1.简介:facenet 是基于 TensorFlow 的人脸识别开源库,有兴趣的同学可以扒扒源代码:https://github.com/davidsandberg/facenet
2.安装和配置 facenet
我们先将 facenet 源代码下载下来:
git clone https://github.com/davidsandberg/facenet.git
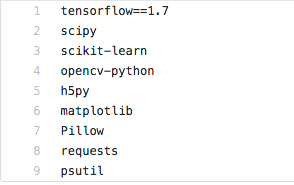
在使用 facenet 前,务必安装下列这些库包:
![]()
或者直接移动到 facenet 目录下,一键安装
pip install -r requirements.txt
3.下载 LFW 数据集
LFW 是由美国马萨诸塞大学阿姆斯特分校计算机视觉实验室整理的。它包含13233张图片,共5749人,其中4096人只有一张图片,1680人的图片多余一张,每张图片尺寸是250x250 。
下载地址:http://vis-www.cs.umass.edu/lfw/ ->Menu->Download->All images as gzipped tar file
下载完成后,我们将文件解压到 facenet/data/lfw_data/lfw 目录下(没有的话自己建个目录),在 lfw_data 目录下新建一个目录 lfw_160,用来存放裁剪后图片。
4.对图像进行预处理
因为程序中神经网络使用的是谷歌的“inception resnet v1”网络模型,这个模型的输入时160*160的图像,而我们下载的LFW数据集是250*250限像素的图像,所以需要进行图片的预处理。
运行 facenet/src/align/align_dataset_mtcnn.py 来修改图片尺寸大小,加入下列参数
facenet/data/lfw_data/lfw #输入图像文件夹
facenet/data/lfw_data/lfw_160 #输出图像文件夹
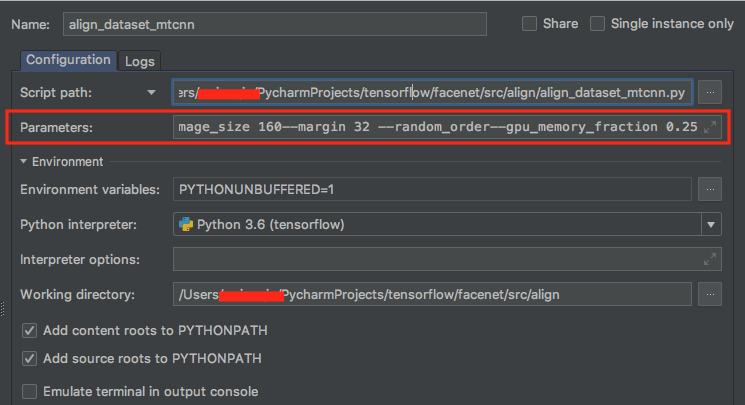
--image_size 160 --margin 32 --random_order--gpu_memory_fraction 0.25 #指定裁剪后图像大小(如果不指定,默认的裁剪结果是182*182像素的)
即
python align_dataset_mtcnn.py facenet/data/lfw_data/lfw facenet/data/lfw_data/lfw_160 --image_size 160 --margin 32 --random_order--gpu_memory_fraction 0.25
如果用的是 pycharm,可以在 RUN -> Edit Configurations 下添加参数信息,然后运行 align_dataset_mtcnn.py 文件:
![]()
**这里自己运行的时候一直报错提示:No module named 'align'
将 align_dataset_mtcnn.py 移动至 src 文件夹下再运行就不会报错了。
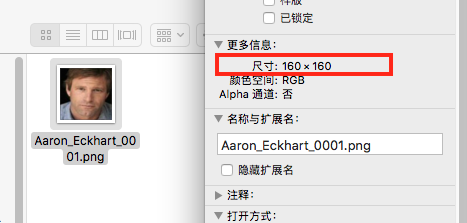
校准后图像大小即变为160 x 160 。
![]()
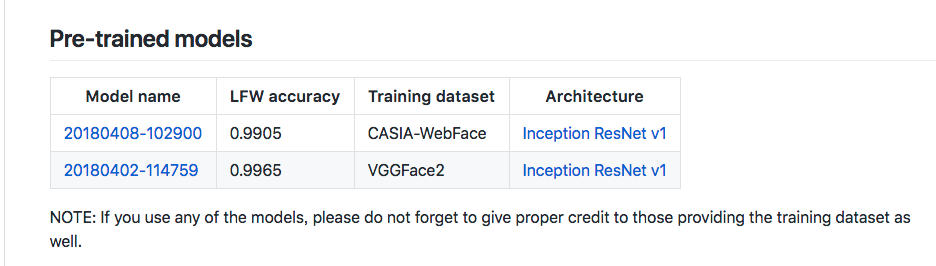
5.评估 Google 预训练模型在数据集中的准确性
facenet提供了两个预训练模型,分别是基于CASIA-WebFace和 VGGFace2人脸库训练的。(由于存储在 Google 网盘中,需要 FQ 下载使用)
GitHub 地址:https://github.com/davidsandberg/facenet
![]()
这里我采用的是 CASIA-WebFace 预训练模型,有兴趣了解的小伙伴,可以到CASIA-WebFace 官网看看:
http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html
将下载好的预训练文件解压到 facenet/src/models目录下:
添加参数
facenet/data/lfw_data/lfw_160 facenet/src/models/20180408-102900
运行 validate_on_lfw.py 文件。
这里我刚开始运行的时候报错:![]()
发现是预训练模型版本太旧,我们在 facenet 上下载最新的CASIA-WebFace 训练库再重新运行即可。
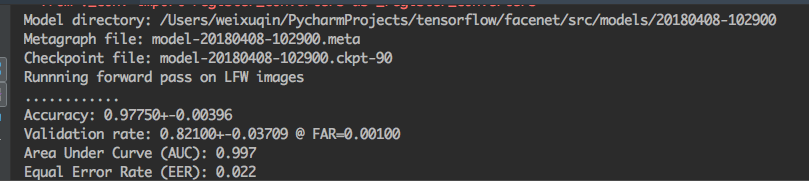
运行结果如下:
![]()
可以看到识别精度可以达到 97.7%,其识别准确度还是非常不错的。
但是程序运行完以后虽然最终运行结果正确,但是最后却还是报了个错误:_2_input_producer: Skipping cancelled enqueue attempt with queue not closed
![]()
原因是主线程已经关闭,但是读取数据入队线程还在执行入队。
由于自己对 TensorFlow 线程还不是特别了解,暂时还没有解决这个问题。