大数据分析和Druid
大数据一直是近年的热点话题,随着数据量的急速增长,数据处理的规模也从GB 级别增长到TB 级别,很多图像应用领域已经开始处理PB 级别的数据分析。大数据的核心目标是提升业务的竞争力,找到一些可以采取行动的洞察(Actionable Insight),数据分析就是其中的核心技术,包括数据收集、处理、建模和分析,最后找到改进业务的方案。
最近一两年,随着大数据分析需求的爆炸性增长,很多公司都经历过将以关系型商用数据库为基础的数据平台,转移到一些开源生态的大数据平台,例如Hadoop 或Spark 平台,以可控的软硬件成本处理更大的数据量。Hadoop 设计之初就是为了批量处理大数据,但数据处理实时性经常是它的弱点。例如,很多时候一个MapReduce 脚本的执行,很难估计需要多长时间才能完成,无法满足很多数据分析师所期望的秒级返回查询结果的分析需求。
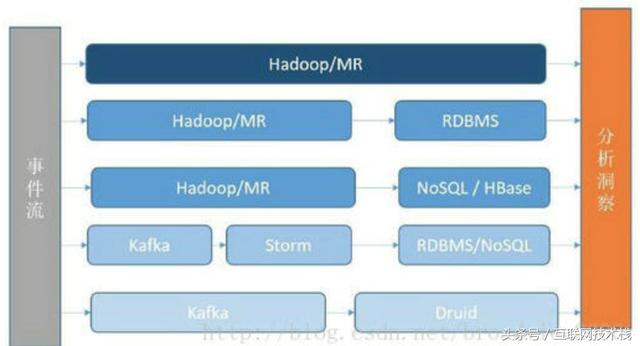
为了解决数据实时性的问题,大部分公司都有一个经历,将数据分析变成更加实时的可交互方案。其中,涉及新软件的引入、数据流的改进等。数据分析的几种常见方法如下图。
整个数据分析的基础架构通常分为以下几类。
(1)使用Hadoop/Spark 的MR 分析。
(2)将Hadoop/Spark 的结果注入RDBMS 中提供实时分析。
(3)将结果注入到容量更大的NoSQL 中,例如HBase 等。
(4)将数据源进行流式处理,对接流式计算框架,如Storm,结果落在RDBMS/NoSQL 中。
(5)将数据源进行流式处理,对接分析数据库,例如Druid、Vertica 等。
Druid 的三个设计原则
在设计之初,开发人员确定了三个设计原则(Design Principle)。
(1)快速查询(Fast Query):部分数据的聚合(Partial Aggregate)+内存化(In-emory)+索引(Index)。
(2)水平扩展能力(Horizontal Scalability):分布式数据(Distributed Data)+ 并行化查询(Parallelizable Query)。
(3)实时分析(Realtime Analytics):不可变的过去,只追加的未来(Immutable Past,Append-Only Future)。
Druid 的技术特点
Druid 具有如下技术特点。
• 数据吞吐量大。
• 支持流式数据摄入和实时。
• 查询灵活且快。
• 社区支持力度大。
Druid 的应用场景
从技术定位上看,Druid 是一个分布式的数据分析平台,在功能上也非常像传统的OLAP系统,但是在实现方式上做了很多聚焦和取舍,为了支持更大的数据量、更灵活的分布式部署、更实时的数据摄入,Druid 舍去了OLAP 查询中比较复杂的操作,例如JOIN 等。相比传统数据库,Druid 是一种时序数据库,按照一定的时间粒度对数据进行聚合,以加快分析查询。
本文选自《Druid实时大数据分析原理与实践》。
欢迎关注 高广超的简书博客 与 收藏文章 !
欢迎关注 头条号:互联网技术栈 !
个人介绍:
高广超:多年一线互联网研发与架构设计经验,擅长设计与落地高可用、高性能、可扩展的互联网架构。
本文首发在 高广超的简书博客 转载请注明!