这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Hadoop 3.x 新特性剖析系列2
1.概述
接着上一篇博客的内容,继续介绍Hadoop3的其他新特性。其内容包含:优化Hadoop Shell脚本、重构Hadoop Client Jar包、支持等待Container、MapReduce任务级别本地优化、支持多个NameNode、部分默认服务端口被改变、支持文件系统连接器、DataNode内部添加负载均衡、重构后台程序和任务堆管理。
2.内容
2.2.1 优化Hadoop Shell脚本
Hadoop Shell脚本已经被重写,用来修复已知的BUG,解决兼容性问题和一些现有安装的更改。它还包含了一些新的特性,内容如下所示:
- 所有Hadoop Shell脚本子系统现在都会执行hadoop-env.sh这个脚本,它允许所有环节变量位于一个位置;
- 守护进程已通过*-daemon.sh选项从*-daemon.sh移动到了bin命令中,在Hadoop3中,我们可以简单的使用守护进程来启动、停止对应的Hadoop系统进程;
- 触发SSH连接操作现在可以在安装时使用PDSH;
- ${HADOOP_CONF_DIR}现在可以任意配置到任何地方;
- 脚本现在测试并报告守护进程启动时日志和进程ID的各种状态;
2.2.2 重构Hadoop Client Jar包
Hadoop2 中可用的Hadoop客户端将Hadoop的传递依赖性拉到Hadoop应用程序的类路径上。如果这些传递依赖项的版本与应用程序使用的版本发送冲突,这可能会产生问题。
因此,在Hadoop3中有新的Hadoop客户端API和Hadoop客户端运行时工件,它们将Hadoop的依赖性遮蔽到单个JAR中,Hadoop客户端API是编译范围,Hadoop客户端运行时是运行时范围,它包含从Hadoop客户端重新定位的第三方依赖关系。因此,你可以将依赖项绑定到JAR中,并测试整个JAR以解决版本冲突。这样避免了将Hadoop的依赖性泄露到应用程序的类路径上。例如,HBase可以用来与Hadoop集群进行数据交互,而不需要看到任何实现依赖。
2.2.3 支持等待容器和分布式调度
在Hadoop3 中引入了一种新型执行类型,即等待容器,即使在调度时集群没有可用的资源,它也可以在NodeManager中被调度执行。在这种情况下,这些容器将在NM中排队等待资源启动,等待荣容器比默认容器优先级低,因此,如果需要,可以抢占默认容器的空间,这样可以提供机器的利用率。如下图所示:
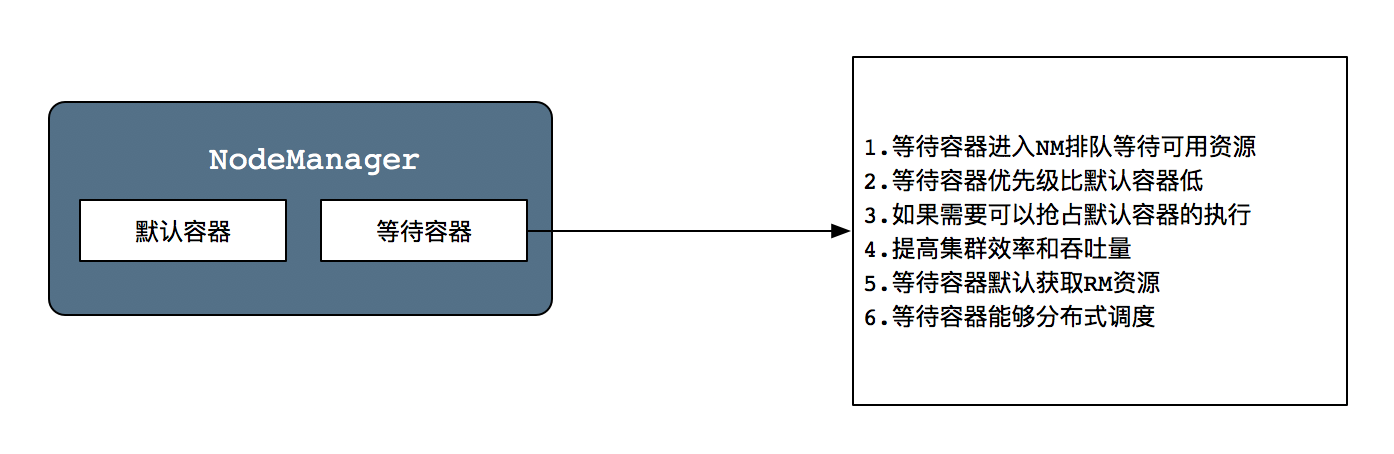
默认容器对于现有的YARN容器,它们由容量调度分配,一旦被调度到节点,就保证有可用的资源使它们执行立即开始。此外,只要没有故障发生,这些容器就可以允许完毕。
等待容器默认由中心RM分配,但还增加了支持以允许等待容器被分布式调度,该调度群被实现于AM和RM协议的拦截器。
2.2.4 MapReduce任务级别本地化优化
