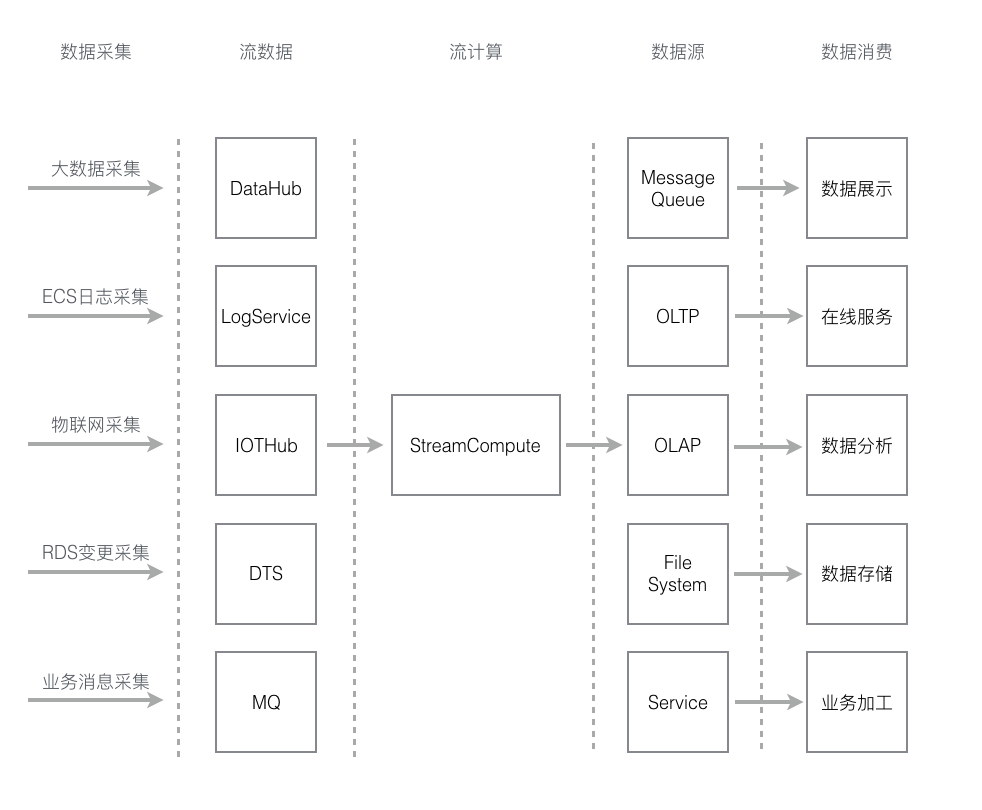
在使用阿里云实时计算 Flink前,对流式数据处理整体全链路有初步的认识可以极大方便您梳理业务流程,制定相应的系统设计方案。下面将简单介绍阿里云实时计算全流程系统架构。
![实时计算 Flink流程图]()
-
数据采集
广义的实时数据采集指: 用户使用流式数据采集工具将数据
实时地采集并传输到大数据Pub/Sub系统,该系统将为下游实时计算提供源源不断的事件源去触发流式计算作业的运行。阿里云大数据生态中提供了诸多针对不同场景领域的流式数据Pub/Sub系统,阿里云实时计算天然集成上图中诸多Pub/Sub系统,以便您可以轻松集成各类流式数据存储系统。
例如:您可以直接使用实时计算对接SLS的LogHub系统,以做到快速集成并使用ECS日志。
-
流式计算
流数据作为实时计算 Flink的触发源驱动实时计算运行。因此,
一个实时计算 Flink作业必须至少使用一个流数据作为数据源。同时,对于一些业务较为复杂的场景,实时计算还支持和静态数据存储进行关联查询。例如:针对每条DataHub流式数据,实时计算将根据流式数据的主键和RDS中数据进行关联查询(即join查询)。同时,阿里云实时计算还支持针对多条数据流进行关联操作,Flink SQL能够支持如阿里巴巴集团大量级的复杂业务。
-
实时数据集成
阿里云实时计算 Flink将计算的结果数据直接写入目的数据存储,从而最大程度降低全链路数据时延,降低数据链路复杂度,保证数据加工的实时性。为了打通阿里云生态,阿里云实时计算 Flink天然集成了OLTP(RDS产品线等)、NoSQL(OTS等)、OLAP(ADS等)、MessageQueue(DataHub、ONS等)、MassiveStorage(OSS、MaxCompute等)。
-
数据消费
流式计算的结果数据进入各类数据存储后,您可以运用个性化的应用操控结果数据: 使用数据存储系统访问数据,使用消息投递系统接受信息,或者使用告警系统生成异常结果数据警报。
数据链路情况
对于上图的数据链路,部分数据存储由于和实时计算 Flink模型不能一一匹配,需要使用其他类型的流数据做中转,说明如下:
-
DataHub
DataHub提供了多类数据(包括日志、数据库BinLog、IoT数据流等等)从其他数据存储上传到DataHub的工具、界面,以及一些开源、商业软件的集成,参看DataHub介绍文档,即可获取丰富多样的数据采集工具信息。
-
日志服务(LogService)
LogService是针对日志类数据的一站式服务,经阿里巴巴集团大量大数据场景锤炼而成。LogService提供了诸多针对日志的采集、消费、投递、查询分析等的功能。
请查看LogService采集方式,了解如何使用日志进行流式数据采集。
-
物联网套件(IoTHub)
物联网套件是阿里云专门为物联网领域的开发人员推出的。其目的是帮助开发者搭建安全性能强大的数据通道,方便终端(如传感器、执行器、嵌入式设备或智能家电等等)和云端的双向通信。 使用IoTHub规则引擎可以将IoT数据方便投递到DataHub,并利用实时计算 Flink和MaxCompute进行数据加工计算。
请查看IoT设置规则引擎,了解如何将IoT数据推送到DataHub。
-
数据传输(DTS)
DTS支持以数据库为核心的结构化存储产品之间的数据传输。它是一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。使用DTS的数据传输功能,可以方便您将RDS等BinLog解析并投递到DataHub,并利用实时计算 Flink和MaxCompute进行数据加工计算。 当前DTS传输到DataHub功能已经上线,欢迎使用。
请查看RDS到DataHub数据实时同步,了解具体步骤。
- MQ
阿里云MQ服务是企业级互联网架构的核心产品,基于高可用分布式集群技术,搭建了包括发布订阅、消息轨迹、资源统计、定时(延时)、监控报警等一套完整的消息云服务。
本文转自实时计算——业务流程