HDFS上不适合存储小文件,因为如果有很多的小文件,上传到HDFS集群,每个文件都会对应一个block块,一个block块的大小默认是128M,对于很多的小文件来说占用了非常多的block数量,就会影响到内存的消耗,
MapReduce处理这些文件的话也是需要很多的Map来处理.
HDFS提供的小文件的解决方案可以使用SequenceFile和MapFile:
如果存在大量的小数据文件,可以使用SequenceFile.
同时使用SequenceFile还可以用SequenceFile自带的一些压缩算法来减少这些细小文件的占用空间.
1.使用SequenceFile相关代码把本地Windows上的很多小文件上传到HDFS集群.
![复制代码]()
1 package seq;
2
3 import java.io.File;
4 import java.net.URI;
5
6 import org.apache.commons.io.FileUtils;
7 import org.apache.hadoop.conf.Configuration;
8 import org.apache.hadoop.fs.FileSystem;
9 import org.apache.hadoop.fs.Path;
10 import org.apache.hadoop.io.BytesWritable;
11 import org.apache.hadoop.io.SequenceFile;
12 import org.apache.hadoop.io.Text;
13
14 public class Test2 {
15 public static void main(String[] args) throws Exception {
16 Configuration conf = new Configuration();
17 org.apache.hadoop.fs.FileSystem fs = FileSystem.newInstance(new URI("hdfs://crxy99:9000"),conf);
18 Path out = new Path("/members.seq");//输出到HDFS的根目录下"/" 文件命名为memebers.seq
19 SequenceFile.Writer writer = new SequenceFile.Writer(fs, conf, out, Text.class, BytesWritable.class);//文件名作为key 类型是Text 文件内容作为值上传上去,类型是BytesWritable
20
21 File localDir = new File("F:\\360Downloads\\crxy\\video\\2016-05-10【mapreduce】 - 副本\\members2000");
22 for (File file : localDir.listFiles()) {
23 Text key = new Text(file.getName());
24 BytesWritable val = new BytesWritable(FileUtils.readFileToByteArray(file));
25 writer.append(key, val);
26 System.out.println(file.getName());
27 }
28 writer.close();
29 }
30 }
![复制代码]()
程序运行之后查看HDFS目录:
![]()
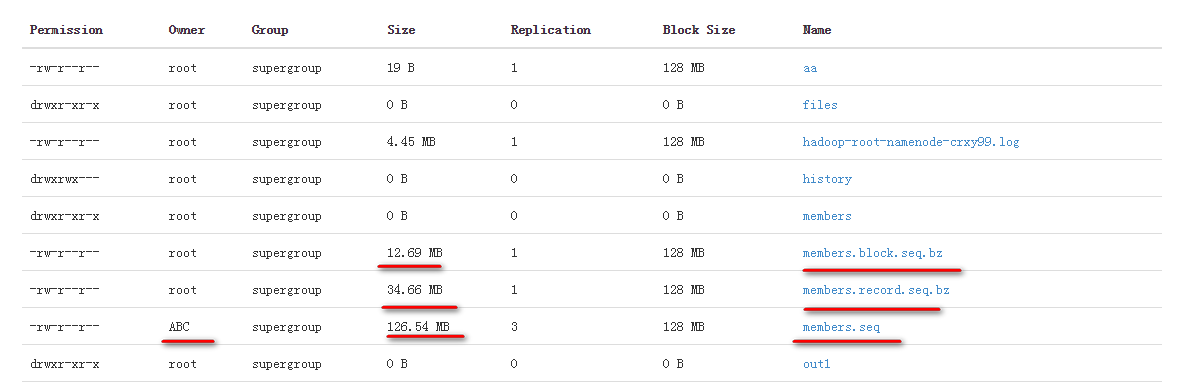
通过Web浏览HDFS集群可以看到members.seq文件的大小是126.54MB....只占用一个block.
上传的是一个在Windows本地的members的文件. Windows本地用户是ABC.
2.使用SequenceFile的block和record压缩算法进行上传文件的相关代码:
![复制代码]()
1 import java.io.File;
2 import java.net.URI;
3
4 import org.apache.commons.io.FileUtils;
5 import org.apache.hadoop.conf.Configuration;
6 import org.apache.hadoop.fs.FSDataOutputStream;
7 import org.apache.hadoop.fs.FileSystem;
8 import org.apache.hadoop.fs.Path;
9 import org.apache.hadoop.io.BytesWritable;
10 import org.apache.hadoop.io.IOUtils;
11 import org.apache.hadoop.io.SequenceFile;
12 import org.apache.hadoop.io.SequenceFile.CompressionType;
13 import org.apache.hadoop.io.Text;
14 import org.apache.hadoop.io.compress.GzipCodec;
15
16 public class Test1 {
17 public static void main(String[] args) throws Exception {
18 Configuration conf = new Configuration();
19 org.apache.hadoop.fs.FileSystem fs = FileSystem.newInstance(new URI("hdfs://crxy99:9000"),conf);
20 CompressionType type = null;
21 if("record".equals(args[0])){
22 type = CompressionType.RECORD;
23 }
24 if("block".equals(args[0])){
25 type = CompressionType.BLOCK;
26 }
27 FSDataOutputStream out = fs.create(new Path(args[1]));
28 SequenceFile.Writer writer = SequenceFile.createWriter(conf, out, Text.class, BytesWritable.class,type,new GzipCodec());
29
30 File localDir = new File("/usr/local/hadoop_repo/files/members2000");
31 for (File file : localDir.listFiles()) {
32 Text key = new Text(file.getName());
33 BytesWritable val = new BytesWritable(FileUtils.readFileToByteArray(file));
34 writer.append(key, val);
35 System.out.println(file.getName());
36 }
37 writer.close();
38 IOUtils.closeStream(out);
39 }
40 }
![复制代码]()
结果仍然如上图,文件占用的空间更小.
本文转自SummerChill博客园博客,原文链接:http://www.cnblogs.com/DreamDrive/p/5500112.html,如需转载请自行联系原作者