实验室高级算法工程师张仕良。文章介绍了阿里巴巴的语音识别声学建模新技术: 前馈序列记忆神经网络(DFSMN),目前基于DFSMN的语音识别系统已经在法庭庭审识别、智能客服、视频审核和实时字幕转写、声纹验证、物联网等多个场景成功应用。本次,我们开源了基于Kaldi语音识别工具实现的DFSMN代码,同时开源了相关训练脚本。 通过开源的代码和训练流程,我们在公开的英文数据集LibriSpeech上可以获得目前最好的性能。
This post presents DFSMN, an improved Feedforward Sequential Memory Networks (FSMN) architecture for large vocabulary continuous speech recognition. We release the source codes and training recipes of DFSMN based on the popular Kaldi speech recognition toolkit and demonstrate that DFSMN can achieve the best performance in the LibriSpeech speech recognition task.
Acoustic Modeling in Speech Recognition
Deep neural networks have become the dominant acoustic models in large vocabulary continuous speech recognition systems. Depending on how the networks are connected, there exist various types of neural network architectures, such as feedforward fully-connected neural networks (FNN), convolutional neural networks (CNN) and recurrent neural networks (RNN).
For acoustic modeling, it is crucial to take advantage of the long term dependency within the speech signal. Recurrent neural networks (RNN) are designed to capture long term dependency within the sequential data using a simple mechanism of recurrent feedback. RNNs can learn to model sequential data over an extended period of time and store the memory in the connections, then carry out rather complicated transformations on the sequential data. As opposed to FNNs that can only learn to map a fixed-size input to a fixed-size output, RNNs can in principle learn to map from one variable-length sequence to another. Therefore, RNNs, especially the short term memory (LSTM), have become the most popular choice in acoustic modeling for speech recognition.
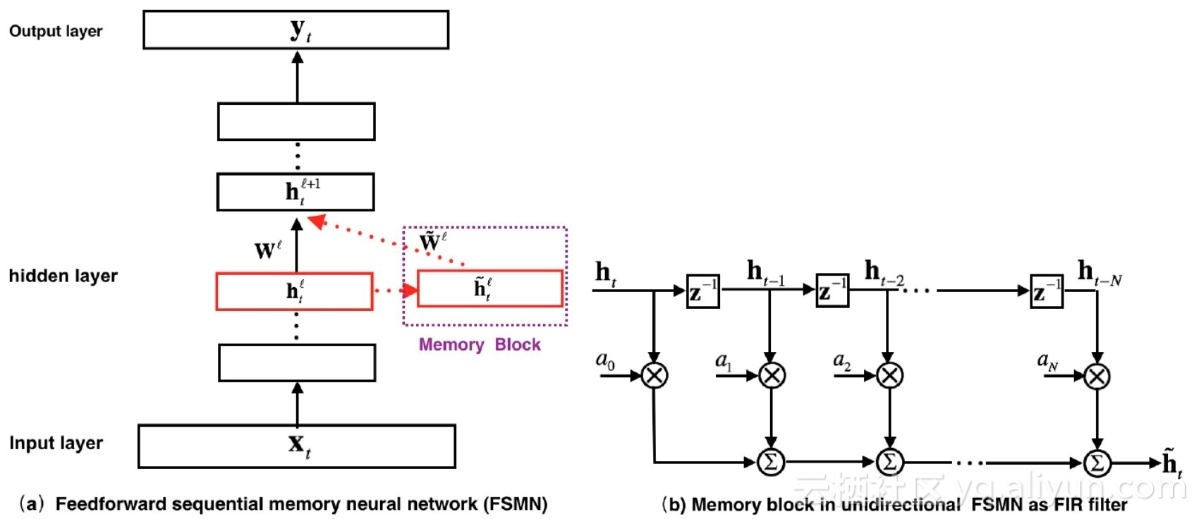
In our previous work, we have proposed a novel neural architecture non-recurrent structure, namely feedforward sequential memory networks (FSMN), which can effectively model long term dependency in sequential data without using any recurrent feedback. FSMN is inspired by the filter design knowledge in digital signal processing that any infinite impulse response (IIR) filter can be well approximated using a high-order finite impulse response (FIR) filter. Because the recurrent layer in RNNs can be conceptually viewed as a first-order IIR filter, it may be precisely approximated by a high-order FIR filter. Therefore, we extend the standard feedforward fully connected neural networks by augmenting some memory blocks, which adopt a tapped-delay line structure as in FIR filters, into the hidden layers. Fig. 1 (a) shows a FSMN with one memory block added into its -th hidden layer and Fig. 1 (b) shows the FIR filter like memory block in FSMN. As a result, the overall FSMN remains as a pure feedforward structure so that it can be learned in a much more efficient and stable way than RNNs. The learnable FIR like memory blocks in FSMNs may be used to encode long context information into a fixed-size representation, which helps the model to capture long-term dependency. Experimental results in the English recognition Switchboard task show that FSMN can outperform the popular BLSTM while faster in training speed.
