每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点。
移动互联网时代,海量的用户每天产生海量的数量,比如:
以支付宝用户为例,8亿;微信用户更是10亿。订单表更夸张,比如美团外卖,每天都是几千万的订单。淘宝的历史订单总量应该百亿,甚至千亿级别,这些海量数据远不是一张表能Hold住的。事实上MySQL单表可以存储10亿级数据,只是这时候性能比较差,业界公认MySQL单表容量在1KW以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
既然一张表无法搞定,那么就想办法将数据放到多个地方,目前比较普遍的方案有3个:
-
分区;
-
分库分表;
-
NoSQL/NewSQL;
说明:只分库,或者只分表,或者分库分表融合方案都统一认为是分库分表方案,因为分库,或者分表只是一种特殊的分库分表而已。NoSQL比较具有代表性的是MongoDB,es。NewSQL比较具有代表性的是TiDB。
Why Not NoSQL/NewSQL?
首先,为什么不选择第三种方案NoSQL/NewSQL,我认为主要是RDBMS有以下几个优点:
- RDBMS生态完善;
- RDBMS绝对稳定;
- RDBMS的事务特性;
NoSQL/NewSQL作为新生儿,在我们把可靠性当做首要考察对象时,它是无法与RDBMS相提并论的。RDBMS发展几十年,只要有软件的地方,它都是核心存储的首选。
目前绝大部分公司的核心数据都是:以RDBMS存储为主,NoSQL/NewSQL存储为辅!互联网公司又以MySQL为主,国企&银行等不差钱的企业以Oracle/DB2为主!NoSQL/NewSQL宣传的无论多牛逼,就现在各大公司对它的定位,都是RDBMS的补充,而不是取而代之!
Why Not 分区?
我们再看分区表方案。了解这个方案之前,先了解它的原理:
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
事实上,这个方案也不错,它对用户屏蔽了sharding的细节,即使查询条件没有sharding column,它也能正常工作(只是这时候性能一般)。不过它的缺点很明显:很多的资源都受到单机的限制,例如连接数,网络吞吐等!虽然每个分区可以独立存储,但是分区表的总入口还是一个MySQL示例。从而导致它的并发能力非常一般,远远达不到互联网高并发的要求!
至于网上提到的一些其他缺点比如:无法使用外键,不支持全文索引。我认为这都不算缺点,21世纪的项目如果还是使用外键和数据库的全文索引,我都懒得吐槽了!
所以,如果使用分区表,你的业务应该具备如下两个特点:
-
数据不是海量(分区数有限,存储能力就有限);
-
并发能力要求不高;
Why 分库分表?
最后要介绍的就是目前互联网行业处理海量数据的通用方法:分库分表。
虽然大家都是采用分库分表方案来处理海量核心数据,但是还没有一个一统江湖的中间件,笔者这里列举一些有一定知名度的分库分表中间件:
备注:sharding-jdbc的作者张亮大神原来在当当,现在在京东金融。但是sharding-jdbc的版权属于开源社区,不是公司的,也不是张亮个人的!
