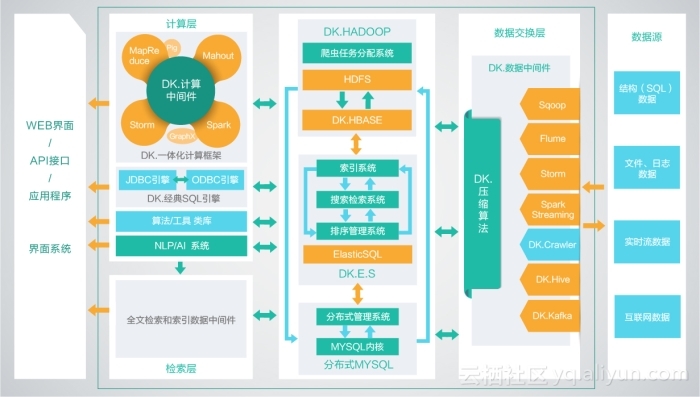

Spark ShuffleDependency Shuffle依赖关系
Spark ShuffleDependency Shuffle依赖关系 Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,the RDD is transient since we don’t need it on the executor side. 更多资源 github: https://github.com/opensourceteams/spark-scala-maven csdn(汇总视频在线看): https://blog.csdn.net/thinktothings/article/details/84726769 youtub视频演示 https://youtu.be/8T6PyHuf_wQ (youtube视频) https://www.bilibili.com/video/av37442139/?p=5 (bilibili视频) github: https://github.com/opensourceteams/spark-scal...