在Hadoop3中,本地的Java实现已加入MapReduce地图输出器,对于Shuffle密集的作业,这样可以提高30%或者更高的性能。
它们添加了映射输出收集器的本机实现,让MapTask基于JNI来本机优化。基本思想是添加一个NativeMapOutputCollector收集器来处理映射器发出的键值对,因此Sort、Spill、文件序列化都可以在本机代码中完成。
2.2.5 支持多个NameNode节点
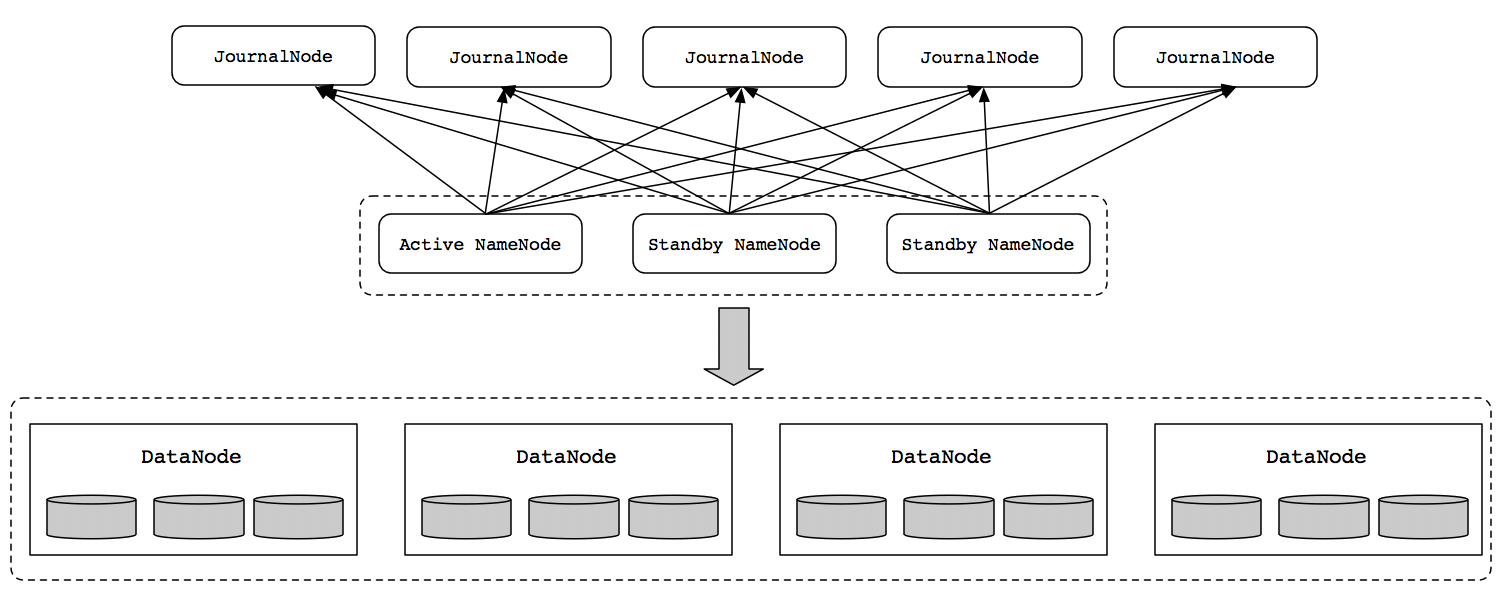
在Hadoop2中,HDFS NameNode高可用体系结构有一个Active和Standby NameNode,通过JournalNodes,该体系结构能够容忍任何一个NameNode失败。
然而,业务关键部署需要更高程度的容错性。因此,在Hadoop3中允许用户运行多个备用的NameNode。例如,通过配置三个NameNode(1个Active NameNode和2个Standby NameNode)和5个JournalNodes节点,集群可以容忍2个NameNode节点故障。如下图所示:
2.2.6 默认的服务端口被修改
早些时候,多个Hadoop服务的默认端口位于Linux端口范围以内。除非客户端程序明确的请求特定的端口号,否则使用的端口号是临时的,因此,在启动时,服务有时会因为与其他另一个应用程序冲突而无法绑定到端口。
因此,具有临时范围冲突端口已经被移除该范围,影响多个服务的端口号,即NameNode、Secondary NameNode、DataNode等如下所示:
| Daemon | App | Hadoop2 Port | Hadoop3 Port |
| NameNode Port | Hadoop HDFS NameNode | 8020 | 9820 |
| Hadoop HDFS NameNode HTTP UI | 50070 | 9870 | |
| Hadoop HDFS NameNode HTTPS UI | 50470 | 9871 | |
| Secondary NameNode Port | Secondary NameNode HTTP | 50091 | 9869 |
| Secondary NameNode HTTP UI | 50090 | 9868 | |
| DataNode Port | Hadoop HDFS DataNode IPC | 50020 | 9867 |
| Hadoop HDFS DataNode | 50010 | 9866 | |
| Hadoop HDFS DataNode HTTP UI | 50075 | 9864 | |
| Hadoop HDFS DataNode HTTPS UI | 50475 | 9865 |
2.2.6 支持文件系统连接器
Hadoop现在支持与微软 Azure数据和阿里云对象存储系统的集成。它可以作为一种替代Hadoop兼容的文件系统,首先添加微软Azure数据,然后添加阿里云对象存储系统。
2.2.7 DataNode内部负载均衡