其他比如网易,58,京东等公司都有自研的中间件。总之各自为战,也可以说是百花齐放。
但是这么多的分库分表中间件全部可以归结为两大类型:
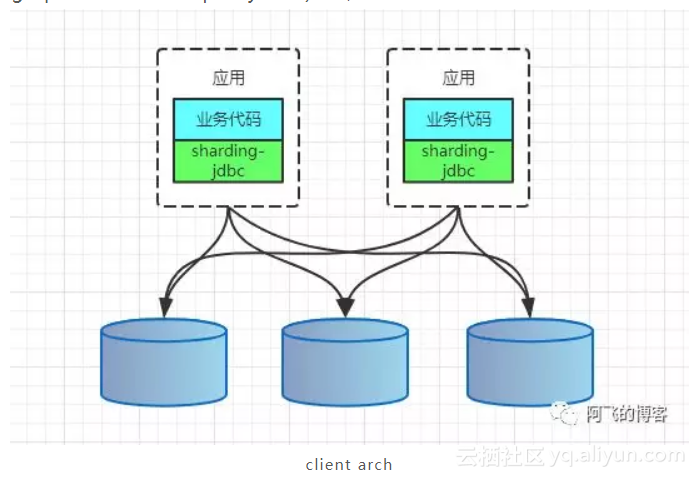
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。架构如下:
![cb19b990885bf0111814cefbf6743b2bec158eaa]()
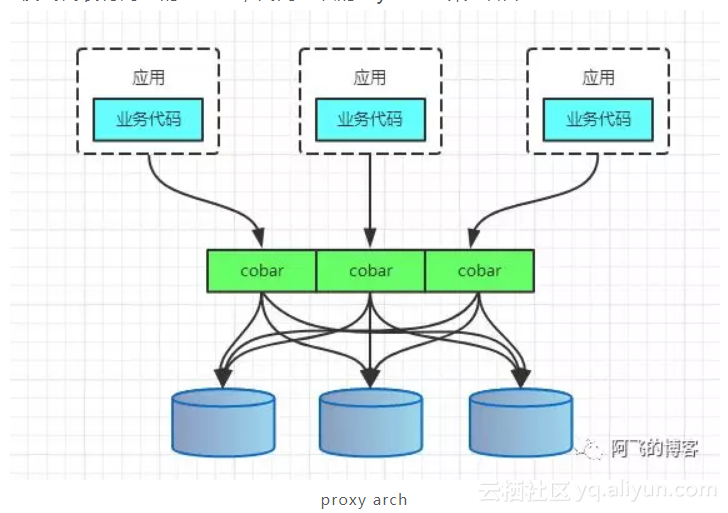
PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下:
![41c35eed0030db88ff112b7e65d6dd25f3e0edb8]()
但是,无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
笔者比较倾向于CLIENT模式,架构简单,性能损耗较小,运维成本低。
接下来,以几个常见的大表为案例,说明分库分表如何落地!
实战案例
分库分表第一步也是最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。而sharding column的选取跟业务强相关,笔者认为选择sharding column的方法最主要分析你的API流量,优先考虑流量大的API,将流量比较大的API对应的SQL提取出来,将这些SQL共同的条件作为sharding column。例如一般的OLTP系统都是对用户提供服务,这些API对应的SQL都有条件用户ID,那么,用户ID就是非常好的sharding column。
