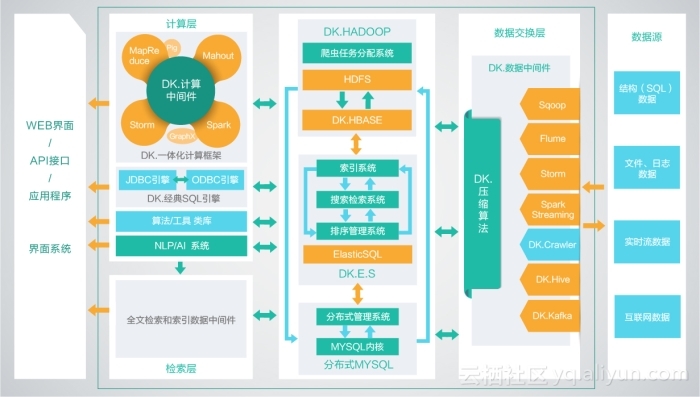
Dkhadoop版本的下载安装以及运行环境搭建等各个方面内容基本都已经分享过了,今天给大家就dkhadoop开发环境安装中常见的问题以及解决方法进行汇总整理,希望对一些朋友有帮助吧!
![a153c8b35a82b43118f2a3d5ab2fe49655e15f0d]()
DKHadoop安装问题整理
1、系统安装
如果没有联网,请手动同步时间
如果联网请同步为中国时区
2、集群免密登录问题
1):主机名一定要区分大小写,否则免密不成功
2):运行sshpass.sh的时候,必须是在/root/下 并且参数是集群密码(如果不是123456请输入自己的密码!!!!!!!!),避免输入错误。
3、MySQL安装问题
1): 如果出现类似:bash “ MySQL ”command not found 就需要运行:
source /etc/profile
2):执行 ./sync的时候 必须输入另一台的IP
4、DKH启动安装
1):如果登录不进去,回忆一下运行changeMaster的时候是不是输入错误。如果输入错误,必须手动修改文件:
vi /root/DKHInstall/webapps/DKH/WEB-INF/classes/dbconfig.properties
vi /root/DKHInstall/webapps/DKH/WEB-INF/classes/wsconfig.properties
将输错的IP更改过来
2):按步骤执行,输入主机名称和IP(安装过程中不要刷新页面!!!)
3):安装需使用火狐浏览器
4):测试平台只提供三台及三台以上五台及五台以下的机器安装。
5、impala安装
1):如果没有联网 impala跳过安装(局域网不算联网!!!!)
2):如果需要impala,并且没有联网 ,请看本地yum源搭建。
6、从节点namenode异常
因为同步元数据忘了启动,在从节点上执行(其中的IP为从节点IP):
ssh root@10.1.56.09
/opt/dkh/Hadoop-2.6.0/sbin/Hadoop-daemon.sh start namenode
7、装系统报错误没有JAVA_HOME
1)每台机器都执行vi /etc/profile
把 export JAVA_HOME= /opt/dkh/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
三条命令加在最下面,保存之后执行命令行:
source /etc/profile
2)执行命令行:
cd /root/install
./installJDK.sh 主机名1 主机名2 主机名3
然后启动tomcat命令行:
cd /root/DKHInstall/bin/
./startup.sh
3)执行vi /opt/dkh/DKM/bin/catalina.sh
export JAVA_HOME= /opt/dkh/jdk1.7.0_79
export JRE_HOME= /opt/dkh/jdk1.7.0_79/jre
把上面两行命令加到第二行 保存
注意每台机器都要改
4)执行 vi /opt/dkh/DkSou/bin/catalina.sh
export JAVA_HOME= /opt/dkh/jdk1.7.0_79
export JRE_HOME= /opt/dkh/jdk1.7.0_79/jre
把上面两行命令加到第二行 保存
注意每台机器都要改
8、启动kafka
/opt/dkh/kafka*/bin/kafka-server-start.sh /usr/local/kafka*/config/server.properties >> /opt/dkh/kafka*/config/kafka-server.log 2>&1 &
注意:这是一条命令, 每台机器上都要运行
9、启动dkm dksou
/opt/dkh/DKM/bin/startup.sh
/opt/dkh/DkSou/bin/startup.sh
每台机器都要执行
10、集群免密问题
执行完集群免密之后要SSH一下,看看集群免密是否操作成功。不成功说明对应关系没写好。