![88aae00501f4767ee5d39c6d8911df045a667c1e]()
Fig. 1. Illustration of FSMN and its tapped-delay memory block
DFSMN Open Source
![fc37726ef3f2979aca4ef712ecc893df0431db8d]()
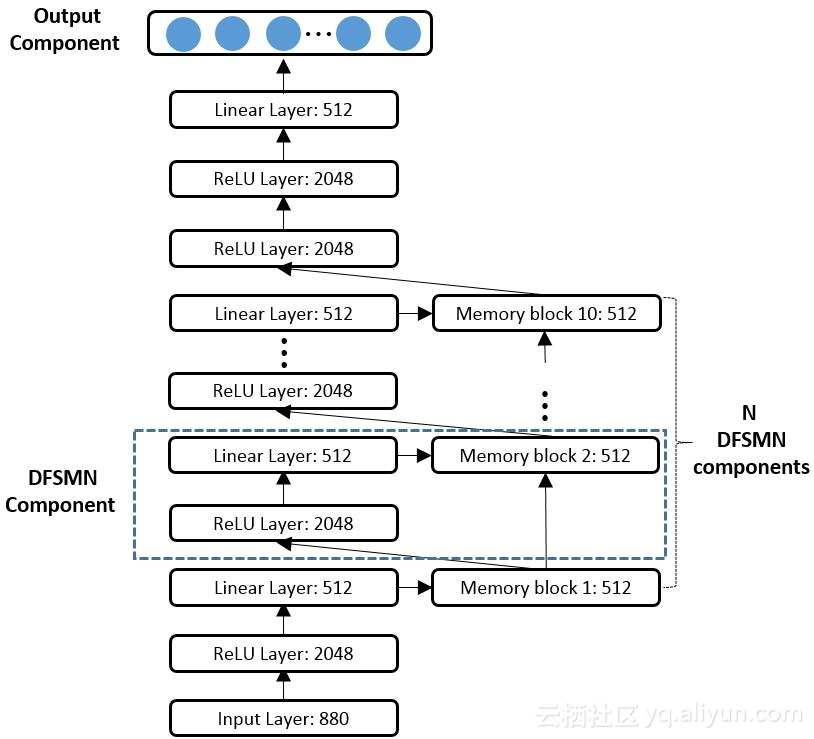
Fig. 2. Illustration of Deep-FSMN (DFSMN) with skip connection
In this work, based on our previous FSMN works and recent works on neural networks with very deep architecture, we present an improved FSMN structure namely Deep-FSMN (DFSMN) (as show in Fig. 2) by introducing skip connections between memory blocks in adjacent layers. These skip connections enable the information flow across different layers and thus alleviate the gradient vanishing problem when building very deep structure. We can successfully build DFSMN with dozens of layers and significantly outperform the previous FSMN.
We implement the DFSMN based on the popular kaldi speech recognition toolkit and release the source code in (https://github.com/tramphero/kaldi). The DFSMN is embedded into the kaldi-nnet1 by adding some DFSMN related components and CUDA kernel functions. We use mini-batch based training instead of the multi-streams which is more stable and efficient.
Improving the State of Art
We have trained the DFSMN in the LibriSpeech corpus, which is a large (1000 hour) corpus of English read speech derived from audiobooks in the LibriVox project, sampled at 16 kHz. We trained DFSMN with two official settings using kaldi recipes: 1) model trained on the “cleaned data” (960-hours-setting); 2) model trained on the speed-perturbed and volume-perturbed “cleaned data” (3000-hours-setting).
For the plain 960-hours-setting, the previous kaldi official release best model is the cross-entropy trained BLSTM. For comparison, we trained the DFSMN with the same front-end processing as well as the decoding configurations as the official-BLSTM using the cross-entropy criterion. The experimental results are as shown in Table 1. For the augmented 3000-hours-setting, the previous best result is achieved by the TDNN trained with lattice-free MMI followed by sMBR based discriminative training. In comparison, we trained DFSMN with cross-entropy followed by one epoch sMBR based discriminative training. The experimental results are as shown in Table 2. For both settings, our DFSMN can achieve the significantly performance improvement compared to the previous best results.
Table 1. Performance (WER in %) of BLSTM and DFSMN trained on cleaned data.
| Model |
Small LM |
|
Large LM |
| Official-BLSTM |
6.85 |
|
5.22 |
| DFSMN |
4.73 |
|
4.36 |
| Relative Gain |
+30.95% |
|
+16.48% |
Table 2. Performance (WER in %) of BLSTM and DFSMN trained on speed-perturbed and volume-perturbed cleaned data.
| Model |
Small LM |
Large LM |
| TDNN |
6.15 |
4.31 |
| DFSMN |
5.10 |
3.96 |
| Relative Gain |
+17.07% |
+8.12% |
How to get our implementation and reproduce our results
We have released two methods to get the implementation and reproduce our results: 1) Github project based on the Kaldi; 2) A PATCH file with the DFSMN related codes and example scripts.
git clone https://github.com/tramphero/kaldi
The PATCH is built based on the Kaldi speech recognition toolkit with commit "04b1f7d6658bc035df93d53cb424edc127fab819". One can apply this PATCH to your own kaldi branch by using the following commands:
#Take a look at what changes are in the patch
git apply --stat Alibaba_MIT_Speech_DFSMN.patch
#Test the patch before you actually apply it
git apply --check Alibaba_MIT_Speech_DFSMN.patch
#If you don’t get any errors, the patch can be applied cleanly.
git am --signoff < Alibaba_MIT_Speech_DFSMN.patch
The training scripts and experimental results for the LibriSpeech task is available at https://github.com/tramphero/kaldi/tree/master/egs/librispeech/s5. There are three DFSMN configurations with different model size: DFSMN_S, DFSMN_M, DFSMN_L.
**********************************************************************************
# ## Training FSMN models on the cleaned-up data
# ## Three configurations of DFSMN with different model size: DFSMN_S, DFSMN_M, DFSMN_L
local/nnet/run_fsmn_ivector.sh DFSMN_S
local/nnet/run_fsmn_ivector.sh DFSMN_M
local/nnet/run_fsmn_ivector.sh DFSMN_L
**********************************************************************************
The DFSMN_S is a small DFSMN with six DFSMN-components while DFSMN_L is a large DFSMN consist of 10 DFSMN-components. For the 960-hours-setting, it takes about 2-3 days to train DFSMN_S only using one M40 GPU. And the detailed experimental results are listed in the RESULTS file.
For more details, take a look at our paper and the open-source project.