这里列举分库分表的几种主要处理思路:
再以几张实际表为例,说明如何分库分表。
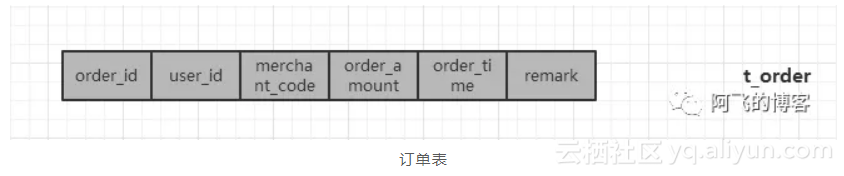
订单表几个核心字段一般如下:
![e3e0fb683c6f944071a2dbd744f7fe4e5318e18d]()
以阿里订单系统为例(参考《企业IT架构转型之道:阿里巴巴中台战略思想与架构实现》),它选择了三个column作为三个独立的sharding column,即:order_id,user_id,merchant_code。user_id和merchant_code就是买家ID和卖家ID,因为阿里的订单系统中买家和卖家的查询流量都比较大,并且查询对实时性要求都很高。而根据order_id进行分库分表,应该是根据order_id的查询也比较多。
这里还有一点需要提及,多个sharding-column的分库分表是冗余全量还是只冗余关系索引表,需要我们自己权衡。
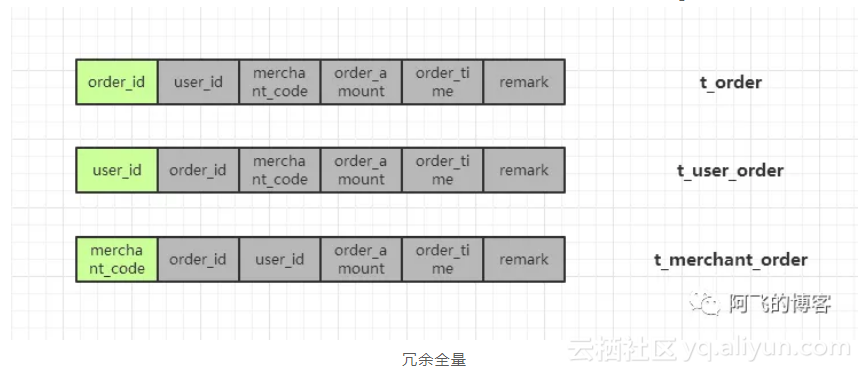
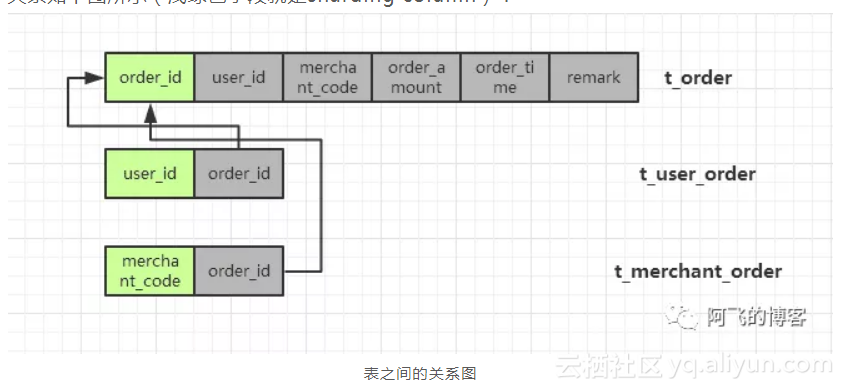
冗余全量的情况如下--每个sharding列对应的表的数据都是全量的,这样做的优点是不需要二次查询,性能更好,缺点是比较浪费存储空间(浅绿色字段就是sharding-column):
![afa235e621afa54b1804fba920cb172417783946]()
