一、前言
二、下载
1.下载地址
https://www.elastic.co/downloads/past-releases
三、单实例安装
直接解压,window下运行 elasticsearch.bat 即可。
四、分布式安装
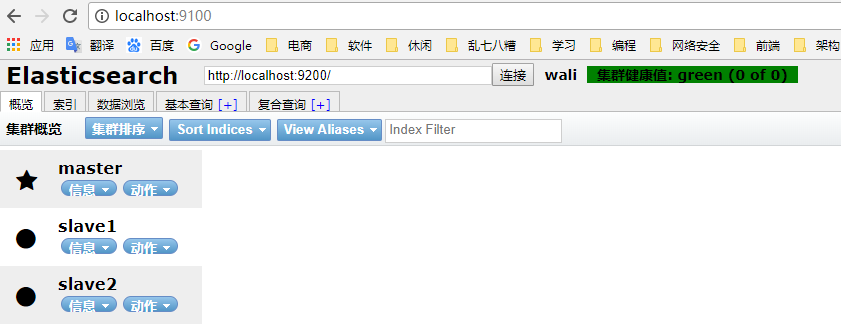
将下载的压缩文件解压成三份,分别重命名为: es-master 、es-slave1 、es-slave2
1.master配置
(1)修改master的 /config/elasticsearch.yml 文件
在文件结尾增加:
# 为了解决es-head插件 js跨域 问题
http.cors.enabled: true
http.cors.allow-origin: "*"
# 设置集群名称
cluster.name: wali
# 设置节点名称
node.name: master
# 指定节点为master节点
node.master: true
network.host: 127.0.0.1
(2)启动master节点(即运行 elasticsearch.bat)
2.slave1 配置
(1)修改slave1的 /config/elasticsearch.yml 文件
在文件结尾增加:
cluster.name: wali
node.name: slave1
network.host: 127.0.0.1
http.port: 8280
# 指定master地址
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
(2)启动master节点
3.slave2节点
(1)修改slave2的 /config/elasticsearch.yml 文件
在文件结尾增加:
cluster.name: wali
node.name: slave2
network.host: 127.0.0.1
http.port: 8000
# 指定master地址
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
(2)启动master节点
五、安装 elasticsearch-head
1.下载地址
https://github.com/mobz/elasticsearch-head
2.安装
将下载的文件解压,然后执行以下命令来下载依赖。(需要安装node.js或者yarn)
npm install
或者
yarn install
3.启动
执行以下命令来启动 elasticsearch-head
npm run start
或者
yarn run start
3.管理页面
启动成功后,即可进入管理页面。管理页面地址为:
如下图,已成功开启了三个节点。
![]()