








大数据开发:剖析Hadoop和Spark的Shuffle过程差异
一、前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全量数据,那就必须把相同key的数据汇集到同一个Reduce任务节点来处理,那么Mapreduce范式定义了一个叫做Shuffle的过程来实现这个效果。 二、编写本文的目的 本文旨在剖析Hadoop和Spark的Shuffle过程,并对比两者Shuffle的差异。 三、Hadoop的Shuffle过程 Shuffle描述的是数据从Map端到Reduce端的过程,大数据学习kou群74零零加【41三八yi】大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下: 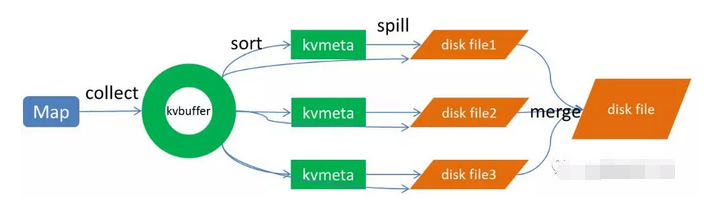 上图的Map的输出的文件被分片为红绿蓝三个分片,这个分片的...