冗余关系索引表的情况如下--只有一个sharding column的分库分表的数据是全量的,其他分库分表只是与这个sharding column的关系表,这样做的优点是节省空间,缺点是除了第一个sharding column的查询,其他sharding column的查询都需要二次查询,这三张表的关系如下图所示(浅绿色字段就是sharding column):
![feb94b808252974cc6db43d44bd7f078ee29351e]()
冗余全量表PK.冗余关系表
-
速度对比:冗余全量表速度更快,冗余关系表需要二次查询,即使有引入缓存,还是多一次网络开销;
-
存储成本:冗余全量表需要几倍于冗余关系表的存储成本;
-
维护代价:冗余全量表维护代价更大,涉及到数据变更时,多张表都要进行修改。
总结:选择冗余全量表还是索引关系表,这是一种架构上的trade off,两者的优缺点明显,阿里的订单表是冗余全量表。
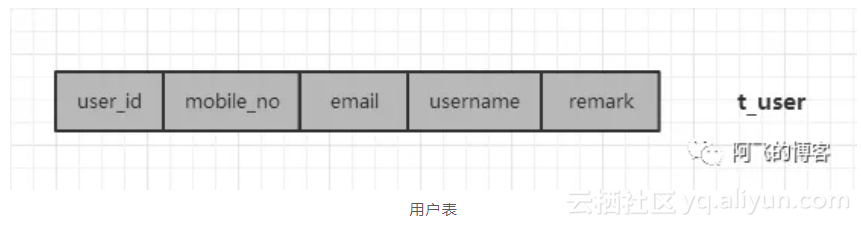
用户表几个核心字段一般如下:
![620e4f9d5a2caca329e9d5f1716175cb5e1f8146]()
一般用户登录场景既可以通过mobile_no,又可以通过email,还可以通过username进行登录。但是一些用户相关的API,又都包含user_id,那么可能需要根据这4个column都进行分库分表,即4个列都是sharding-column。
账户表几个核心字段一般如下:
![09c7ec83874627bfd18482aeadae1f99d89740a6]()
与账户表相关的API,一般条件都有account_no,所以以account_no作为sharding-column即可。