单个数据节点配置多个数据磁盘,在正常写入操作期间,数据被均匀的划分,因此,磁盘被均匀填充。但是,在维护磁盘时,添加或者替换磁盘会导致DataNode节点存储出现偏移,这种情况在早期的HDFS文件系统中,是没有被处理的。如图下图所示,维护前和维护后不均衡的情况:
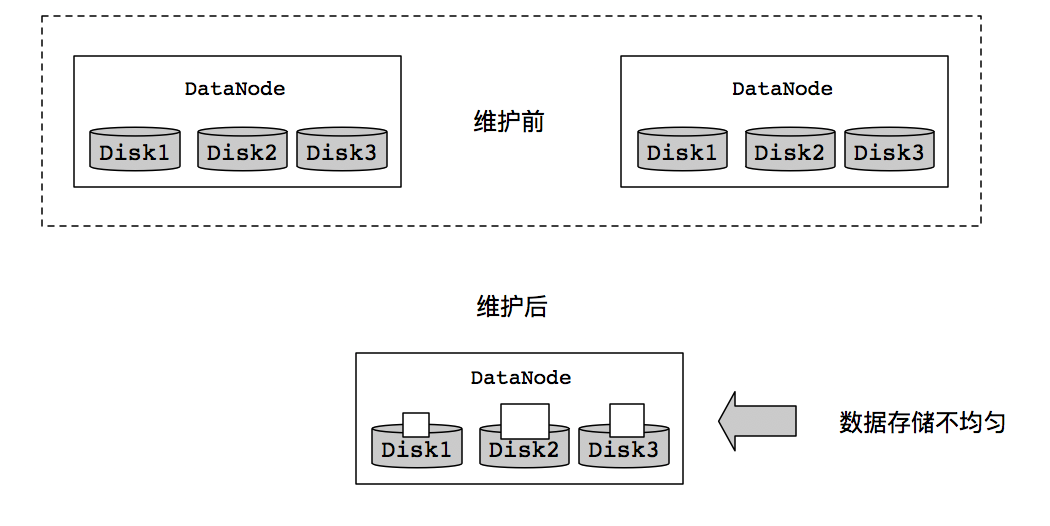
现在Hadoop3通过新的内部DataNode平衡功能来处理这种情况,这是通过hdfs diskbalancer CLI来进行调用的。执行之后,DataNode会进行均衡处理,如下图所示:

2.2.8 重构后台程序和任务堆管理
Hadoop守护进程和MapReduce任务的堆管理已经发生了一系列的变化。
- 配置守护进程堆大小的新方法:值得注意的是,现在可以根据主机的内存大小进行自动调整,并且已经禁止HADOOP_HEAPSIZE变量。在HADOOP\_HEAPSIZE\_MAX 和 HADOOP\_HEAPSIZE\_MIN位置上,分别设置XMX和XMS。所有全局和守护进程特定堆大小变量现在都支持单元。如果变量仅为一个数,它的大小为MB。
- Map和Reduce的堆大小的配置被简化了,所以不再需要任务配置作为一个Java选项指定。已经指定的两个现有配置不受此更改的影响。
3.总结
Hadoop3的这些新特性还是很吸引人的,目前官方推出的稳定版本是2.9.0,发行版是3.1.0,感兴趣的同学可以下载Hadoop3去体验调研学习一下这些新特性。
4.结束语
联系方式:
邮箱:smartloli.org@gmail.com
Twitter: https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1): 424769183
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
邮箱:smartloli.org@gmail.com
Twitter: https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1): 424769183
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
热爱生活,享受编程,与君共勉!

微信关注我们
原文链接:https://yq.aliyun.com/articles/644144
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
相关文章
发表评论
资源下载
更多资源腾讯云软件源
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
手机查看
扫码在手机上查看文章
扫描二维码,手机阅读更方便
热门标签
欢迎您来访!
登录后,您将获得更多功能!
第三方登录
热门文章
联系我们
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273