从3月份到现在2个月过去了,整个数据平台从0到1,算是有了一个基本的样子,跌跌撞撞的勉强支撑起运营的一些基本业务,当然这仅仅是开始,下一步还要从零打造自己的UBS系统,想想都兴奋呢!接下来总结下自己这段时间的得失,以及下一阶段的演化目标。
关于产品架构的原则可以查看这里,我分了两篇来写:
https://www.cnblogs.com/buoge/p/9093096.html
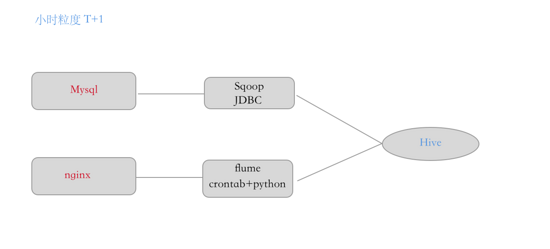
目前的架构方式是这样的:
![大数据平台1.0总结和2.0演化路线]()
从使用Sqoop 定时从MySQL中同步数据,数据量大只能小水管的去fetch每次5-10W条记录,避免数据库压力过大
Flume tailagent 每汇总一小时然后传递logcenter,通过Python过滤后批量的Load到hive中
每日的报表在Hive的基础上会跑一些 MR 的Job, 作为每日的固化查询。
目前的缺点和不足:
问题: 日志读取,Hive入库和完成后删除log日志原始文件没有做完整的事务控制,load失败或是任务失败,原始日志已经删除了,尴尬:sweat:,目前解决方式是保留15天的原始日志
解决方案 :后续引入Kafka的日志回放功能,它有机制保证写入一次后在返回
问题 :各种crontab 飞起没有统一的调度平台,crontab 之间有依赖关系,但是crontab并没有做前后的依赖检查和重试
原因 :数据就我一个人,平台架构和业务要同时搞,老板在后面催没有这么多时间容许我慢慢的搞的这么精细
解决方案 :引入azkaban任务调度平台,统一管理
问题: Hue还没安装,神器不解释了,把各个集群的指标汇总在一起,HDFS,Yarn, MapReduce都能在一个页面直观的看到,而且还有个方便的功能就是Hive的web客户端,不用每次都去终端敲ssh命令,公司网垃圾ssh老是断浪费时间
问题: HDFS数据不能修改,只能删除重建,这里其实更适合日志类的信息,像订单分析和会员分析,需要做增量更新的记录则不合适,就几万条记录需要更新,但是把上亿级别的表删除在重建绝对是有问题的
问题: HDFS 同步有24小时的时间差,这期间线上的订单和会员信息已经发生了百万级别甚至更多的变化,而hadoop集群却没法及时的同步,从Hive出去的报表也不会包含这个空档期间的数据,准确性和实时性有待提高
解决方案 引入Tidb 分布式NewSql解决方案,或是Hbase这类读写和更新更有好的分布式方案,下一步准备先接入Tidb
问题: hive 查询慢,rest api 查询不友好,根据我之前提过的架构原则,适合和简单原则,hive查询慢并不是阻碍我实现业务的主要障碍,慢一些不会有太大关系,但是之前说的数据的增量更新和热数据的实时查询,并配合后续的实时数据流模块,作为流方案的数据落地方案
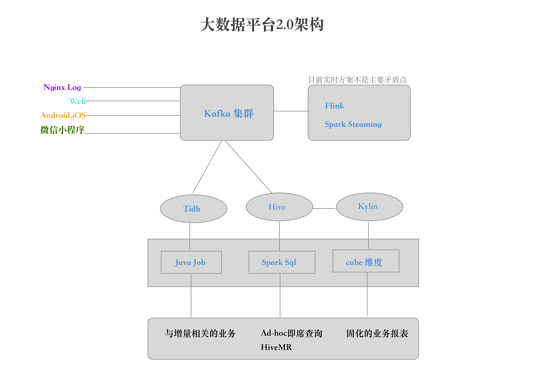
数据平台2.0Lambda架构,离线批处理和实时流方案结合:
![大数据平台1.0总结和2.0演化路线]()
关于大数据3中架构模式的补充
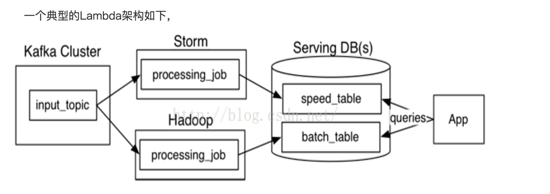
Lambda架构:
![大数据平台1.0总结和2.0演化路线]()
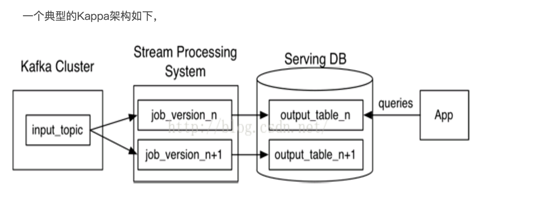
Kappa架构:
![大数据平台1.0总结和2.0演化路线]()
▲图片来源:https://blog.csdn.net/Post_Yuan/article/details/52241252
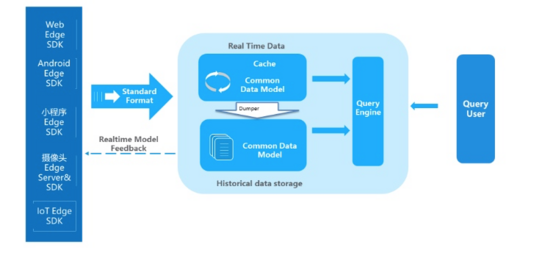
未来的展望,去ETL化的IOTA :
核心是边缘计算,前两个没啥好让人兴奋的反而是边缘计算,让人兴奋,流量剧增,单靠数据局中心肯定会不是一个明智的决定,数据中心的压力会越来越大,期间的高可用,弹性,容错,一致性要求更高,届时数据的规模会倒逼架构走边缘计算的模式,而当下分布式去中心话的计算也是颠覆性的势头
原来由数据中心完成的ETL任务交由业务终端完成,数据中心接受统一格式的CommonModel,大幅度减轻数据中心的ETL, 这种方式固然美好,但是咱们的产品,用户,市场策略是不断变化的,你不知道突然之间要不要换一种什么策略去度量整个产品数据,尽可能的完全的收集,尽可能多的收集没毛病,就像当初的google爬去网页建立自己的索引,后续不断优化自己的搜索算法,而雅虎只是实时爬去后没有存储快照,整个算法调整没有数据的支撑是很难的,当然也是我自己的臆测,到底有去ETL化我不敢肯定,但是去中心化的边缘计算要给1024个赞!
![大数据平台1.0总结和2.0演化路线]()
原文发布时间为:2018-06-6
本文来自云栖社区合作伙伴“IT168”,了解相关信息可以关注“IT168”。