上面提到的都是条件中有sharding column的SQL执行。但是,总有一些查询条件是不包含sharding column的,同时,我们也不可能为了这些请求量并不高的查询,无限制的冗余分库分表。那么这些条件中没有sharding column的SQL怎么处理?以sharding-jdbc为例,有多少个分库分表,就要并发路由到多少个分库分表中执行,然后对结果进行合并。具体如何合并,可以看笔者sharding-jdbc系列文章,有分析源码讲解合并原理。
这种条件查询相对于有sharding column的条件查询性能很明显会下降很多。如果有几十个,甚至上百个分库分表,只要某个表的执行由于某些因素变慢,就会导致整个SQL的执行响应变慢,这非常符合木桶理论。
更有甚者,那些运营系统中的模糊条件查询,或者上十个条件筛选。这种情况下,即使单表都不好创建索引,更不要说分库分表的情况下。那么怎么办呢?这个时候大名鼎鼎的elasticsearch,即es就派上用场了。将分库分表所有数据全量冗余到es中,将那些复杂的查询交给es处理。
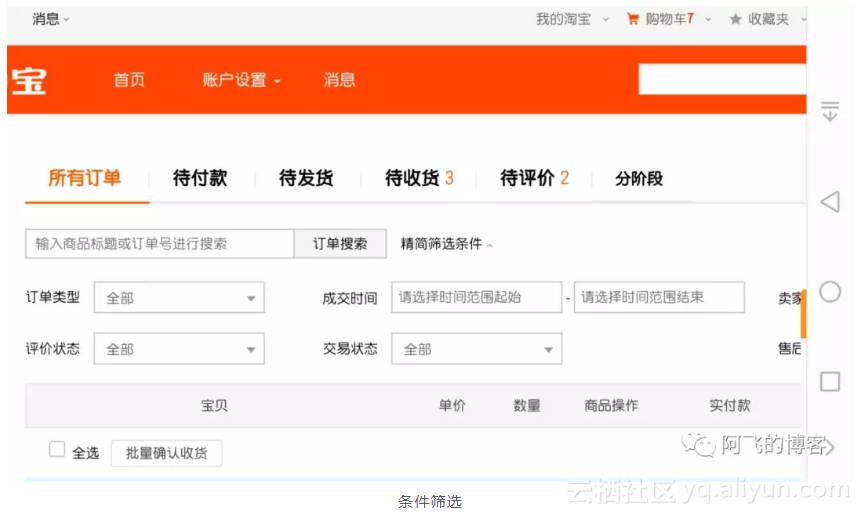
淘宝我的所有订单页面如下,筛选条件有多个,且商品标题可以模糊匹配,这即使是单表都解决不了的问题(索引满足不了这种场景),更不要说分库分表了:
![d3c74a1aca60e57d60a25105d6d0bbad10852107]()
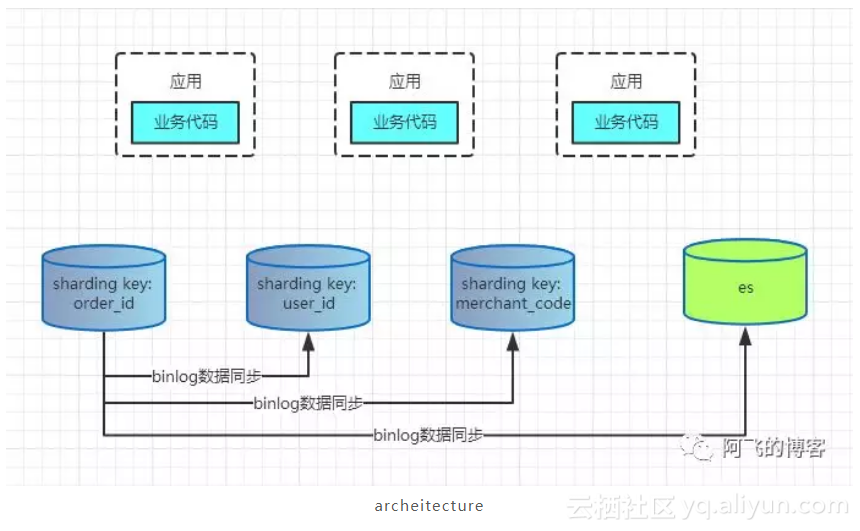
所以,以订单表为例,整个架构如下:
![070e3a08af3b46efc318b222a86853a7bf1c03d7]()
具体情况具体分析:多sharding column不到万不得已的情况下最好不要使用,成本较大,上面提到的用户表笔者就不太建议使用。因为用户表有一个很大的特点就是它的上限是肯定的,即使全球70亿人全是你的用户,这点数据量也不大,所以笔者更建议采用单sharding column + es的模式简化架构。
这里需要提前说明的是,solr+HBase结合的方案在社区中出现的频率可能更高,本篇文章为了保持一致性,所有全文索引方案选型都是es。至于es+HBase和solr+HBase孰优孰劣,或者说es和solr孰优孰劣,不是本文需要讨论的范畴,事实上也没有太多讨论的意义。es和solr本就是两个非常优秀且旗鼓相当的中间件。
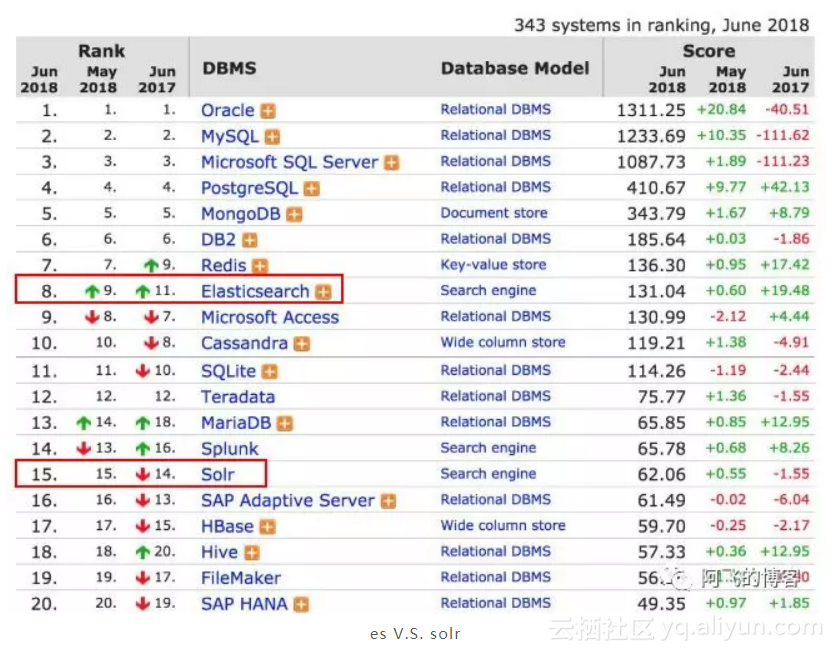
最近几年es更火爆:
![758ede44802c9da0fee72f7f80d988976562b602]()
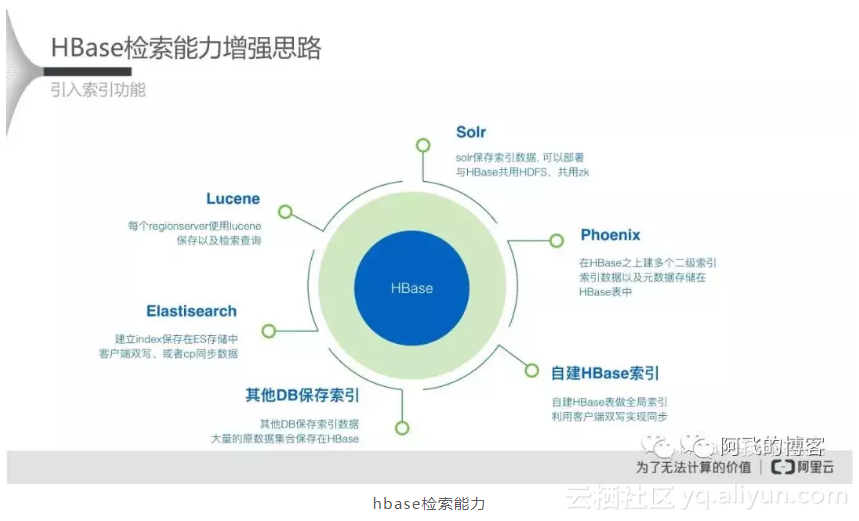
如果抛开选型过程中所有历史包袱,单论es+HBase和solr+HBase的优劣,很明显后者是更好的选择。solr+HBase高度集成,引入索引服务后我们最关心,也是最重要的索引一致性问题,solr+HBase已经有了非常成熟的解决方案一一Lily HBase Indexer。
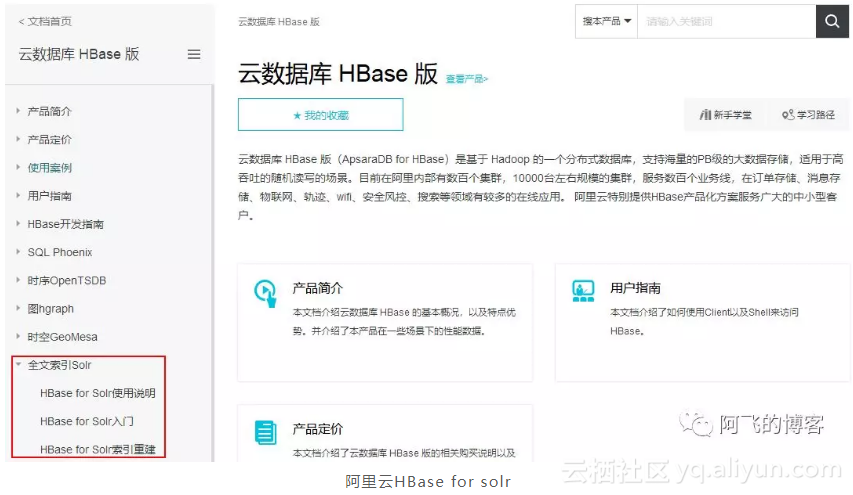
阿里云上的云数据库HBase版也是借助solr实现全文索引。
![31786dad1ca754e360b7ee4a157bb357160e5c08]()
刚刚讨论到上面的以MySQL为核心,分库分表+es的方案,随着数据量越来越来,虽然分库分表可以继续成倍扩容,但是这时候压力又落到了es这里,这个架构也会慢慢暴露出问题!
一般订单表,积分明细表等需要分库分表的核心表都会有好几十列,甚至上百列(假设有50列),但是整个表真正需要参与条件索引的可能就不到10个条件(假设有10列)。这时候把50个列所有字段的数据全量索引到es中,对es集群有很大的压力,后面的es分片故障恢复也会需要很长的时间。
这个时候我们可以考虑减少es的压力,让es集群有限的资源尽可能保存条件检索时最需要的最有价值的数据,即只把可能参与条件检索的字段索引到es中,这样整个es集群压力减少到原来的1/5(核心表50个字段,只有10个字段参与条件),而50个字段的全量数据保存到HBase中,这就是经典的es+HBase组合方案,即索引与数据存储隔离的方案。
Hadoop体系下的HBase存储能力我们都知道是海量的,而且根据它的rowkey查询性能那叫一个快如闪电。而es的多条件检索能力非常强大。这个方案把es和HBase的优点发挥的淋漓尽致,同时又规避了它们的缺点,可以说是一个扬长避免的最佳实践。
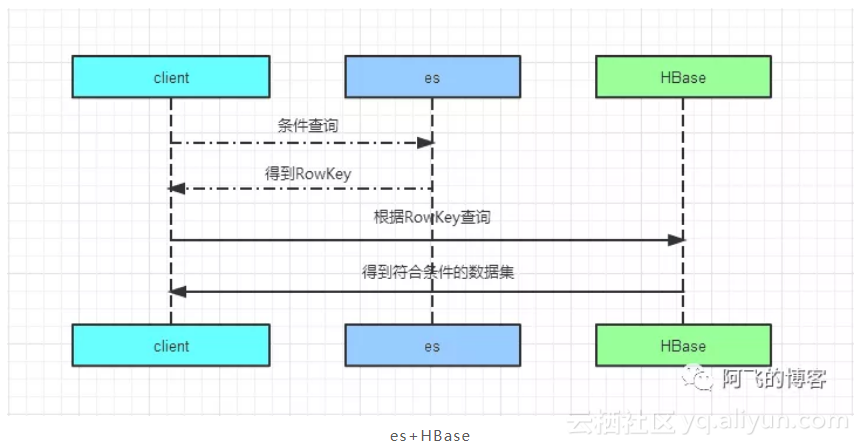
它们之间的交互大概是这样的:先根据用户输入的条件去es查询获取符合过滤条件的rowkey值,然后用rowkey值去HBase查询,后面这一查询步骤的时间几乎可以忽略,因为这是HBase最擅长的场景,交互图如下所示:
![18a9ce6841b48994cc609a5f25651afe0e655de1]()
![cb04f5f353108d46b1afda4fc4bef950ed7e1424]()
图片来源于HBase技术社区-HBase应用实践专场-HBase for Solr
总结
最后,对几种方案总结如下(sharding column简称为sc):
| - |
单个sc |
多个sc |
sc+es |
sc+es+HBase |
| 适用场景 |
单一 |
一般 |
比较广泛 |
非常广泛 |
| 查询及时性 |
及时 |
及时 |
比较及时 |
比较及时 |
| 存储能力 |
一般 |
一般 |
较大 |
海量 |
| 代码成本 |
很小 |
较大 |
一般 |
一般 |
| 架构复杂度 |
简单 |
一般 |
较难 |
非常复杂 |
总之,对于海量数据,且有一定的并发量的分库分表,绝不是引入某一个分库分表中间件就能解决问题,而是一项系统的工程。需要分析整个表相关的业务,让合适的中间件做它最擅长的事情。例如有sharding column的查询走分库分表,一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。
做了这么多事情后,后面还会有很多的工作要做,比如数据同步的一致性问题,还有运行一段时间后,某些表的数据量慢慢达到单表瓶颈,这时候还需要做冷数据迁移。总之,分库分表是一项非常复杂的系统工程。任何海量数据的处理,都不是简单的事情,做好战斗的准备吧!
原文发布时间为:2018-11-08
本文作者:阿飞的博客
本文来自云栖社区合作伙伴“程序猿DD”,了解相关信息可以关注“程序猿DD”。